 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Private Matrix Factorization with Public Item Features
Sep 17, 2023



We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
Using Foundation Models to Detect Policy Violations with Minimal Supervision
Jun 09, 2023Foundation models, i.e. large neural networks pre-trained on large text corpora, have revolutionized NLP. They can be instructed directly (e.g. (arXiv:2005.14165)) - this is called hard prompting - and they can be tuned using very little data (e.g. (arXiv:2104.08691)) - this technique is called soft prompting. We seek to leverage their capabilities to detect policy violations. Our contributions are: We identify a hard prompt that adapts chain-of-thought prompting to policy violation tasks. This prompt produces policy violation classifications, along with extractive explanations that justify the classification. We compose the hard-prompts with soft prompt tuning to produce a classifier that attains high accuracy with very little supervision; the same classifier also produces explanations. Though the supervision only acts on the classifications, we find that the modified explanations remain consistent with the (tuned) model's response. Along the way, we identify several unintuitive aspects of foundation models. For instance, adding an example from a specific class can actually reduce predictions of that class, and separately, the effects of tokenization on scoring etc. Based on our technical results, we identify a simple workflow for product teams to quickly develop effective policy violation detectors.
Multi-Task Differential Privacy Under Distribution Skew
Feb 15, 2023
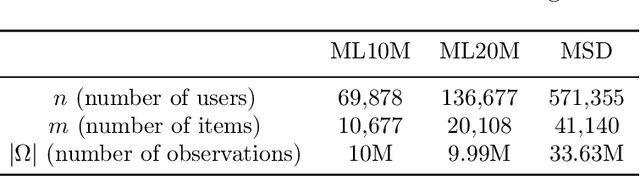


We study the problem of multi-task learning under user-level differential privacy, in which $n$ users contribute data to $m$ tasks, each involving a subset of users. One important aspect of the problem, that can significantly impact quality, is the distribution skew among tasks. Certain tasks may have much fewer data samples than others, making them more susceptible to the noise added for privacy. It is natural to ask whether algorithms can adapt to this skew to improve the overall utility. We give a systematic analysis of the problem, by studying how to optimally allocate a user's privacy budget among tasks. We propose a generic algorithm, based on an adaptive reweighting of the empirical loss, and show that when there is task distribution skew, this gives a quantifiable improvement of excess empirical risk. Experimental studies on recommendation problems that exhibit a long tail of small tasks, demonstrate that our methods significantly improve utility, achieving the state of the art on two standard benchmarks.
Attributing AUC-ROC to Analyze Binary Classifier Performance
May 24, 2022
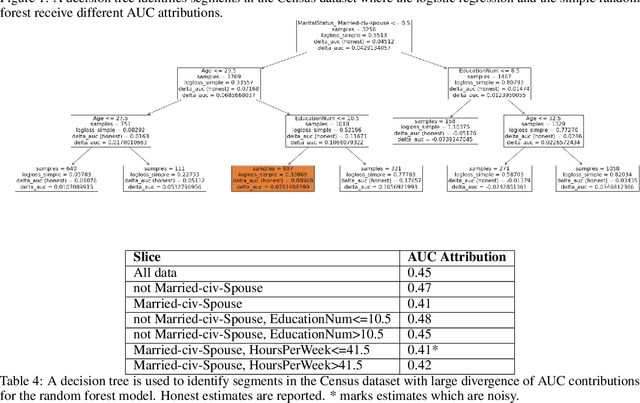
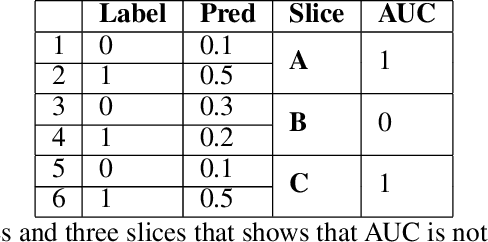
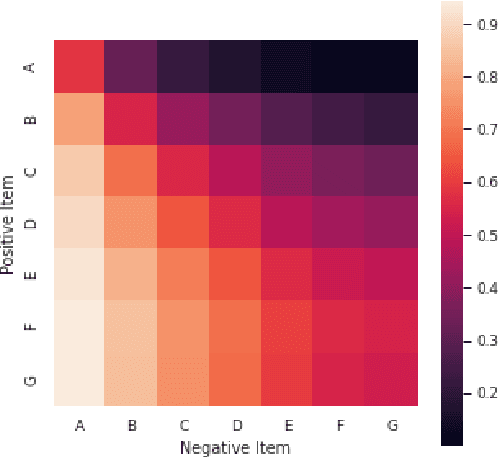
Area Under the Receiver Operating Characteristic Curve (AUC-ROC) is a popular evaluation metric for binary classifiers. In this paper, we discuss techniques to segment the AUC-ROC along human-interpretable dimensions. AUC-ROC is not an additive/linear function over the data samples, therefore such segmenting the overall AUC-ROC is different from tabulating the AUC-ROC of data segments. To segment the overall AUC-ROC, we must first solve an \emph{attribution} problem to identify credit for individual examples. We observe that AUC-ROC, though non-linear over examples, is linear over \emph{pairs} of examples. This observation leads to a simple, efficient attribution technique for examples (example attributions), and for pairs of examples (pair attributions). We automatically slice these attributions using decision trees by making the tree predict the attributions; we use the notion of honest estimates along with a t-test to mitigate false discovery. Our experiments with the method show that an inferior model can outperform a superior model (trained to optimize a different training objective) on the inferior model's own training objective, a manifestation of Goodhart's Law. In contrast, AUC attributions enable a reasonable comparison. Example attributions can be used to slice this comparison. Pair attributions are used to categorize pairs of items -- one positively labeled and one negatively -- that the model has trouble separating. These categories identify the decision boundary of the classifier and the headroom to improve AUC.
