 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream to Adapt: Meta Reinforcement Learning by Latent Context Imagination and MDP Imagination
Nov 11, 2023Meta reinforcement learning (Meta RL) has been amply explored to quickly learn an unseen task by transferring previously learned knowledge from similar tasks. However, most state-of-the-art algorithms require the meta-training tasks to have a dense coverage on the task distribution and a great amount of data for each of them. In this paper, we propose MetaDreamer, a context-based Meta RL algorithm that requires less real training tasks and data by doing meta-imagination and MDP-imagination. We perform meta-imagination by interpolating on the learned latent context space with disentangled properties, as well as MDP-imagination through the generative world model where physical knowledge is added to plain VAE networks. Our experiments with various benchmarks show that MetaDreamer outperforms existing approaches in data efficiency and interpolated generalization.
MonoEdge: Monocular 3D Object Detection Using Local Perspectives
Jan 04, 2023We propose a novel approach for monocular 3D object detection by leveraging local perspective effects of each object. While the global perspective effect shown as size and position variations has been exploited for monocular 3D detection extensively, the local perspectives has long been overlooked. We design a local perspective module to regress a newly defined variable named keyedge-ratios as the parameterization of the local shape distortion to account for the local perspective, and derive the object depth and yaw angle from it. Theoretically, this module does not rely on the pixel-wise size or position in the image of the objects, therefore independent of the camera intrinsic parameters. By plugging this module in existing monocular 3D object detection frameworks, we incorporate the local perspective distortion with global perspective effect for monocular 3D reasoning, and we demonstrate the effectiveness and superior performance over strong baseline methods in multiple datasets.
E$^2$PN: Efficient SE-Equivariant Point Network
Jun 11, 2022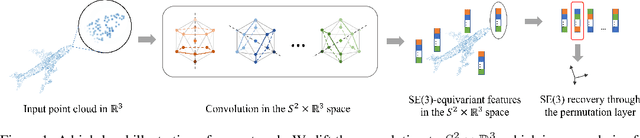

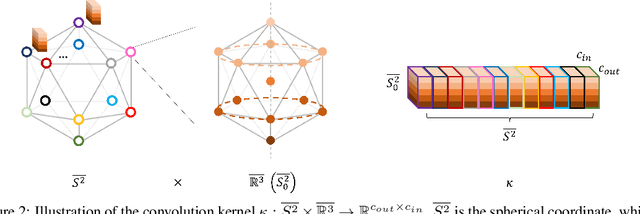

This paper proposes a new point-cloud convolution structure that learns SE(3)-equivariant features. Compared with existing SE(3)-equivariant networks, our design is lightweight, simple, and flexible to be incorporated into general point-cloud learning networks. We strike a balance between the complexity and capacity of our model by selecting an unconventional domain for the feature maps. We further reduce the computational load by properly discretizing $\mathbb{R}^3$ to fully leverage the rotational symmetry. Moreover, we employ a permutation layer to recover the full SE(3) group from its quotient space. Experiments show that our method achieves comparable or superior performance in various tasks while consuming much less memory and running faster than existing work. The proposed method can foster the adoption of equivariant feature learning in various practical applications based on point clouds and inspire future developments of equivariant feature learning for real-world applications.
