 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAILRec: Steering LLM Attention to Dual-Side Semantically Aligned Collaborative Embeddings for Recommendation
Jun 03, 2026Recent LLM-based recommenders enhance language models with collaborative embeddings from user-item interactions, but making such embeddings available does not ensure their proper use during inference. Through a diagnostic attention analysis, we find that the utilization of collaborative embeddings is depth-dependent and alignment-sensitive, suggesting that LLMs need to balance their internal semantic knowledge with external collaborative knowledge. To address this issue, we propose SAILRec, an LLM-based recommender that improves this balance through dual-side semantic alignment and hierarchical attention steering. The former aligns item-side embeddings with item-text semantics and user-side embeddings with codebook-based semantic profiles, while the latter suppresses premature shallow-layer collaborative interference and strengthens collaborative evidence in deeper decision layers. Experiments on MovieLens-1M and Amazon-Book show that SAILRec consistently outperforms representative baselines, with ablation and masking analyses validating its key designs.
Beyond Text Following: Repairable Arbitration Reversals in Audio-Language Models
Jun 03, 2026Audio-language models (ALMs) often follow text that conflicts with audio, even when the audio evidence is clear. This raises a basic question: is the audio-supported answer unavailable, or is it represented but overridden by the conflicting text? We examine this question using a same-audio counterfactual that keeps the audio fixed, removes only the conflicting text, and measures the resulting shift in model preference. Across five ALMs and four conflict tasks, 64.1% of conflict samples show a sign flip: the same-audio branch prefers the audio-supported answer, whereas the joint branch prefers the text-supported answer. This pattern suggests that the relevant audio evidence is encoded but loses in arbitration. Activation patching further localizes the reversal to answer-position computation, and patching effects closely track output candidate-score differences (Spearman rho=0.93). Using this diagnostic, we propose Gated Audio Counterfactual Logit Correction (GACL), a training-free decoding rule that interpolates between joint and same-audio scores. Under a strict 5 pp faithfulness-drop budget, GACL improves nAUC by 17.8 points over the best contrastive baseline and transfers without retuning to vision-text arbitration (up to +40.5 pp).
Evidence-Based Actor-Verifier Reasoning for Echocardiographic Agents
Apr 07, 2026Echocardiography plays an important role in the screening and diagnosis of cardiovascular diseases. However, automated intelligent analysis of echocardiographic data remains challenging due to complex cardiac dynamics and strong view heterogeneity. In recent years, visual language models (VLM) have opened a new avenue for building ultrasound understanding systems for clinical decision support. Nevertheless, most existing methods formulate this task as a direct mapping from video and question to answer, making them vulnerable to template shortcuts and spurious explanations. To address these issues, we propose EchoTrust, an evidence-driven Actor-Verifier framework for trustworthy reasoning in echocardiography VLM-based agents. EchoTrust produces a structured intermediate representation that is subsequently analyzed by distinct roles, enabling more reliable and interpretable decision-making for high-stakes clinical applications.
