 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASIC: Semi-supervised Multi-organ Segmentation with Balanced Subclass Regularization and Semantic-conflict Penalty
Jan 07, 2025



Semi-supervised learning (SSL) has shown notable potential in relieving the heavy demand of dense prediction tasks on large-scale well-annotated datasets, especially for the challenging multi-organ segmentation (MoS). However, the prevailing class-imbalance problem in MoS caused by the substantial variations in organ size exacerbates the learning difficulty of the SSL network. To address this issue, in this paper, we propose an innovative semi-supervised network with BAlanced Subclass regularIzation and semantic-Conflict penalty mechanism (BASIC) to effectively learn the unbiased knowledge for semi-supervised MoS. Concretely, we construct a novel auxiliary subclass segmentation (SCS) task based on priorly generated balanced subclasses, thus deeply excavating the unbiased information for the main MoS task with the fashion of multi-task learning. Additionally, based on a mean teacher framework, we elaborately design a balanced subclass regularization to utilize the teacher predictions of SCS task to supervise the student predictions of MoS task, thus effectively transferring unbiased knowledge to the MoS subnetwork and alleviating the influence of the class-imbalance problem. Considering the similar semantic information inside the subclasses and their corresponding original classes (i.e., parent classes), we devise a semantic-conflict penalty mechanism to give heavier punishments to the conflicting SCS predictions with wrong parent classes and provide a more accurate constraint to the MoS predictions. Extensive experiments conducted on two publicly available datasets, i.e., the WORD dataset and the MICCAI FLARE 2022 dataset, have verified the superior performance of our proposed BASIC compared to other state-of-the-art methods.
Alleviating Class Imbalance in Semi-supervised Multi-organ Segmentation via Balanced Subclass Regularization
Aug 26, 2024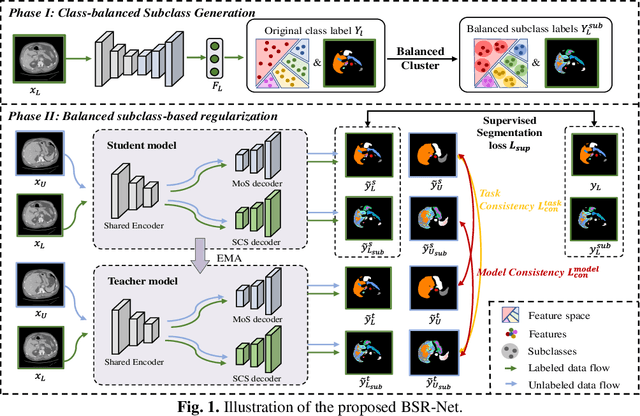
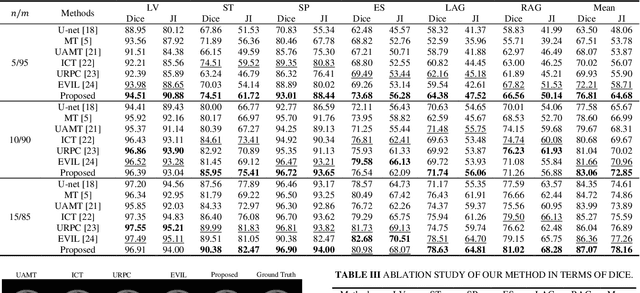
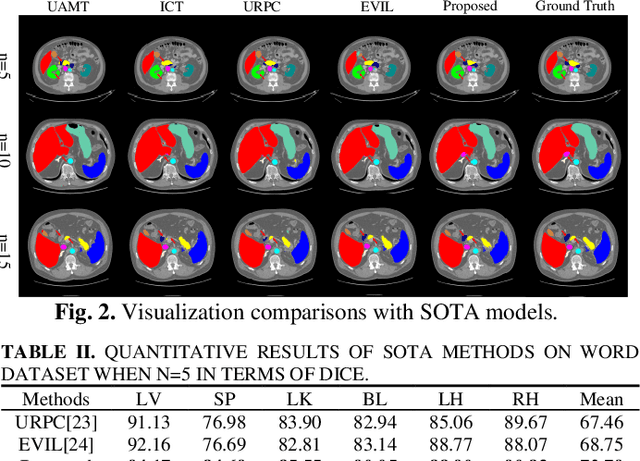
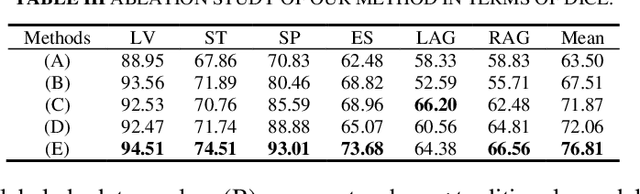
Semi-supervised learning (SSL) has shown notable potential in relieving the heavy demand of dense prediction tasks on large-scale well-annotated datasets, especially for the challenging multi-organ segmentation (MoS). However, the prevailing class-imbalance problem in MoS, caused by the substantial variations in organ size, exacerbates the learning difficulty of the SSL network. To alleviate this issue, we present a two-phase semi-supervised network (BSR-Net) with balanced