CVAE-H: Conditionalizing Variational Autoencoders via Hypernetworks and Trajectory Forecasting for Autonomous Driving
Jan 24, 2022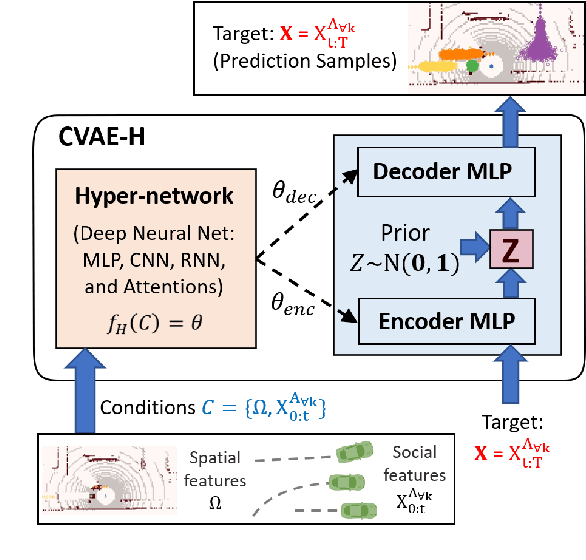
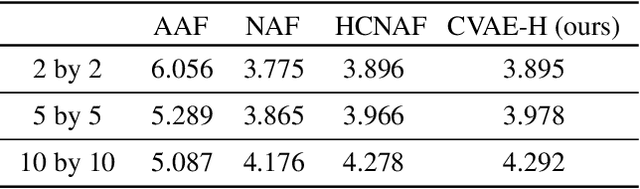
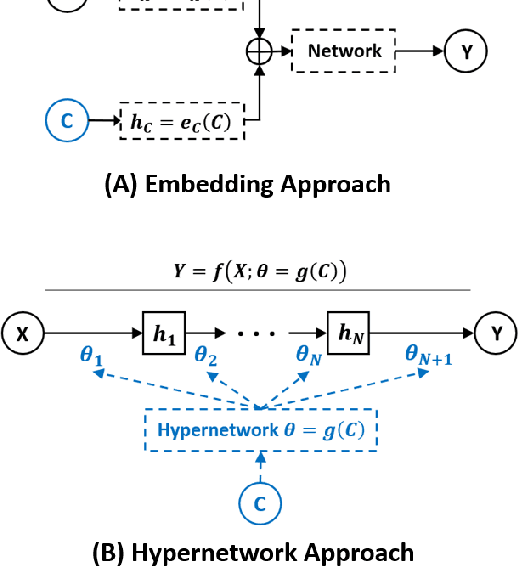
The task of predicting stochastic behaviors of road agents in diverse environments is a challenging problem for autonomous driving. To best understand scene contexts and produce diverse possible future states of the road agents adaptively in different environments, a prediction model should be probabilistic, multi-modal, context-driven, and general. We present Conditionalizing Variational AutoEncoders via Hypernetworks (CVAE-H); a conditional VAE that extensively leverages hypernetwork and performs generative tasks for high-dimensional problems like the prediction task. We first evaluate CVAE-H on simple generative experiments to show that CVAE-H is probabilistic, multi-modal, context-driven, and general. Then, we demonstrate that the proposed model effectively solves a self-driving prediction problem by producing accurate predictions of road agents in various environments.
Prior Is All You Need to Improve the Robustness and Safety for the First Time Deployment of Meta RL
Aug 19, 2021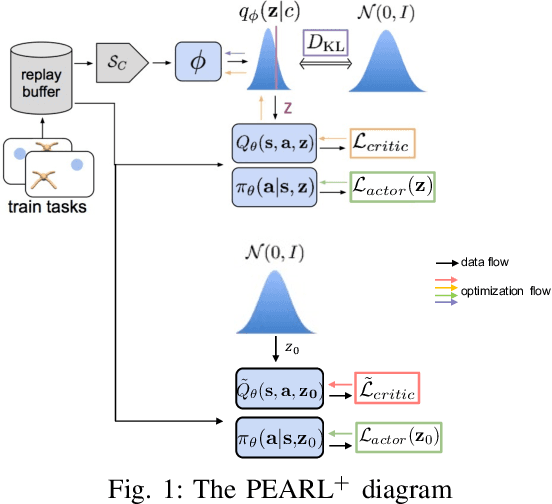

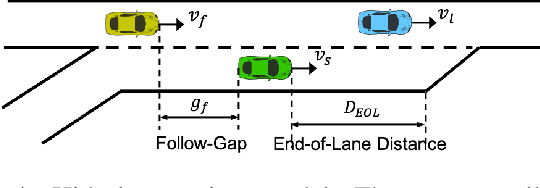
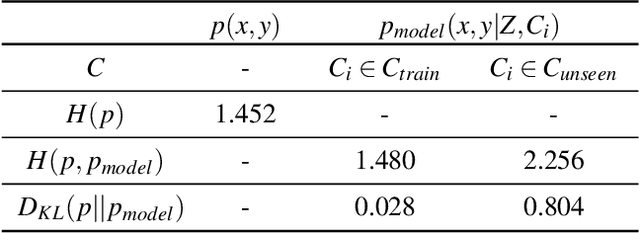
The field of Meta Reinforcement Learning (Meta-RL) has seen substantial advancements recently. In particular, off-policy methods were developed to improve the data efficiency of Meta-RL techniques. \textit{Probabilistic embeddings for actor-critic RL} (PEARL) is currently one of the leading approaches for multi-MDP adaptation problems. A major drawback of many existing Meta-RL methods, including PEARL, is that they do not explicitly consider the safety of the prior policy when it is exposed to a new task for the very first time. This is very important for some real-world applications, including