 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Ranking and Generation in Query Auto-Completion via Retrieval-Augmented Generation and Multi-Objective Alignment
Feb 03, 2026Query Auto-Completion (QAC) suggests query completions as users type, helping them articulate intent and reach results more efficiently. Existing approaches face fundamental challenges: traditional retrieve-and-rank pipelines have limited long-tail coverage and require extensive feature engineering, while recent generative methods suffer from hallucination and safety risks. We present a unified framework that reformulates QAC as end-to-end list generation through Retrieval-Augmented Generation (RAG) and multi-objective Direct Preference Optimization (DPO). Our approach combines three key innovations: (1) reformulating QAC as end-to-end list generation with multi-objective optimization; (2) defining and deploying a suite of rule-based, model-based, and LLM-as-judge verifiers for QAC, and using them in a comprehensive methodology that combines RAG, multi-objective DPO, and iterative critique-revision for high-quality synthetic data; (3) a hybrid serving architecture enabling efficient production deployment under strict latency constraints. Evaluation on a large-scale commercial search platform demonstrates substantial improvements: offline metrics show gains across all dimensions, human evaluation yields +0.40 to +0.69 preference scores, and a controlled online experiment achieves 5.44\% reduction in keystrokes and 3.46\% increase in suggestion adoption, validating that unified generation with RAG and multi-objective alignment provides an effective solution for production QAC. This work represents a paradigm shift to end-to-end generation powered by large language models, RAG, and multi-objective alignment, establishing a production-validated framework that can benefit the broader search and recommendation industry.
Attributing AUC-ROC to Analyze Binary Classifier Performance
May 24, 2022
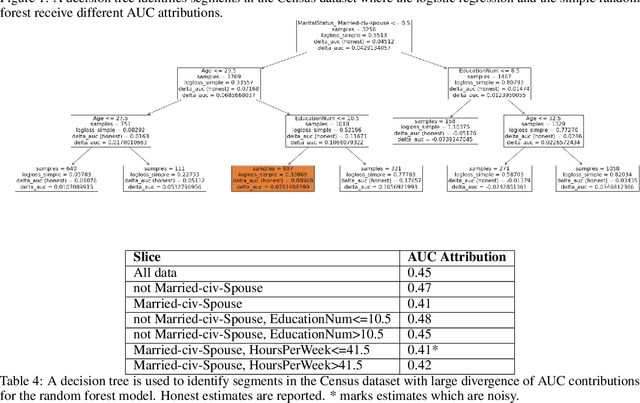
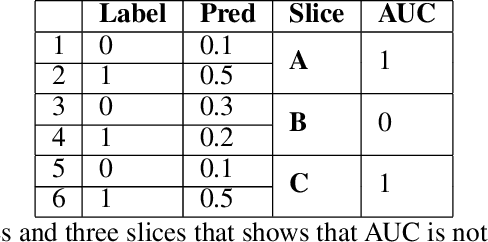
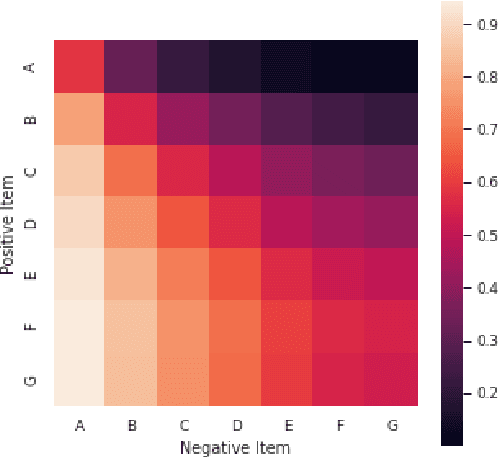
Area Under the Receiver Operating Characteristic Curve (AUC-ROC) is a popular evaluation metric for binary classifiers. In this paper, we discuss techniques to segment the AUC-ROC along human-interpretable dimensions. AUC-ROC is not an additive/linear function over the data samples, therefore such segmenting the overall AUC-ROC is different from tabulating the AUC-ROC of data segments. To segment the overall AUC-ROC, we must first solve an \emph{attribution} problem to identify credit for individual examples. We observe that AUC-ROC, though non-linear over examples, is