Interactive Motion Planning for Human-Robot Collaboration Based on Human-Centric Configuration Space Ergonomic Field
Dec 16, 2025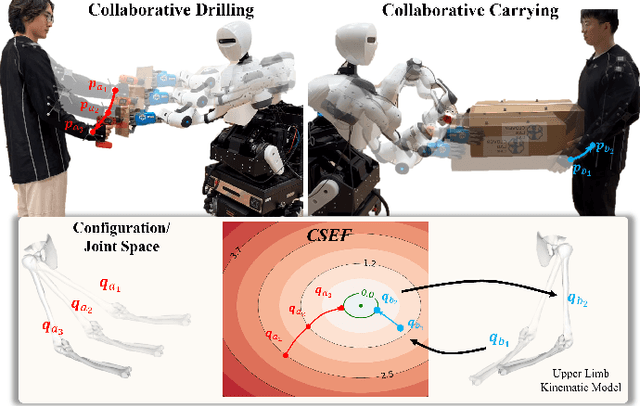
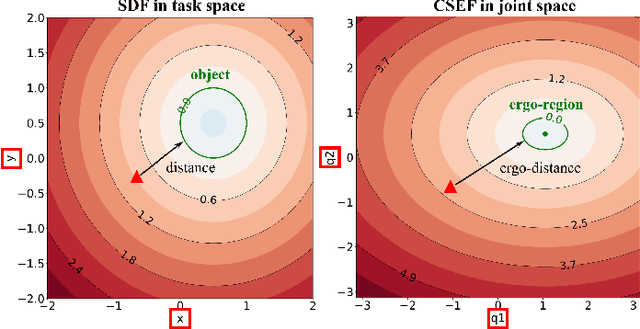
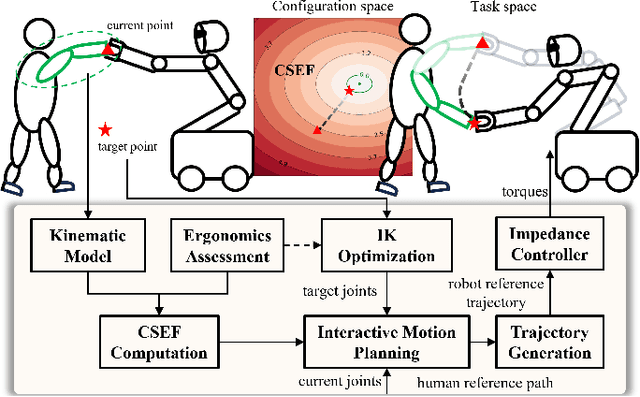
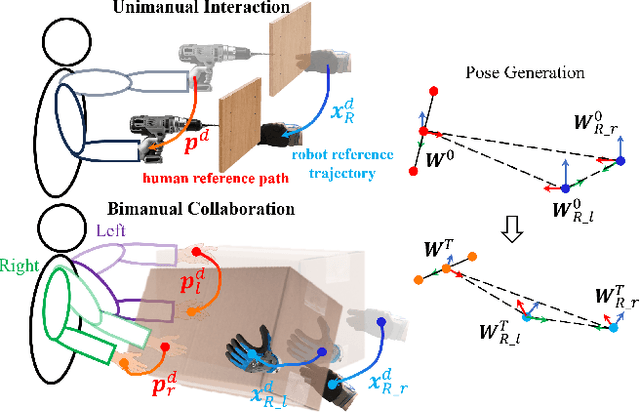
Industrial human-robot collaboration requires motion planning that is collision-free, responsive, and ergonomically safe to reduce fatigue and musculoskeletal risk. We propose the Configuration Space Ergonomic Field (CSEF), a continuous and differentiable field over the human joint space that quantifies ergonomic quality and provides gradients for real-time ergonomics-aware planning. An efficient algorithm constructs CSEF from established metrics with joint-wise weighting and task conditioning, and we integrate it into a gradient-based planner compatible with impedance-controlled robots. In a 2-DoF benchmark, CSEF-based planning achieves higher success rates, lower ergonomic cost, and faster computation than a task-space ergonomic planner. Hardware experiments with a dual-arm robot in unimanual guidance, collaborative drilling, and bimanual cocarrying show faster ergonomic cost reduction, closer tracking to optimized joint targets, and lower muscle activation than a point-to-point baseline. CSEF-based planning method reduces average ergonomic scores by up to 10.31% for collaborative drilling tasks and 5.60% for bimanual co-carrying tasks while decreasing activation in key muscle groups, indicating practical benefits for real-world deployment.
Advancing Ocean State Estimation with efficient and scalable AI
Nov 08, 2025Accurate and efficient global ocean state estimation remains a grand challenge for Earth system science, hindered by the dual bottlenecks of computational scalability and degraded data fidelity in traditional data assimilation (DA) and deep learning (DL) approaches. Here we present an AI-driven Data Assimilation Framework for Ocean (ADAF-Ocean) that directly assimilates multi-source and multi-scale observations, ranging from sparse in-situ measurements to 4 km satellite swaths, without any interpolation or data thinning. Inspired by Neural Processes, ADAF-Ocean learns a continuous mapping from heterogeneous inputs to ocean states, preserving native data fidelity. Through AI-driven super-resolution, it reconstructs 0.25$^\circ$ mesoscale dynamics from coarse 1$^\circ$ fields, which ensures both efficiency and scalability, with just 3.7\% more parameters than the 1$^\circ$ configuration. When coupled with a DL forecasting system, ADAF-Ocean extends global forecast skill by up to 20 days compared to baselines without assimilation. This framework establishes a computationally viable and scientifically rigorous pathway toward real-time, high-resolution Earth system monitoring.