subclass regularization for MoS. Concretely, in Phase I, we introduce a class-balanced subclass generation strategy based on balanced clustering to effectively generate multiple balanced subclasses from original biased ones according to their pixel proportions. Then, in Phase II, we design an auxiliary subclass segmentation (SCS) task within the multi-task framework of the main MoS task. The SCS task contributes a balanced subclass regularization to the main MoS task and transfers unbiased knowledge to the MoS network, thus alleviating the influence of the class-imbalance problem. Extensive experiments conducted on two publicly available datasets, i.e., the MICCAI FLARE 2022 dataset and the WORD dataset, verify the superior performance of our method compared with other methods.
ARANet: Attention-based Residual Adversarial Network with Deep Supervision for Radiotherapy Dose Prediction of Cervical Cancer
Aug 26, 2024Radiation therapy is the mainstay treatment for cervical cancer, and its ultimate goal is to ensure the planning target volume (PTV) reaches the prescribed dose while reducing dose deposition of organs-at-risk (OARs) as much as possible. To achieve these clinical requirements, the medical physicist needs to manually tweak the radiotherapy plan repeatedly in a trial-anderror manner until finding the optimal one in the clinic. However, such trial-and-error processes are quite time-consuming, and the quality of plans highly depends on the experience of the medical physicist. In this paper, we propose an end-to-end Attentionbased Residual Adversarial Network with deep supervision, namely ARANet, to automatically predict the 3D dose distribution of cervical cancer. Specifically, given the computer tomography (CT) images and their corresponding segmentation masks of PTV and OARs, ARANet employs a prediction network to generate the dose maps. We also utilize a multi-scale residual attention module and deep supervision mechanism to enforce the prediction network to extract more valuable dose features while suppressing irrelevant information. Our proposed method is validated on an in-house dataset including 54 cervical cancer patients, and experimental results have demonstrated its obvious superiority compared to other state-of-the-art methods.
Learning with Alignments: Tackling the Inter- and Intra-domain Shifts for Cross-multidomain Facial Expression Recognition
Jul 08, 2024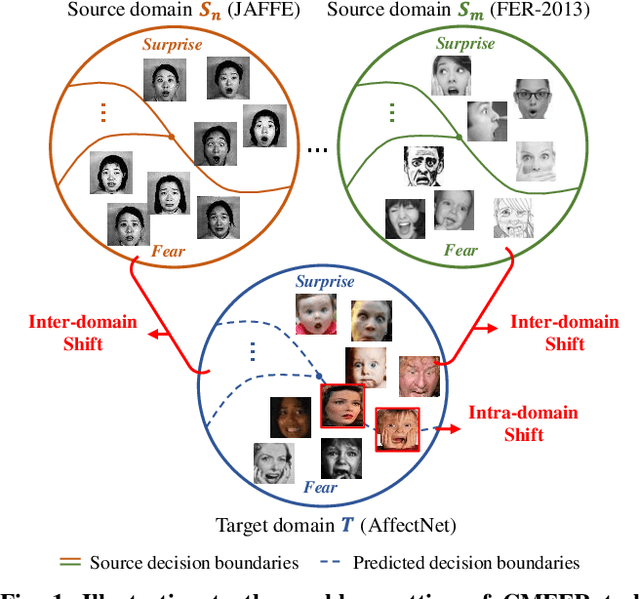

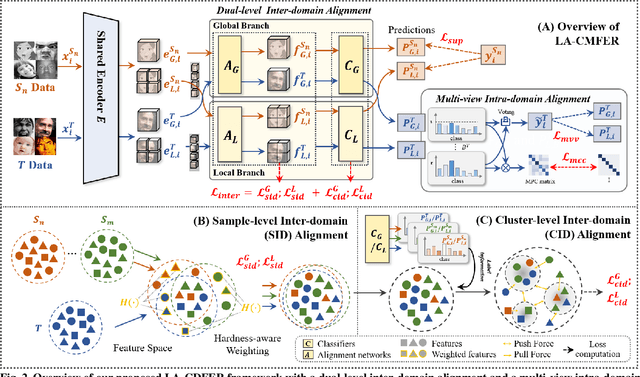
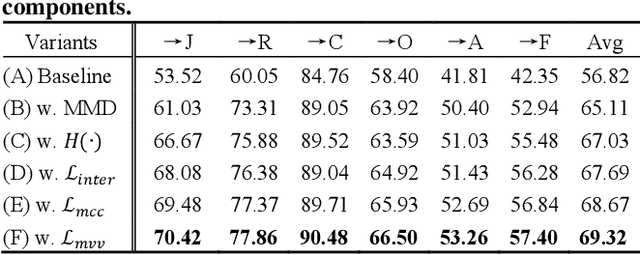
