 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving in Corner Case: A Real-World Adversarial Closed-Loop Evaluation Platform for End-to-End Autonomous Driving
Dec 18, 2025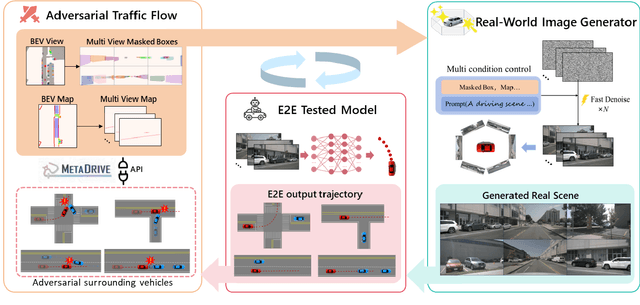
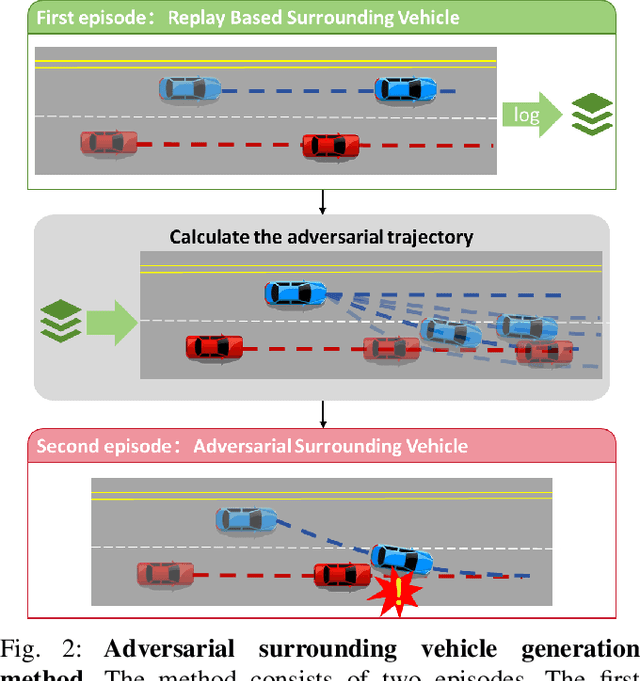
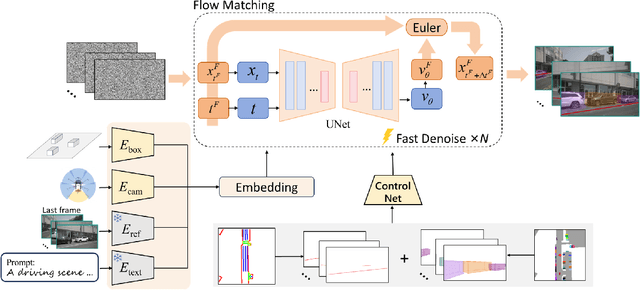

Safety-critical corner cases, difficult to collect in the real world, are crucial for evaluating end-to-end autonomous driving. Adversarial interaction is an effective method to generate such safety-critical corner cases. While existing adversarial evaluation methods are built for models operating in simplified simulation environments, adversarial evaluation for real-world end-to-end autonomous driving has been little explored. To address this challenge, we propose a closed-loop evaluation platform for end-to-end autonomous driving, which can generate adversarial interactions in real-world scenes. In our platform, the real-world image generator cooperates with an adversarial traffic policy to evaluate various end-to-end models trained on real-world data. The generator, based on flow matching, efficiently and stably generates real-world images according to the traffic environment information. The efficient adversarial surrounding vehicle policy is designed to model challenging interactions and create corner cases that current autonomous driving systems struggle to handle. Experimental results demonstrate that the platform can generate realistic driving images efficiently. Through evaluating the end-to-end models such as UniAD and VAD, we demonstrate that based on the adversarial policy, our platform evaluates the performance degradation of the tested model in corner cases. This result indicates that this platform can effectively detect the model's potential issues, which will facilitate the safety and robustness of end-to-end autonomous driving.
LiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception
Mar 21, 2023There is a recent trend in the LiDAR perception field towards unifying multiple tasks in a single strong network with improved performance, as opposed to using separate networks for each task. In this paper, we introduce a new LiDAR multi-task learning paradigm based on the transformer. The proposed LiDARFormer utilizes cross-space global contextual feature information and exploits cross-task synergy to boost the performance of LiDAR perception tasks across multiple large-scale datasets and benchmarks. Our novel transformer-based framework includes a cross-space transformer module that learns attentive features between the 2D dense Bird's Eye View (BEV) and 3D sparse voxel feature maps. Additionally, we propose a transformer decoder for the segmentation task to dynamically adjust the learned features by leveraging the categorical feature representations. Furthermore, we combine the segmentation and detection features in a shared transformer decoder with cross-task attention layers to enhance and integrate the object-level and class-level features. LiDARFormer is evaluated on the large-scale nuScenes and the Waymo Open datasets for both 3D detection and semantic segmentation tasks, and it outperforms all previously published methods on both tasks. Notably, LiDARFormer achieves the state-of-the-art performance of 76.4% L2 mAPH and 74.3% NDS on the challenging Waymo and nuScenes detection benchmarks for a single model LiDAR-only method.