Integrating Ergonomics and Manipulability for Upper Limb Postural Optimization in Bimanual Human-Robot Collaboration
Nov 06, 2025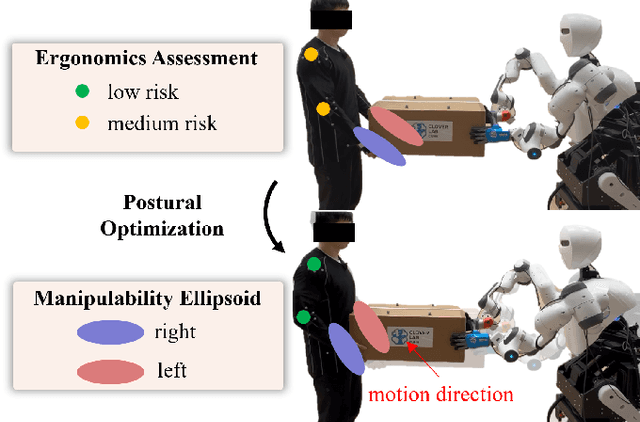

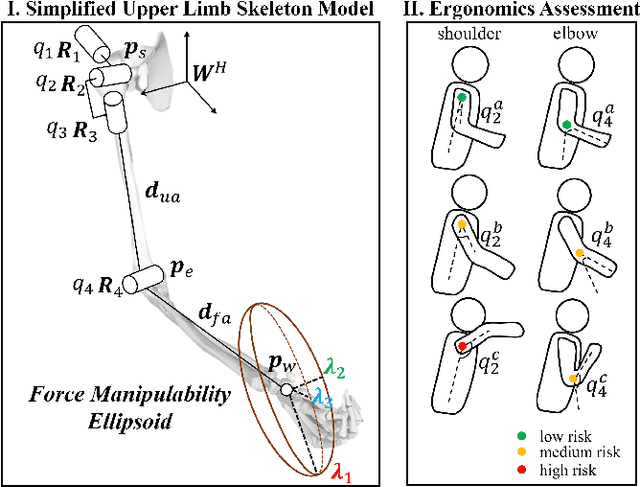
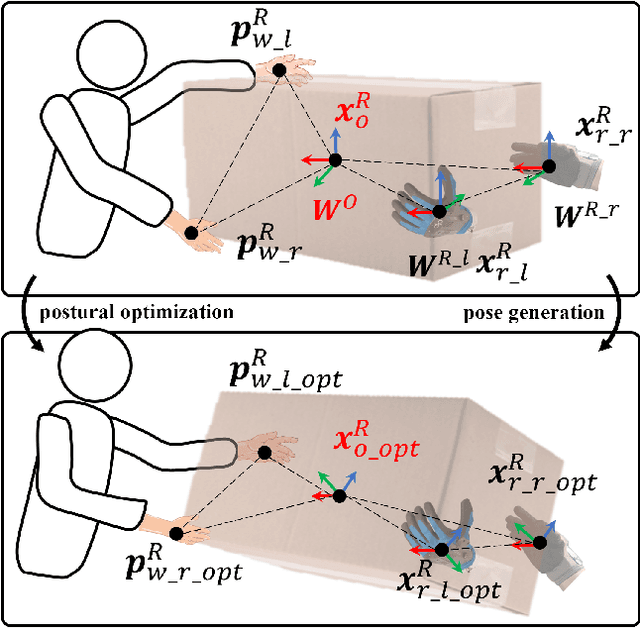
This paper introduces an upper limb postural optimization method for enhancing physical ergonomics and force manipulability during bimanual human-robot co-carrying tasks. Existing research typically emphasizes human safety or manipulative efficiency, whereas our proposed method uniquely integrates both aspects to strengthen collaboration across diverse conditions (e.g., different grasping postures of humans, and different shapes of objects). Specifically, the joint angles of a simplified human skeleton model are optimized by minimizing the cost function to prioritize safety and manipulative capability. To guide humans towards the optimized posture, the reference end-effector poses of the robot are generated through a transformation module. A bimanual model predictive impedance controller (MPIC) is proposed for our human-like robot, CURI, to recalibrate the end effector poses through planned trajectories. The proposed method has been validated through various subjects and objects during human-human collaboration (HHC) and human-robot collaboration (HRC). The experimental results demonstrate significant improvement in muscle conditions by comparing the activation of target muscles before and after optimization.