Facial Expression Recognition (FER) holds significant importance in human-computer interactions. Existing cross-domain FER methods often transfer knowledge solely from a single labeled source domain to an unlabeled target domain, neglecting the comprehensive information across multiple sources. Nevertheless, cross-multidomain FER (CMFER) is very challenging for (i) the inherent inter-domain shifts across multiple domains and (ii) the intra-domain shifts stemming from the ambiguous expressions and low inter-class distinctions. In this paper, we propose a novel Learning with Alignments CMFER framework, named LA-CMFER, to handle both inter- and intra-domain shifts. Specifically, LA-CMFER is constructed with a global branch and a local branch to extract features from the full images and local subtle expressions, respectively. Based on this, LA-CMFER presents a dual-level inter-domain alignment method to force the model to prioritize hard-to-align samples in knowledge transfer at a sample level while gradually generating a well-clustered feature space with the guidance of class attributes at a cluster level, thus narrowing the inter-domain shifts. To address the intra-domain shifts, LA-CMFER introduces a multi-view intra-domain alignment method with a multi-view clustering consistency constraint where a prediction similarity matrix is built to pursue consistency between the global and local views, thus refining pseudo labels and eliminating latent noise. Extensive experiments on six benchmark datasets have validated the superiority of our LA-CMFER.
Adaptive Prompt Learning with Negative Textual Semantics and Uncertainty Modeling for Universal Multi-Source Domain Adaptation
Apr 24, 2024Universal Multi-source Domain Adaptation (UniMDA) transfers knowledge from multiple labeled source domains to an unlabeled target domain under domain shifts (different data distribution) and class shifts (unknown target classes). Existing solutions focus on excavating image features to detect unknown samples, ignoring abundant information contained in textual semantics. In this paper, we propose an Adaptive Prompt learning with Negative textual semantics and uncErtainty modeling method based on Contrastive Language-Image Pre-training (APNE-CLIP) for UniMDA classification tasks. Concretely, we utilize the CLIP with adaptive prompts to leverage textual information of class semantics and domain representations, helping the model identify unknown samples and address domain shifts. Additionally, we design a novel global instance-level alignment objective by utilizing negative textual semantics to achieve more precise image-text pair alignment. Furthermore, we propose an energy-based uncertainty modeling strategy to enlarge the margin distance between known and unknown samples. Extensive experiments demonstrate the superiority of our proposed method.