MonoEdge: Monocular 3D Object Detection Using Local Perspectives
Jan 04, 2023We propose a novel approach for monocular 3D object detection by leveraging local perspective effects of each object. While the global perspective effect shown as size and position variations has been exploited for monocular 3D detection extensively, the local perspectives has long been overlooked. We design a local perspective module to regress a newly defined variable named keyedge-ratios as the parameterization of the local shape distortion to account for the local perspective, and derive the object depth and yaw angle from it. Theoretically, this module does not rely on the pixel-wise size or position in the image of the objects, therefore independent of the camera intrinsic parameters. By plugging this module in existing monocular 3D object detection frameworks, we incorporate the local perspective distortion with global perspective effect for monocular 3D reasoning, and we demonstrate the effectiveness and superior performance over strong baseline methods in multiple datasets.
LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception
Sep 19, 2022
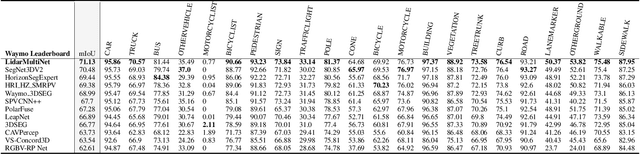
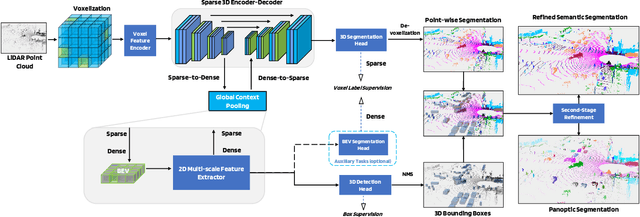

LiDAR-based 3D object detection, semantic segmentation, and panoptic segmentation are usually implemented in specialized networks with distinctive architectures that are difficult to adapt to each other. This paper presents LidarMultiNet, a LiDAR-based multi-task network that unifies these three major LiDAR perception tasks. Among its many benefits, a multi-task network can reduce the overall cost by sharing weights and computation among multiple tasks. However, it typically underperforms compared to independently combined single-task models. The proposed LidarMultiNet aims to bridge the performance gap between the multi-task network and multiple single-task networks. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder architecture with a Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame. Task-specific heads are added on top of the network to perform the three LiDAR perception tasks. More tasks can be implemented simply by adding new task-specific heads while introducing little additional cost. A second stage is also proposed to refine the first-stage segmentation and generate accurate panoptic segmentation results. LidarMultiNet is extensively tested on both Waymo Open Dataset and nuScenes dataset, demonstrating for the first time that major LiDAR perception tasks can be unified in a single strong network that is trained end-to-end and achieves state-of-the-art performance. Notably, LidarMultiNet reaches the official 1st place in the Waymo Open Dataset 3D semantic segmentation challenge 2022 with the highest mIoU and the best accuracy for most of the 22 classes on the test set, using only LiDAR points as input. It also sets the new state-of-the-art for a single model on the Waymo 3D object detection benchmark and three nuScenes benchmarks.