First is Better Than Last for Training Data Influence
Feb 24, 2022
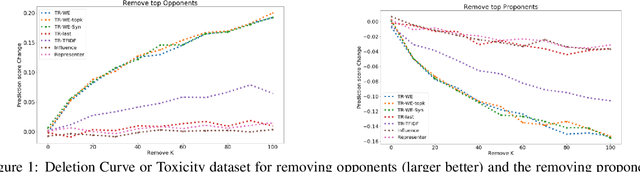

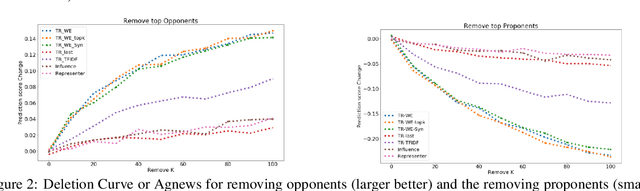
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
Reciprocity in Machine Learning
Feb 19, 2022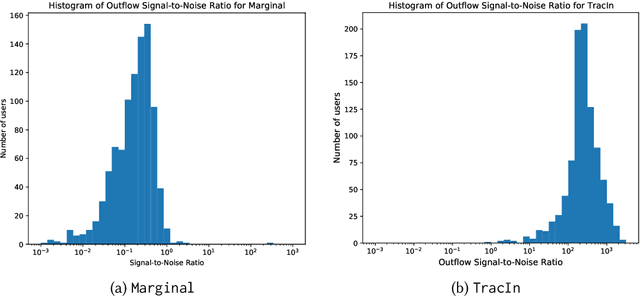
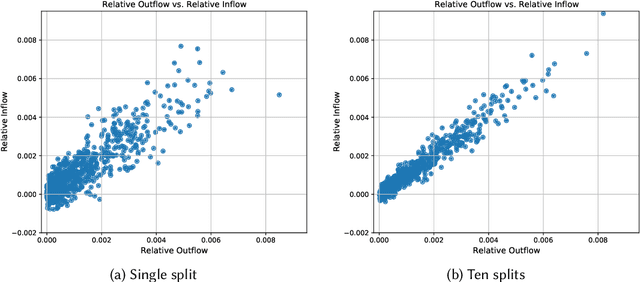
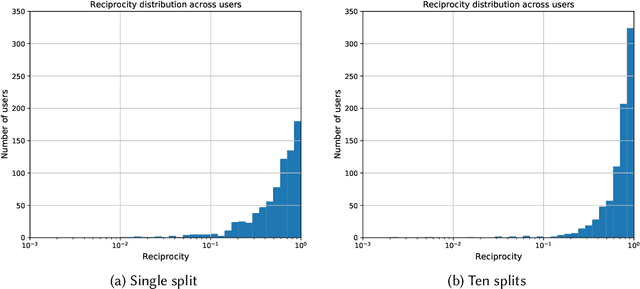
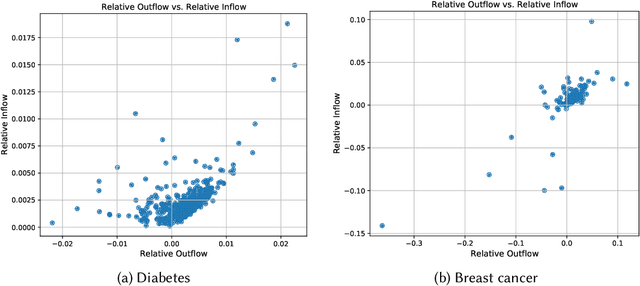
Machine learning is pervasive. It powers recommender systems such as Spotify, Instagram and YouTube, and health-care systems via models that predict sleep patterns, or the risk of disease. Individuals contribute data to these models and benefit from them. Are these contributions (outflows of influence) and benefits (inflows of influence) reciprocal? We propose measures of outflows, inflows and reciprocity building on previously proposed measures of training data influence. Our initial theoretical and empirical results indicate that under certain distributional assumptions, some classes of models are approximately reciprocal. We conclude with several open directions.