field robots and Autonomous Vehicles (AVs). In this paper, we develop the PEARL PLUS (PEARL$^+$) algorithm, which optimizes the policy for both prior safety and posterior adaptation. Building on top of PEARL, our proposed PEARL$^+$ algorithm introduces a prior regularization term in the reward function and a new Q-network for recovering the state-action value with prior context assumption, to improve the robustness and safety of the trained network exposing to a new task for the first time. The performance of the PEARL$^+$ method is demonstrated by solving three safety-critical decision-making problems related to robots and AVs, including two MuJoCo benchmark problems. From the simulation experiments, we show that the safety of the prior policy is significantly improved compared to that of the original PEARL method.
Correspondence-Free Point Cloud Registration with SO(3)-Equivariant Implicit Shape Representations
Jul 21, 2021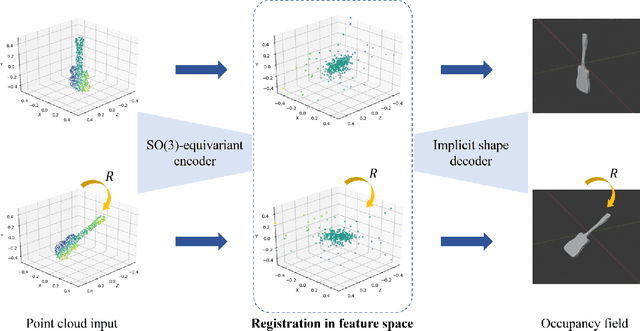
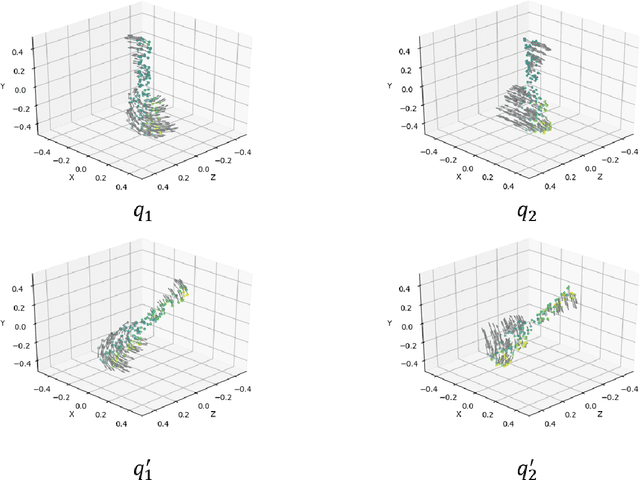

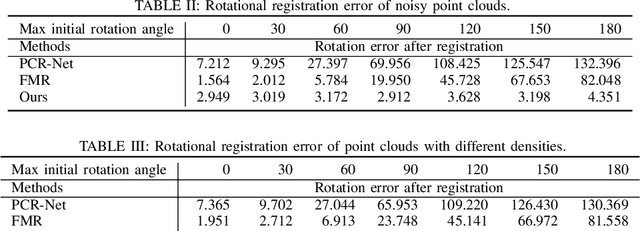
This paper proposes a correspondence-free method for point cloud rotational registration. We learn an embedding for each point cloud in a feature space that preserves the SO(3)-equivariance property, enabled by recent developments in equivariant neural networks. The proposed shape registration method achieves three major advantages through combining equivariant feature learning with implicit shape models. First, the necessity of data association is removed because of the permutation-invariant property in network architectures similar to PointNet. Second, the registration in feature space can be solved in closed-form using Horn's method due to the SO(3)-equivariance property. Third, the registration is robust to noise in the point cloud because of implicit shape learning. The experimental results show superior performance compared with existing correspondence-free deep registration methods.