Dcl-Net: Dual Contrastive Learning Network for Semi-Supervised Multi-Organ Segmentation
Mar 06, 2024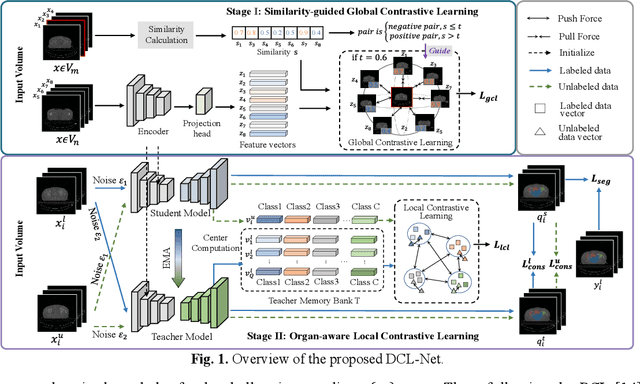

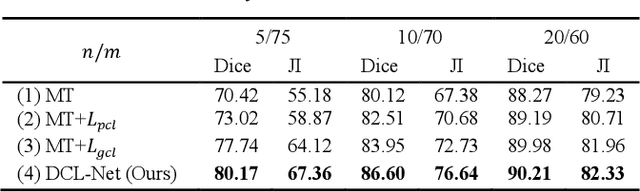
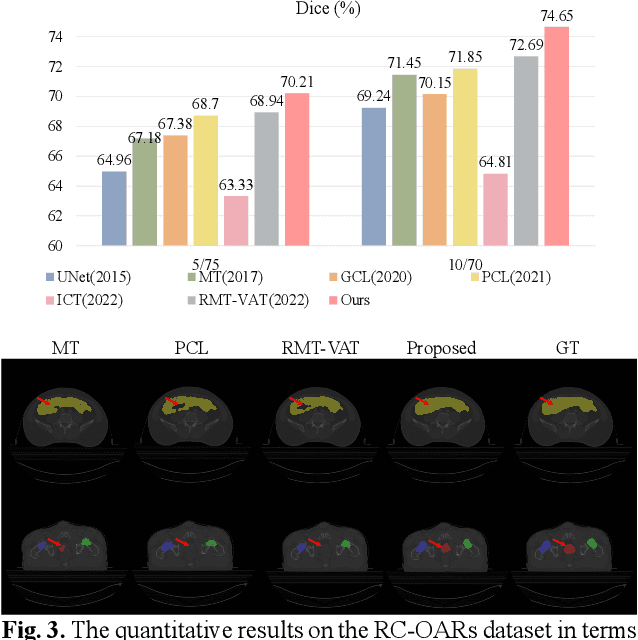
Semi-supervised learning is a sound measure to relieve the strict demand of abundant annotated datasets, especially for challenging multi-organ segmentation . However, most existing SSL methods predict pixels in a single image independently, ignoring the relations among images and categories. In this paper, we propose a two-stage Dual Contrastive Learning Network for semi-supervised MoS, which utilizes global and local contrastive learning to strengthen the relations among images and classes. Concretely, in Stage 1, we develop a similarity-guided global contrastive learning to explore the implicit continuity and similarity among images and learn global context. Then, in Stage 2, we present an organ-aware local contrastive learning to further attract the class representations. To ease the computation burden, we introduce a mask center computation algorithm to compress the category representations for local contrastive learning. Experiments conducted on the public 2017 ACDC dataset and an in-house RC-OARs dataset has demonstrated the superior performance of our method.
Triplet-constraint Transformer with Multi-scale Refinement for Dose Prediction in Radiotherapy
Feb 07, 2024
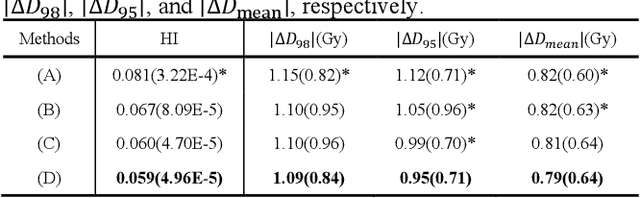
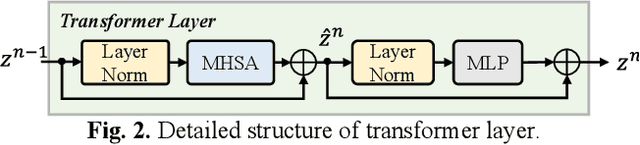
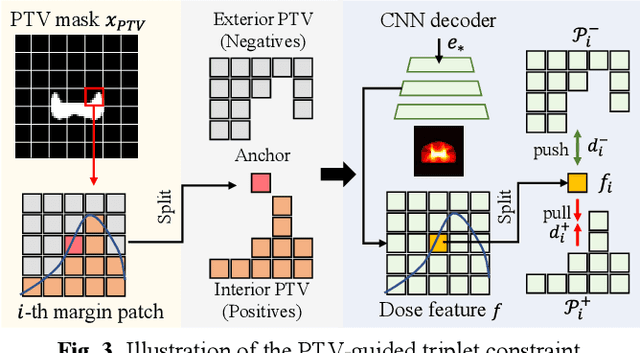
Radiotherapy is a primary treatment for cancers with the aim of applying sufficient radiation dose to the planning target volume (PTV) while minimizing dose hazards to the organs at risk (OARs). Convolutional neural networks (CNNs) have automated the radiotherapy plan-making by predicting the dose maps. However, current CNN-based methods ignore the remarkable dose difference in the dose map, i.e., high dose value in the interior PTV while low value in the exterior PTV, leading to a suboptimal prediction. In this paper, we propose a triplet-constraint transformer (TCtrans) with multi-scale refinement to predict the high-quality dose distribution. Concretely, a novel PTV-guided triplet constraint is designed to refine dose feature representations in the interior and exterior PTV by utilizing the explicit geometry of PTV. Furthermore, we introduce a multi-scale refinement (MSR) module to effectively fulfill the triplet constraint in different decoding layers with multiple scales. Besides, a transformer encoder is devised to learn the important global dosimetric knowledge. Experiments on a clinical cervical cancer dataset demonstrate the superiority of our method.