The Penalty Imposed by Ablated Data Augmentation
Jun 08, 2020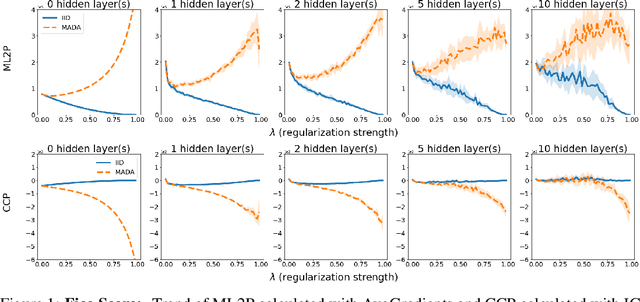
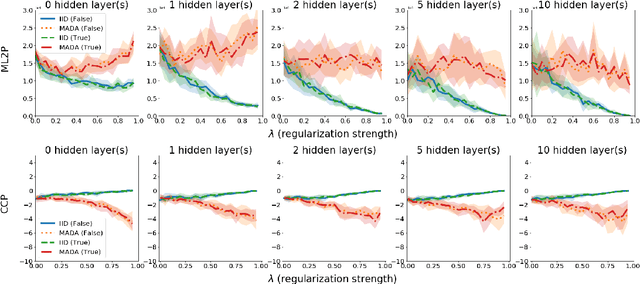
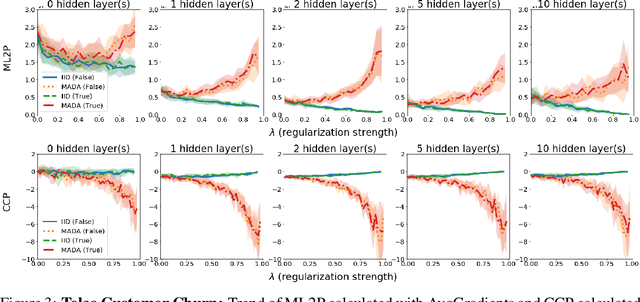
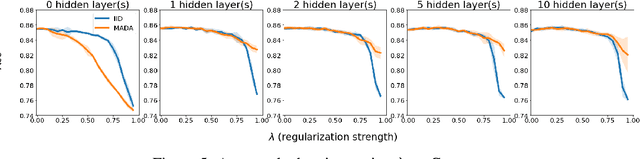
There is a set of data augmentation techniques that ablate parts of the input at random. These include input dropout, cutout, and random erasing. We term these techniques ablated data augmentation. Though these techniques seems similar in spirit and have shown success in improving model performance in a variety of domains, we do not yet have a mathematical understanding of the differences between these techniques like we do for other regularization techniques like L1 or L2. First, we study a formal model of mean ablated data augmentation and inverted dropout for linear regression. We prove that ablated data augmentation is equivalent to optimizing the ordinary least squares objective along with a penalty that we call the Contribution Covariance Penalty and inverted dropout, a more common implementation than dropout in popular frameworks, is equivalent to optimizing the ordinary least squares objective along with Modified L2. For deep networks, we demonstrate an empirical version of the result if we replace contributions with attributions and coefficients with average gradients, i.e., the Contribution Covariance Penalty and Modified L2 Penalty drop with the increase of the corresponding ablated data augmentation across a variety of networks.