CenterFormer: Center-based Transformer for 3D Object Detection
Sep 12, 2022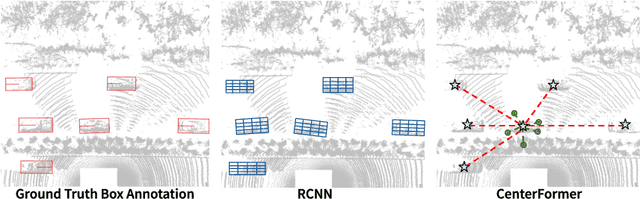
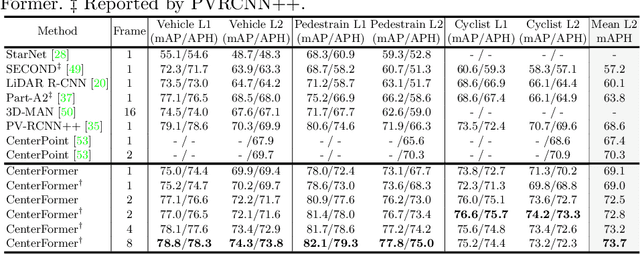
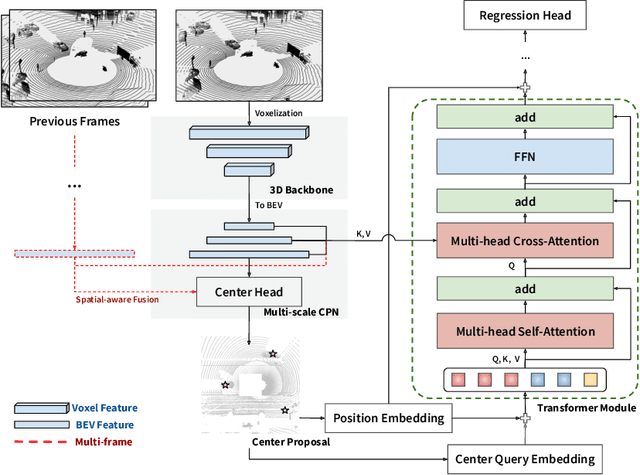
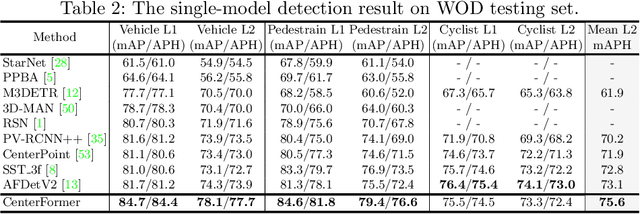
Query-based transformer has shown great potential in constructing long-range attention in many image-domain tasks, but has rarely been considered in LiDAR-based 3D object detection due to the overwhelming size of the point cloud data. In this paper, we propose CenterFormer, a center-based transformer network for 3D object detection. CenterFormer first uses a center heatmap to select center candidates on top of a standard voxel-based point cloud encoder. It then uses the feature of the center candidate as the query embedding in the transformer. To further aggregate features from multiple frames, we design an approach to fuse features through cross-attention. Lastly, regression heads are added to predict the bounding box on the output center feature representation. Our design reduces the convergence difficulty and computational complexity of the transformer structure. The results show significant improvements over the strong baseline of anchor-free object detection networks. CenterFormer achieves state-of-the-art performance for a single model on the Waymo Open Dataset, with 73.7% mAPH on the validation set and 75.6% mAPH on the test set, significantly outperforming all previously published CNN and transformer-based methods. Our code is publicly available at https://github.com/TuSimple/centerformer
LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 24, 2022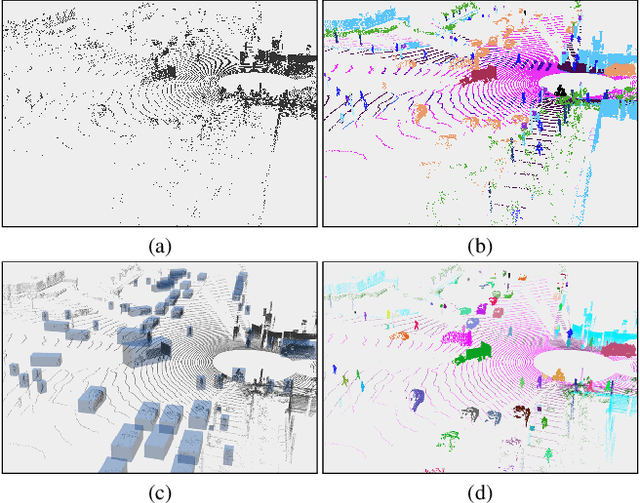
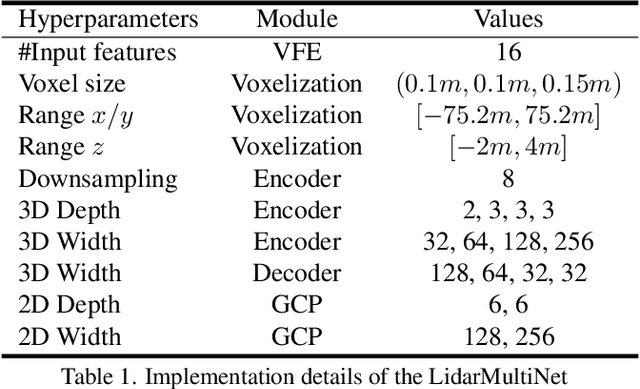
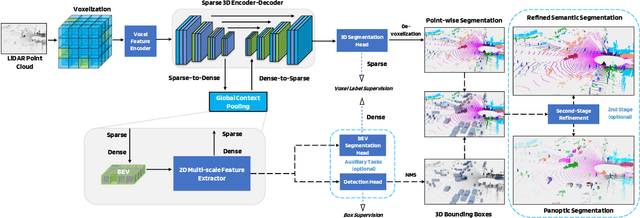
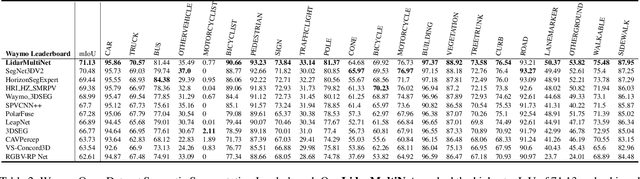
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
ES-Net: An Efficient Stereo Matching Network