Real-time Semantic 3D Dense Occupancy Mapping with Efficient Free Space Representations
Jul 07, 2021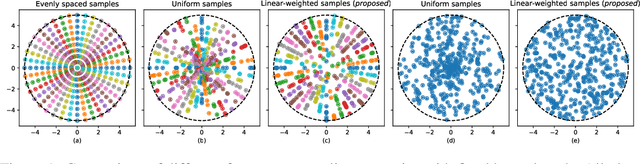

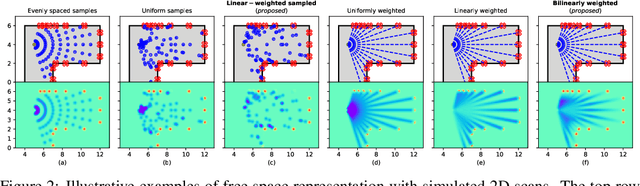
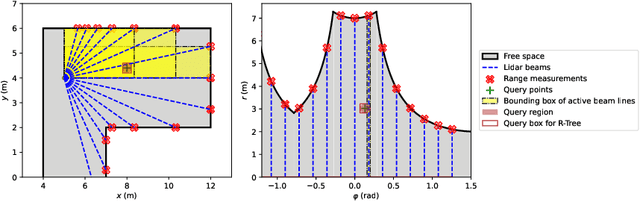
A real-time semantic 3D occupancy mapping framework is proposed in this paper. The mapping framework is based on the Bayesian kernel inference strategy from the literature. Two novel free space representations are proposed to efficiently construct training data and improve the mapping speed, which is a major bottleneck for real-world deployments. Our method achieves real-time mapping even on a consumer-grade CPU. Another important benefit is that our method can handle dynamic scenarios, thanks to the coverage completeness of the proposed algorithm. Experiments on real-world point cloud scan datasets are presented.
VIN: Voxel-based Implicit Network for Joint 3D Object Detection and Segmentation for Lidars
Jul 07, 2021
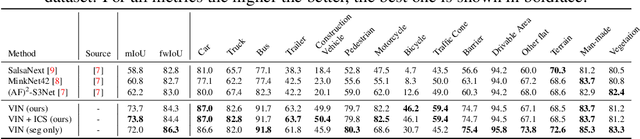
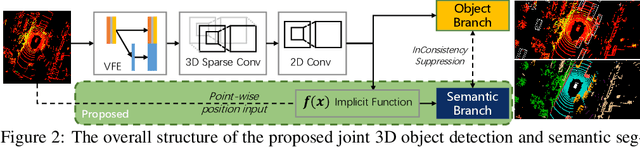
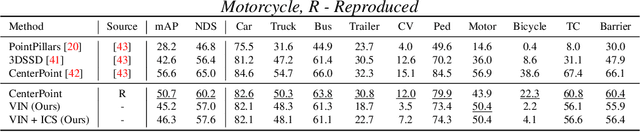
A unified neural network structure is presented for joint 3D object detection and point cloud segmentation in this paper. We leverage rich supervision from both detection and segmentation labels rather than using just one of them. In addition, an extension based on single-stage object detectors is proposed based on the implicit function widely used in 3D scene and object understanding. The extension branch takes the final feature map from the object detection module as input, and produces an implicit function that generates semantic distribution for each point for its corresponding voxel center. We demonstrated the performance of our structure on nuScenes-lidarseg, a large-scale outdoor dataset. Our solution achieves competitive results against state-of-the-art methods in both 3D object detection and point cloud segmentation with little additional computation load compared with object detection solutions. The capability of efficient weakly supervision semantic segmentation of the proposed method is also validated by experiments.
