 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Minimal Targeted Updates of Language Models with Targeted Negative Training
Jun 19, 2024
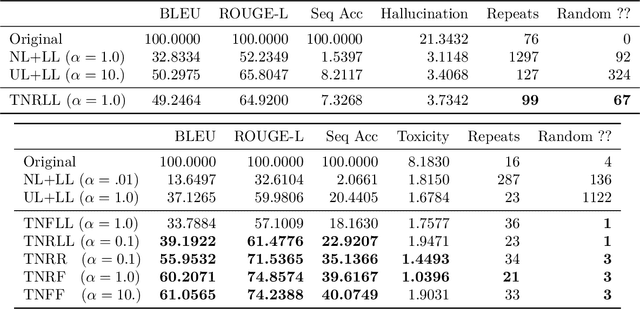
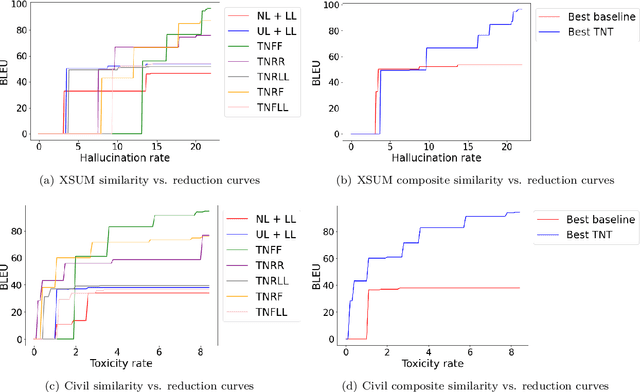
Generative models of language exhibit impressive capabilities but still place non-negligible probability mass over undesirable outputs. In this work, we address the task of updating a model to avoid unwanted outputs while minimally changing model behavior otherwise, a challenge we refer to as a minimal targeted update. We first formalize the notion of a minimal targeted update and propose a method to achieve such updates using negative examples from a model's generations. Our proposed Targeted Negative Training (TNT) results in updates that keep the new distribution close to the original, unlike existing losses for negative signal which push down probability but do not control what the updated distribution will be. In experiments, we demonstrate that TNT yields a better trade-off between reducing unwanted behavior and maintaining model generation behavior than baselines, paving the way towards a modeling paradigm based on iterative training updates that constrain models from generating undesirable outputs while preserving their impressive capabilities.
Attributing AUC-ROC to Analyze Binary Classifier Performance
May 24, 2022
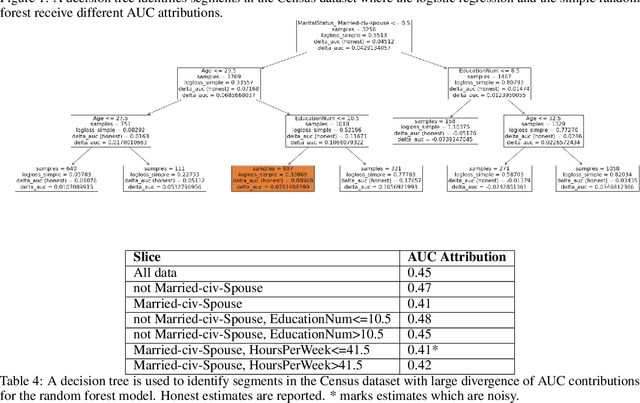
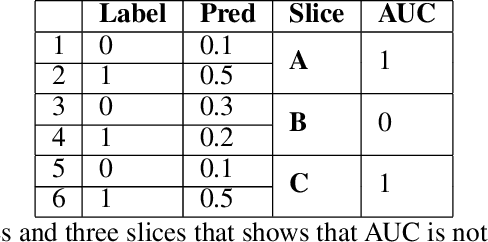
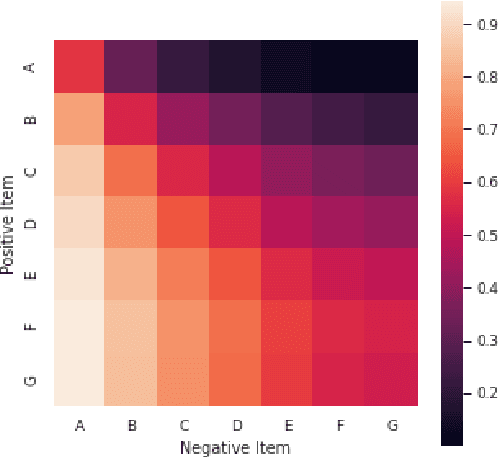
Area Under the Receiver Operating Characteristic Curve (AUC-ROC) is a popular evaluation metric for binary classifiers. In this paper, we discuss techniques to segment the AUC-ROC along human-interpretable dimensions. AUC-ROC is not an additive/linear function over the data samples, therefore such segmenting the overall AUC-ROC is different from tabulating the AUC-ROC of data segments. To segment the overall AUC-ROC, we must first solve an \emph{attribution} problem to identify credit for individual examples. We observe that AUC-ROC, though non-linear over examples, is linear over \emph{pairs} of examples. This observation leads to a simple, efficient attribution technique for examples (example attributions), and for pairs of examples (pair attributions). We automatically slice these attributions using decision trees by making the tree predict the attributions; we use the notion of honest estimates along with a t-test to mitigate false discovery. Our experiments with the method show that an inferior model can outperform a superior model (trained to optimize a different training objective) on the inferior model's own training objective, a manifestation of Goodhart's Law. In contrast, AUC attributions enable a reasonable comparison. Example attributions can be used to slice this comparison. Pair attributions are used to categorize pairs of items -- one positively labeled and one negatively -- that the model has trouble separating. These categories identify the decision boundary of the classifier and the headroom to improve AUC.