linear over \emph{pairs} of examples. This observation leads to a simple, efficient attribution technique for examples (example attributions), and for pairs of examples (pair attributions). We automatically slice these attributions using decision trees by making the tree predict the attributions; we use the notion of honest estimates along with a t-test to mitigate false discovery. Our experiments with the method show that an inferior model can outperform a superior model (trained to optimize a different training objective) on the inferior model's own training objective, a manifestation of Goodhart's Law. In contrast, AUC attributions enable a reasonable comparison. Example attributions can be used to slice this comparison. Pair attributions are used to categorize pairs of items -- one positively labeled and one negatively -- that the model has trouble separating. These categories identify the decision boundary of the classifier and the headroom to improve AUC.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles
Jun 29, 2021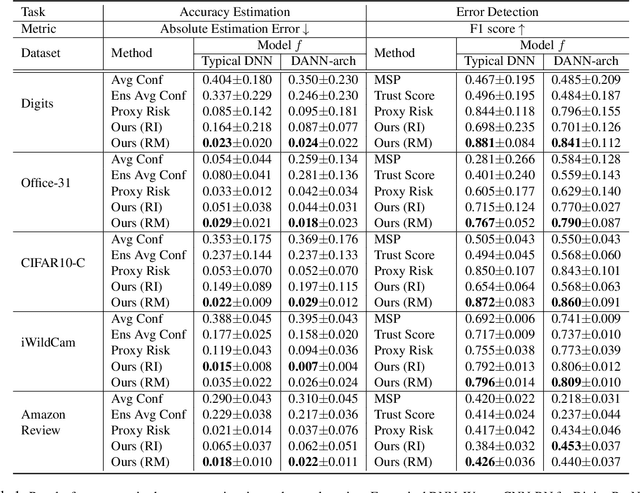
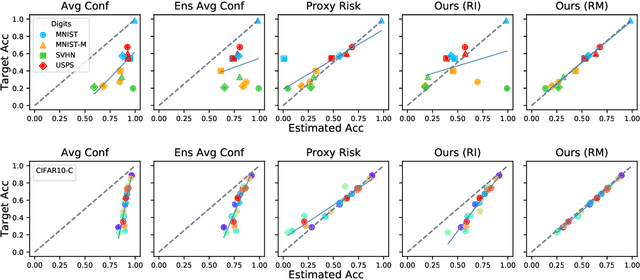
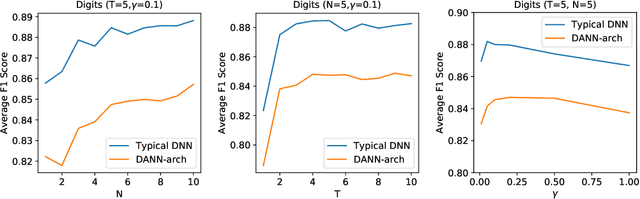
When a deep learning model is deployed in the wild, it can encounter test data drawn from distributions different from the training data distribution and suffer drop in performance. For safe deployment, it is essential to estimate the accuracy of the pre-trained model on the test data. However, the labels for the test inputs are usually not immediately available in practice, and obtaining them can be expensive. This observation leads to two challenging tasks: (1) unsupervised accuracy estimation, which aims to estimate the accuracy of a pre-trained classifier on a set of unlabeled test inputs; (2) error detection, which aims to identify mis-classified test inputs. In this paper, we propose a principled and practically effective framework that simultaneously addresses the two tasks. The proposed framework iteratively learns an ensemble of models to identify mis-classified data points and performs self-training to improve the ensemble with the identified points. Theoretical analysis demonstrates that our framework enjoys provable guarantees for both accuracy estimation and error detection under mild conditions readily satisfied by practical deep learning models. Along with the framework, we proposed and experimented with two instantiations and achieved state-of-the-art results on 59 tasks. For example, on iWildCam, one instantiation reduces the estimation error for unsupervised accuracy estimation by at least 70% and improves the F1 score for error detection by at least 4.7% compared to existing methods.