RLMiniStyler: Light-weight RL Style Agent for Arbitrary Sequential Neural Style Generation
May 07, 2025Arbitrary style transfer aims to apply the style of any given artistic image to another content image. Still, existing deep learning-based methods often require significant computational costs to generate diverse stylized results. Motivated by this, we propose a novel reinforcement learning-based framework for arbitrary style transfer RLMiniStyler. This framework leverages a unified reinforcement learning policy to iteratively guide the style transfer process by exploring and exploiting stylization feedback, generating smooth sequences of stylized results while achieving model lightweight. Furthermore, we introduce an uncertainty-aware multi-task learning strategy that automatically adjusts loss weights to adapt to the content and style balance requirements at different training stages, thereby accelerating model convergence. Through a series of experiments across image various resolutions, we have validated the advantages of RLMiniStyler over other state-of-the-art methods in generating high-quality, diverse artistic image sequences at a lower cost. Codes are available at https://github.com/fengxiaoming520/RLMiniStyler.
Real-Time Animatable 2DGS-Avatars with Detail Enhancement from Monocular Videos
May 01, 2025High-quality, animatable 3D human avatar reconstruction from monocular videos offers significant potential for reducing reliance on complex hardware, making it highly practical for applications in game development, augmented reality, and social media. However, existing methods still face substantial challenges in capturing fine geometric details and maintaining animation stability, particularly under dynamic or complex poses. To address these issues, we propose a novel real-time framework for animatable human avatar reconstruction based on 2D Gaussian Splatting (2DGS). By leveraging 2DGS and global SMPL pose parameters, our framework not only aligns positional and rotational discrepancies but also enables robust and natural pose-driven animation of the reconstructed avatars. Furthermore, we introduce a Rotation Compensation Network (RCN) that learns rotation residuals by integrating local geometric features with global pose parameters. This network significantly improves the handling of non-rigid deformations and ensures smooth, artifact-free pose transitions during animation. Experimental results demonstrate that our method successfully reconstructs realistic and highly animatable human avatars from monocular videos, effectively preserving fine-grained details while ensuring stable and natural pose variation. Our approach surpasses current state-of-the-art methods in both reconstruction quality and animation robustness on public benchmarks.
Muscle Activation Estimation by Optimizing the Musculoskeletal Model for Personalized Strength and Conditioning Training
Feb 20, 2025



Musculoskeletal models are pivotal in the domains of rehabilitation and resistance training to analyze muscle conditions. However, individual variability in musculoskeletal parameters and the immeasurability of some internal biomechanical variables pose significant obstacles to accurate personalized modelling. Furthermore, muscle activation estimation can be challenging due to the inherent redundancy of the musculoskeletal system, where multiple muscles drive a single joint. This study develops a whole-body musculoskeletal model for strength and conditioning training and calibrates relevant muscle parameters with an electromyography-based optimization method. By utilizing the personalized musculoskeletal model, muscle activation can be subsequently estimated to analyze the performance of exercises. Bench press and deadlift are chosen for experimental verification to affirm the efficacy of this approach.
Human-Like Robot Impedance Regulation Skill Learning from Human-Human Demonstrations
Feb 19, 2025Humans are experts in collaborating with others physically by regulating compliance behaviors based on the perception of their partner states and the task requirements. Enabling robots to develop proficiency in human collaboration skills can facilitate more efficient human-robot collaboration (HRC). This paper introduces an innovative impedance regulation skill learning framework for achieving HRC in multiple physical collaborative tasks. The framework is designed to adjust the robot compliance to the human partner states while adhering to reference trajectories provided by human-human demonstrations. Specifically, electromyography (EMG) signals from human muscles are collected and analyzed to extract limb impedance, representing compliance behaviors during demonstrations. Human endpoint motions are captured and represented using a probabilistic learning method to create reference trajectories and corresponding impedance profiles. Meanwhile, an LSTMbased module is implemented to develop task-oriented impedance regulation policies by mapping the muscle synergistic contributions between two demonstrators. Finally, we propose a wholebody impedance controller for a human-like robot, coordinating joint outputs to achieve the desired impedance and reference trajectory during task execution. Experimental validation was conducted through a collaborative transportation task and two interactive Tai Chi pushing hands tasks, demonstrating superior performance from the perspective of interactive forces compared to a constant impedance control method.