 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Automata-based constraints for language model decoding
Jul 11, 2024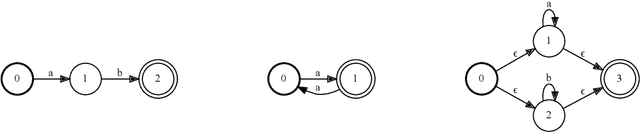



LMs are often expected to generate strings in some formal language; for example, structured data, API calls, or code snippets. Although LMs can be tuned to improve their adherence to formal syntax, this does not guarantee conformance, especially with smaller LMs suitable for large-scale deployment. In addition, tuning requires significant resources, making it impractical for uncommon or task-specific formats. To prevent downstream parsing errors we would ideally constrain the LM to only produce valid output, but this is severely complicated by tokenization, which is typically both ambiguous and misaligned with the formal grammar. We solve these issues through the application of automata theory, deriving an efficient closed-form solution for the regular languages, a broad class of formal languages with many practical applications, including API calls or schema-guided JSON and YAML. We also discuss pragmatic extensions for coping with the issue of high branching factor. Finally, we extend our techniques to deterministic context-free languages, which similarly admit an efficient closed-form solution. In spite of its flexibility and representative power, our approach only requires access to per-token decoding logits and lowers into simple calculations that are independent of LM size, making it both efficient and easy to apply to almost any LM architecture.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention
Dec 04, 2023



We present Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT): a new paradigm for addressing the emerging challenge of scaling up Robotics Transformers (RT) for on-robot deployment. SARA-RT relies on the new method of fine-tuning proposed by us, called up-training. It converts pre-trained or already fine-tuned Transformer-based robotic policies of quadratic time complexity (including massive billion-parameter vision-language-action models or VLAs), into their efficient linear-attention counterparts maintaining high quality. We demonstrate the effectiveness of SARA-RT by speeding up: (a) the class of recently introduced RT-2 models, the first VLA robotic policies pre-trained on internet-scale data, as well as (b) Point Cloud Transformer (PCT) robotic policies operating on large point clouds. We complement our results with the rigorous mathematical analysis providing deeper insight into the phenomenon of SARA.
UT5: Pretraining Non autoregressive T5 with unrolled denoising
Nov 14, 2023Recent advances in Transformer-based Large Language Models have made great strides in natural language generation. However, to decode K tokens, an autoregressive model needs K sequential forward passes, which may be a performance bottleneck for large language models. Many non-autoregressive (NAR) research are aiming to address this sequentiality bottleneck, albeit many have focused on a dedicated architecture in supervised benchmarks. In this work, we studied unsupervised pretraining for non auto-regressive T5 models via unrolled denoising and shown its SoTA results in downstream generation tasks such as SQuAD question generation and XSum.
Non-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling
Oct 18, 2023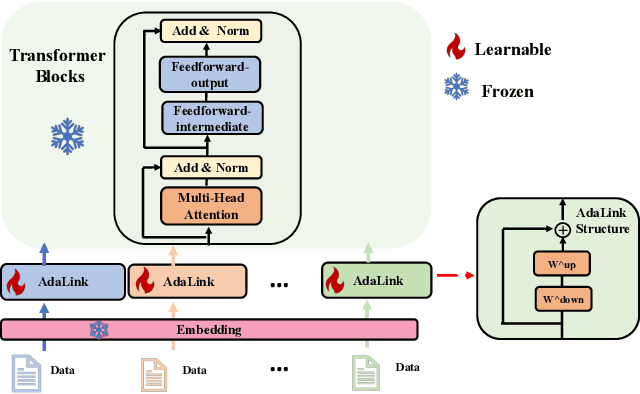