Guided Integrated Gradients: An Adaptive Path Method for Removing Noise
Jun 17, 2021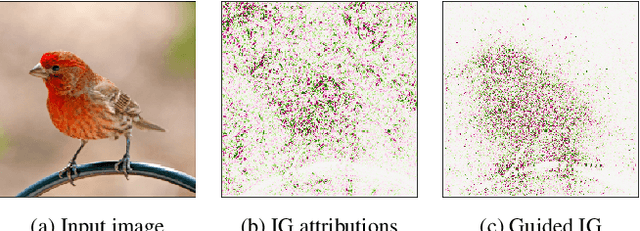
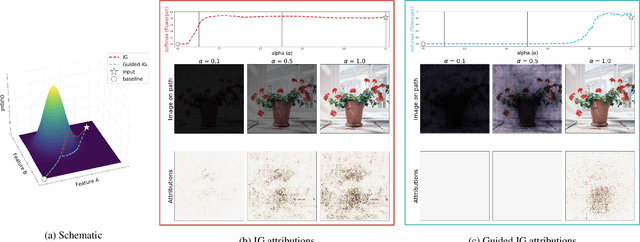
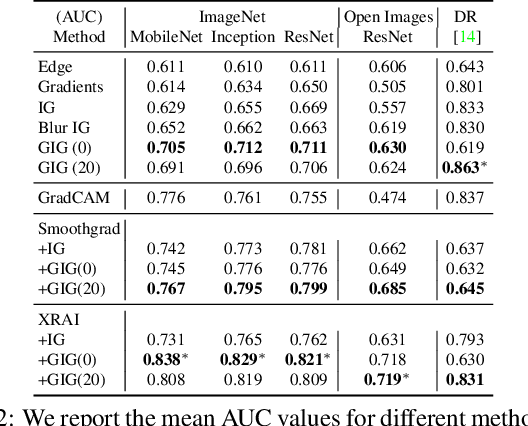
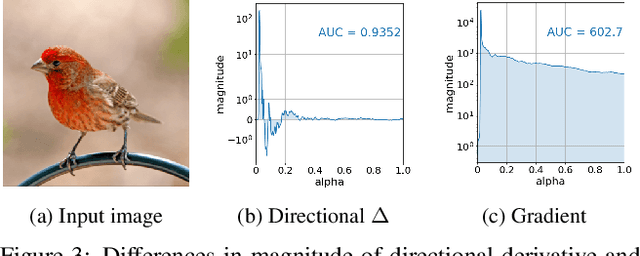
Integrated Gradients (IG) is a commonly used feature attribution method for deep neural networks. While IG has many desirable properties, the method often produces spurious/noisy pixel attributions in regions that are not related to the predicted class when applied to visual models. While this has been previously noted, most existing solutions are aimed at addressing the symptoms by explicitly reducing the noise in the resulting attributions. In this work, we show that one of the causes of the problem is the accumulation of noise along the IG path. To minimize the effect of this source of noise, we propose adapting the attribution path itself -- conditioning the path not just on the image but also on the model being explained. We introduce Adaptive Path Methods (APMs) as a generalization of path methods, and Guided IG as a specific instance of an APM. Empirically, Guided IG creates saliency maps better aligned with the model's prediction and the input image that is being explained. We show through qualitative and quantitative experiments that Guided IG outperforms other, related methods in nearly every experiment.
* 13 pages, 11 figures, for implementation sources see https://github.com/PAIR-code/saliency
Incorporating Priors with Feature Attribution on Text Classification
Jun 19, 2019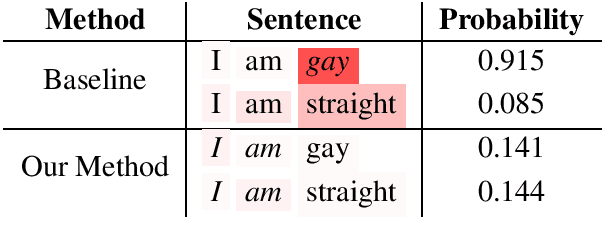
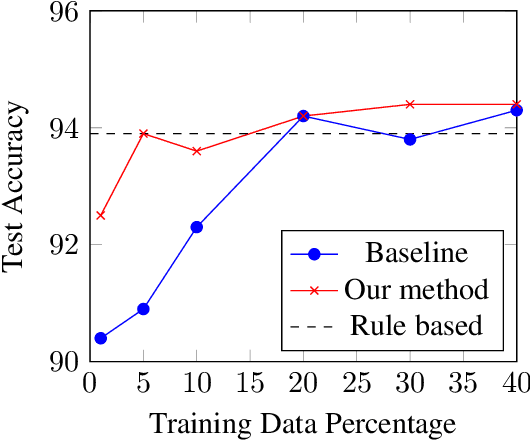
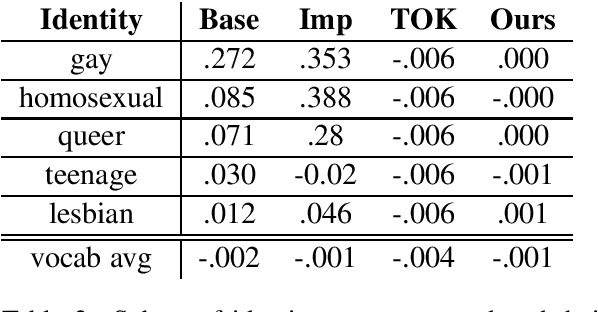

Feature attribution methods, proposed recently, help users interpret the predictions of complex models. Our approach integrates feature attributions into the objective function to allow machine learning practitioners to incorporate priors in model building. To demonstrate the effectiveness our technique, we apply it to two tasks: (1) mitigating unintended bias in text classifiers by neutralizing identity terms; (2) improving classifier performance in a scarce data setting by forcing the model to focus on toxic terms. Our approach adds an L2 distance loss between feature attributions and task-specific prior values to the objective. Our experiments show that i) a classifier trained with our technique reduces undesired model biases without a trade off on the original task; ii) incorporating priors helps model performance in scarce data settings.