Quick Learner Automated Vehicle Adapting its Roadmanship to Varying Traffic Cultures with Meta Reinforcement Learning
Apr 18, 2021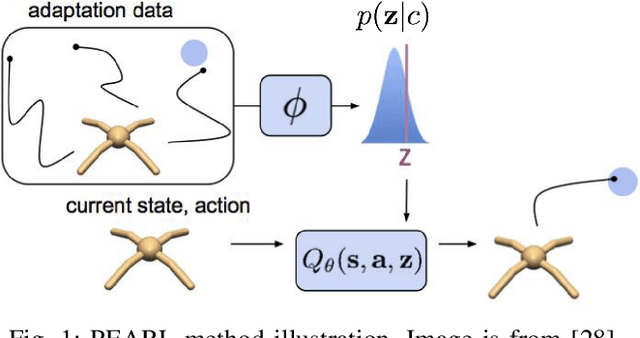

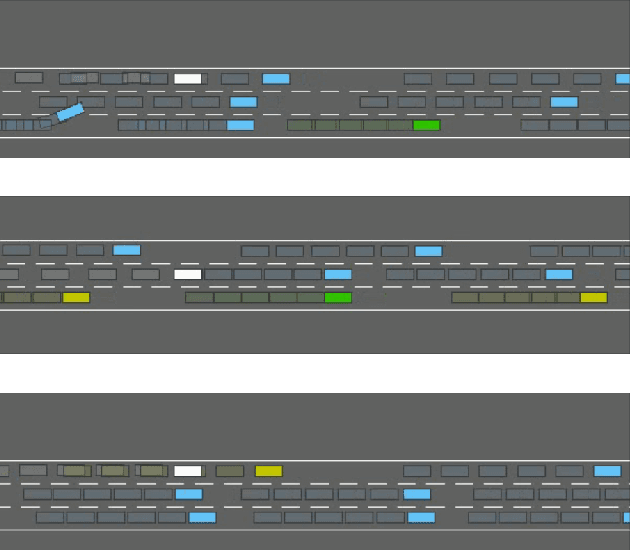
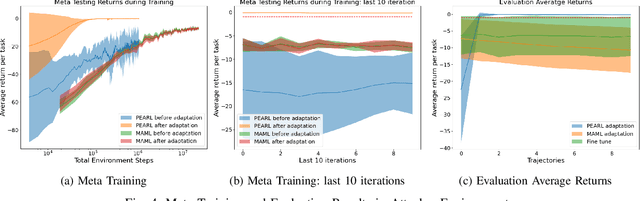
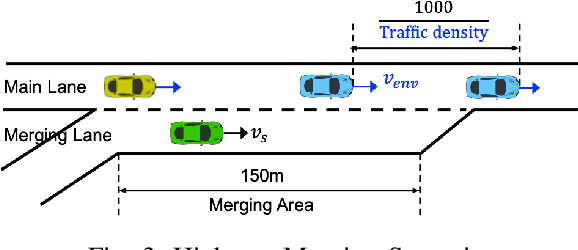
It is essential for an automated vehicle in the field to perform discretionary lane changes with appropriate roadmanship - driving safely and efficiently without annoying or endangering other road users - under a wide range of traffic cultures and driving conditions. While deep reinforcement learning methods have excelled in recent years and been applied to automated vehicle driving policy, there are concerns about their capability to quickly adapt to unseen traffic with new environment dynamics. We formulate this challenge as a multi-Markov Decision Processes (MDPs) adaptation problem and developed Meta Reinforcement Learning (MRL) driving policies to showcase their quick learning capability. Two types of distribution variation in environments were designed and simulated to validate the fast adaptation capability of resulting MRL driving policies which significantly outperform a baseline RL.
