 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Penalty Imposed by Ablated Data Augmentation
Paper and Code
Jun 08, 2020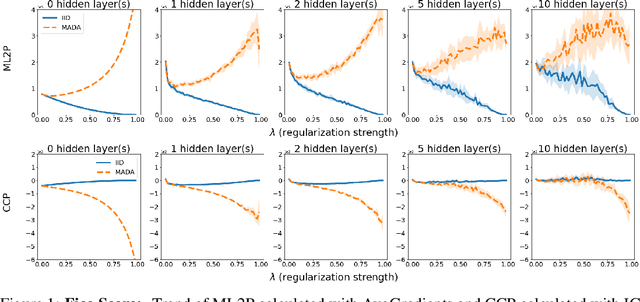
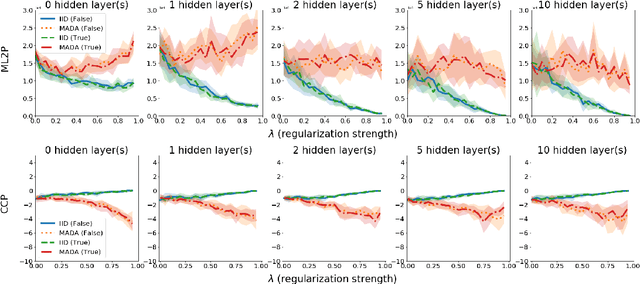
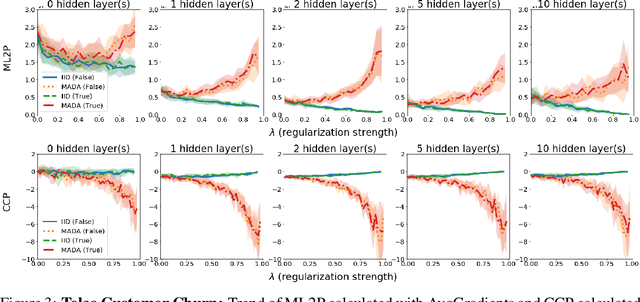
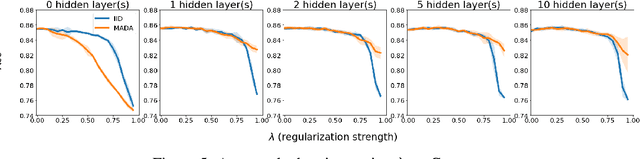
There is a set of data augmentation techniques that ablate parts of the input at random. These include input dropout, cutout, and random erasing. We term these techniques ablated data augmentation. Though these techniques seems similar in spirit and have shown success in improving model performance in a variety of domains, we do not yet have a mathematical understanding of the differences between these techniques like we do for other regularization techniques like L1 or L2. First, we study a formal model of mean ablated data augmentation and inverted dropout for linear regression. We prove that ablated data augmentation is equivalent to optimizing the ordinary least squares objective along with a penalty that we call the Contribution Covariance Penalty and inverted dropout, a more common implementation than dropout in popular frameworks, is equivalent to optimizing the ordinary least squares objective along with Modified L2. For deep networks, we demonstrate an empirical version of the result if we replace contributions with attributions and coefficients with average gradients, i.e., the Contribution Covariance Penalty and Modified L2 Penalty drop with the increase of the corresponding ablated data augmentation across a variety of networks.