Large language models (LLMs) and vision language models (VLMs) demonstrate excellent performance on a wide range of tasks by scaling up parameter counts from O(10^9) to O(10^{12}) levels and further beyond. These large scales make it impossible to adapt and deploy fully specialized models given a task of interest. Parameter-efficient fine-tuning (PEFT) emerges as a promising direction to tackle the adaptation and serving challenges for such large models. We categorize PEFT techniques into two types: intrusive and non-intrusive. Intrusive PEFT techniques directly change a model's internal architecture. Though more flexible, they introduce significant complexities for training and serving. Non-intrusive PEFT techniques leave the internal architecture unchanged and only adapt model-external parameters, such as embeddings for input. In this work, we describe AdaLink as a non-intrusive PEFT technique that achieves competitive performance compared to SoTA intrusive PEFT (LoRA) and full model fine-tuning (FT) on various tasks. We evaluate using both text-only and multimodal tasks, with experiments that account for both parameter-count scaling and training regime (with and without instruction tuning).
Using Foundation Models to Detect Policy Violations with Minimal Supervision
Jun 09, 2023Foundation models, i.e. large neural networks pre-trained on large text corpora, have revolutionized NLP. They can be instructed directly (e.g. (arXiv:2005.14165)) - this is called hard prompting - and they can be tuned using very little data (e.g. (arXiv:2104.08691)) - this technique is called soft prompting. We seek to leverage their capabilities to detect policy violations. Our contributions are: We identify a hard prompt that adapts chain-of-thought prompting to policy violation tasks. This prompt produces policy violation classifications, along with extractive explanations that justify the classification. We compose the hard-prompts with soft prompt tuning to produce a classifier that attains high accuracy with very little supervision; the same classifier also produces explanations. Though the supervision only acts on the classifications, we find that the modified explanations remain consistent with the (tuned) model's response. Along the way, we identify several unintuitive aspects of foundation models. For instance, adding an example from a specific class can actually reduce predictions of that class, and separately, the effects of tokenization on scoring etc. Based on our technical results, we identify a simple workflow for product teams to quickly develop effective policy violation detectors.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Gradient-Based Automated Iterative Recovery for Parameter-Efficient Tuning
Feb 13, 2023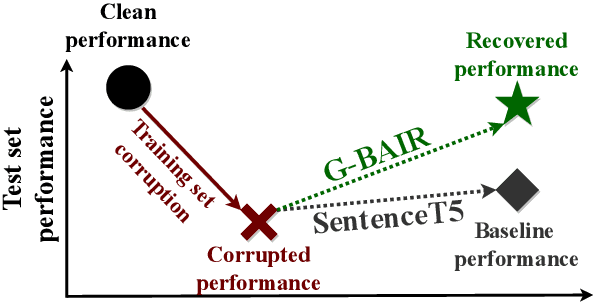

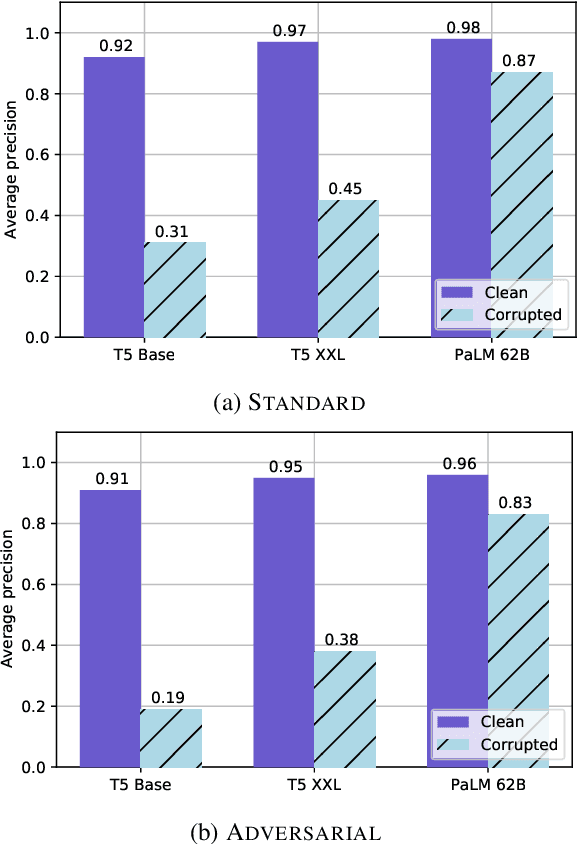
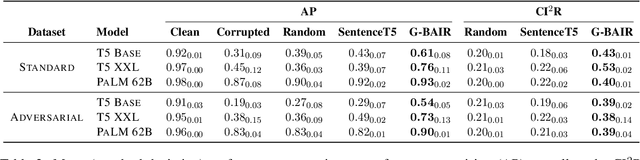
Pretrained large language models (LLMs) are able to solve a wide variety of tasks through transfer learning. Various explainability methods have been developed to investigate their decision making process. TracIn (Pruthi et al., 2020) is one such gradient-based method which explains model inferences based on the influence of training examples. In this paper, we explore the use of TracIn to improve model performance in the parameter-efficient tuning (PET) setting. We develop conversational safety classifiers via the prompt-tuning PET method and show how the unique characteristics of the PET regime enable TracIn to identify the cause for certain misclassifications by LLMs. We develop a new methodology for using gradient-based explainability techniques to improve model performance, G-BAIR: gradient-based automated iterative recovery. We show that G-BAIR can recover LLM performance on benchmarks after manually corrupting training labels. This suggests that influence methods like TracIn can be used to automatically perform data cleaning, and introduces the potential for interactive debugging and relabeling for PET-based transfer learning methods.