Monocular 3D Vehicle Detection Using Uncalibrated Traffic Cameras through Homography
Mar 29, 2021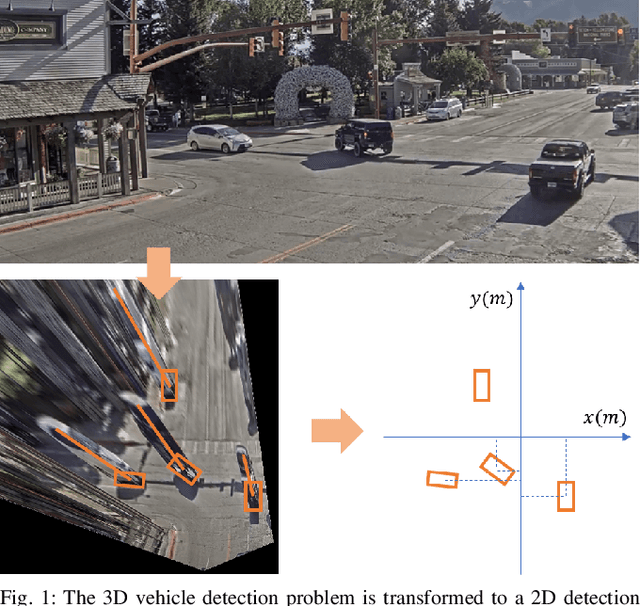
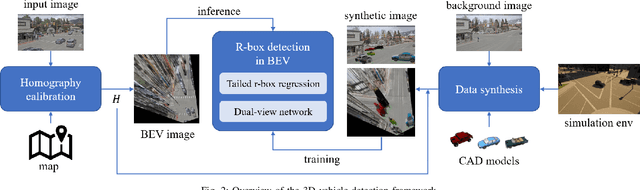

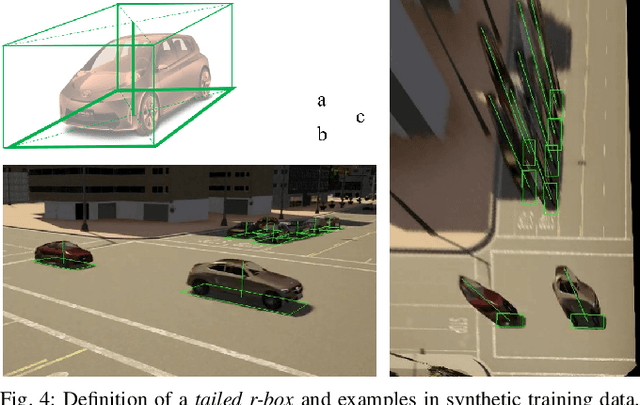
This paper proposes a method to extract the position and pose of vehicles in the 3D world from a single traffic camera. Most previous monocular 3D vehicle detection algorithms focused on cameras on vehicles from the perspective of a driver, and assumed known intrinsic and extrinsic calibration. On the contrary, this paper focuses on the same task using uncalibrated monocular traffic cameras. We observe that the homography between the road plane and the image plane is essential to 3D vehicle detection and the data synthesis for this task, and the homography can be estimated without the camera intrinsics and extrinsics. We conduct 3D vehicle detection by estimating the rotated bounding boxes (r-boxes) in the bird's eye view (BEV) images generated from inverse perspective mapping. We propose a new regression target called \textit{tailed~r-box} and a \textit{dual-view} network architecture which boosts the detection accuracy on warped BEV images. Experiments show that the proposed method can generalize to new camera and environment setups despite not seeing imaged from them during training.