Image2Points:A 3D Point-based Context Clusters GAN for High-Quality PET Image Reconstruction
Feb 01, 2024To obtain high-quality Positron emission tomography (PET) images while minimizing radiation exposure, numerous methods have been proposed to reconstruct standard-dose PET (SPET) images from the corresponding low-dose PET (LPET) images. However, these methods heavily rely on voxel-based representations, which fall short of adequately accounting for the precise structure and fine-grained context, leading to compromised reconstruction. In this paper, we propose a 3D point-based context clusters GAN, namely PCC-GAN, to reconstruct high-quality SPET images from LPET. Specifically, inspired by the geometric representation power of points, we resort to a point-based representation to enhance the explicit expression of the image structure, thus facilitating the reconstruction with finer details. Moreover, a context clustering strategy is applied to explore the contextual relationships among points, which mitigates the ambiguities of small structures in the reconstructed images. Experiments on both clinical and phantom datasets demonstrate that our PCC-GAN outperforms the state-of-the-art reconstruction methods qualitatively and quantitatively. Code is available at https://github.com/gluucose/PCCGAN.
Dream to Adapt: Meta Reinforcement Learning by Latent Context Imagination and MDP Imagination
Nov 11, 2023Meta reinforcement learning (Meta RL) has been amply explored to quickly learn an unseen task by transferring previously learned knowledge from similar tasks. However, most state-of-the-art algorithms require the meta-training tasks to have a dense coverage on the task distribution and a great amount of data for each of them. In this paper, we propose MetaDreamer, a context-based Meta RL algorithm that requires less real training tasks and data by doing meta-imagination and MDP-imagination. We perform meta-imagination by interpolating on the learned latent context space with disentangled properties, as well as MDP-imagination through the generative world model where physical knowledge is added to plain VAE networks. Our experiments with various benchmarks show that MetaDreamer outperforms existing approaches in data efficiency and interpolated generalization.
Diffusion-based Radiotherapy Dose Prediction Guided by Inter-slice Aware Structure Encoding
Nov 06, 2023
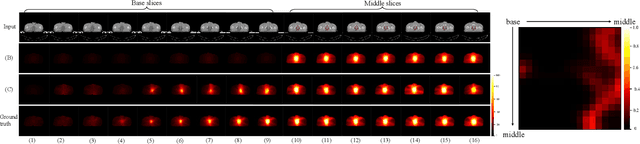
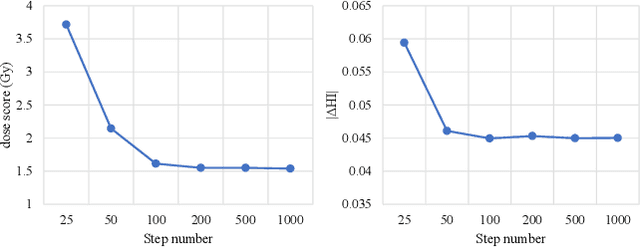

Deep learning (DL) has successfully automated dose distribution prediction in radiotherapy planning, enhancing both efficiency and quality. However, existing methods suffer from the over-smoothing problem for their commonly used L1 or L2 loss with posterior average calculations. To alleviate this limitation, we propose a diffusion model-based method (DiffDose) for predicting the radiotherapy dose distribution of cancer patients. Specifically, the DiffDose model contains a forward process and a reverse process. In the forward process, DiffDose transforms dose distribution maps into pure Gaussian noise by gradually adding small noise and a noise predictor is simultaneously trained to estimate the noise added at each timestep. In the reverse process, it removes the noise from the pure Gaussian noise in multiple steps with the well-trained noise predictor and finally outputs the predicted dose distribution maps...