Attribution in Scale and Space
Apr 08, 2020
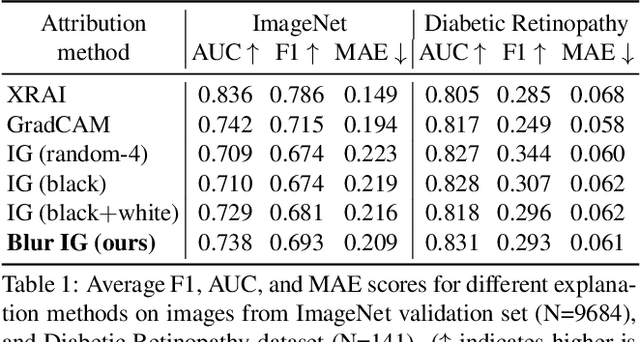
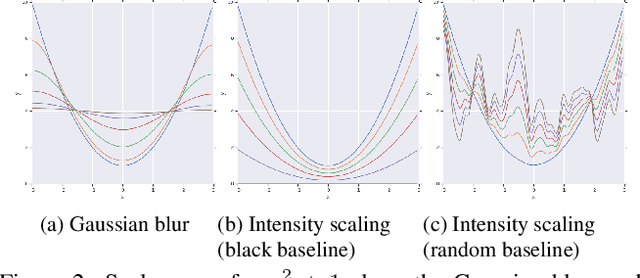

We study the attribution problem [28] for deep networks applied to perception tasks. For vision tasks, attribution techniques attribute the prediction of a network to the pixels of the input image. We propose a new technique called \emph{Blur Integrated Gradients}. This technique has several advantages over other methods. First, it can tell at what scale a network recognizes an object. It produces scores in the scale/frequency dimension, that we find captures interesting phenomena. Second, it satisfies the scale-space axioms [14], which imply that it employs perturbations that are free of artifact. We therefore produce explanations that are cleaner and consistent with the operation of deep networks. Third, it eliminates the need for a 'baseline' parameter for Integrated Gradients [31] for perception tasks. This is desirable because the choice of baseline has a significant effect on the explanations. We compare the proposed technique against previous techniques and demonstrate application on three tasks: ImageNet object recognition, Diabetic Retinopathy prediction, and AudioSet audio event identification.
Estimating Training Data Influence by Tracking Gradient Descent
Feb 19, 2020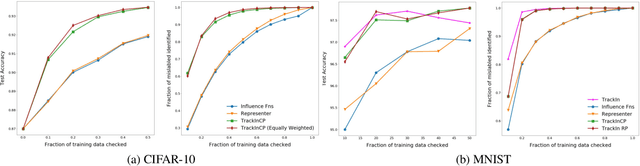

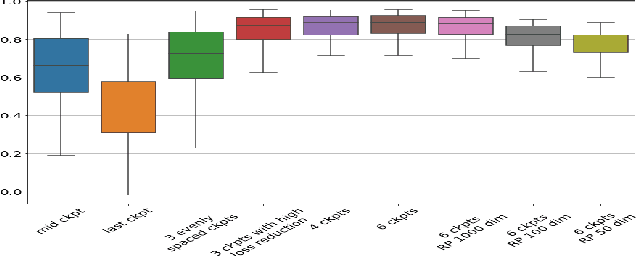
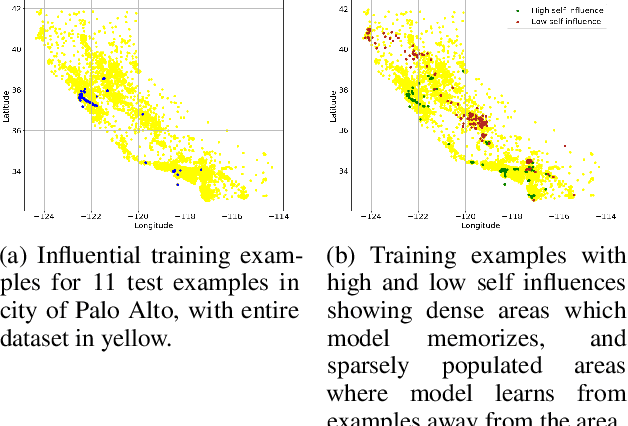
We introduce a method called TrackIn that computes the influence of a training example on a prediction made by the model, by tracking how the loss on the test point changes during the training process whenever the training example of interest was utilized. We provide a scalable implementation of TrackIn via a combination of a few key ideas: (a) a first-order approximation to the exact computation, (b) using random projections to speed up the computation of the first-order approximation for large models, (c) using saved checkpoints of standard training procedures, and (d) cherry-picking layers of a deep neural network. An experimental evaluation shows that TrackIn is more effective in identifying mislabelled training examples than other related methods such as influence functions and representer points. We also discuss insights from applying the method on vision, regression and natural language tasks.