Mar 05, 2021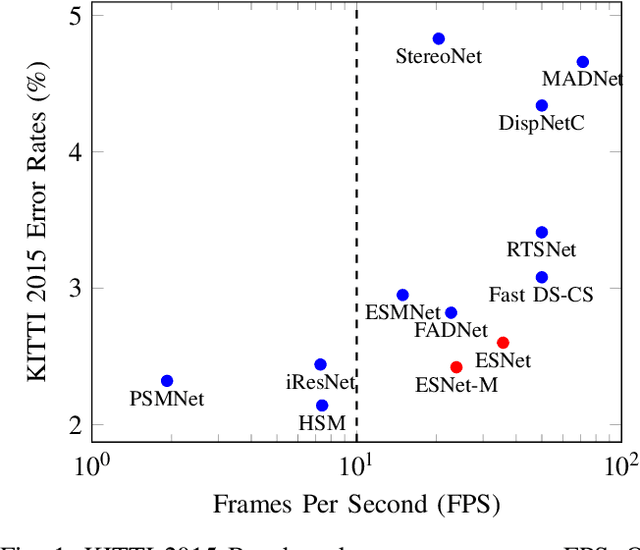
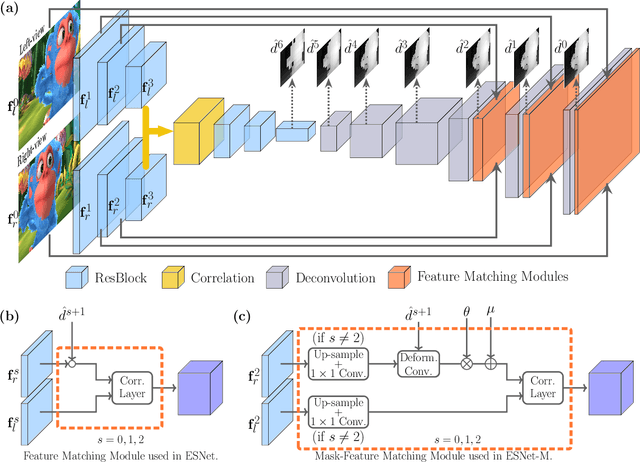

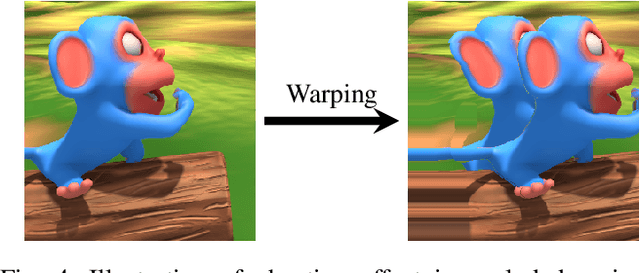
Dense stereo matching with deep neural networks is of great interest to the research community. Existing stereo matching networks typically use slow and computationally expensive 3D convolutions to improve the performance, which is not friendly to real-world applications such as autonomous driving. In this paper, we propose the Efficient Stereo Network (ESNet), which achieves high performance and efficient inference at the same time. ESNet relies only on 2D convolution and computes multi-scale cost volume efficiently using a warping-based method to improve the performance in regions with fine-details. In addition, we address the matching ambiguity issue in the occluded region by proposing ESNet-M, a variant of ESNet that additionally estimates an occlusion mask without supervision. We further improve the network performance by proposing a new training scheme that includes dataset scheduling and unsupervised pre-training. Compared with other low-cost dense stereo depth estimation methods, our proposed approach achieves state-of-the-art performance on the Scene Flow [1], DrivingStereo [2], and KITTI-2015 dataset [3]. Our code will be made available.
Grid-GCN for Fast and Scalable Point Cloud Learning
Dec 20, 2019



Due to the sparsity and irregularity of the point cloud data, methods that directly consume points have become popular. Among all point-based models, graph convolutional networks (GCN) lead to notable performance by fully preserving the data granularity and exploiting point interrelation. However, point-based networks spend a significant amount of time on data structuring (e.g., Farthest Point Sampling (FPS) and neighbor points querying), which limit the speed and scalability. In this paper, we present a method, named Grid-GCN, for fast and scalable point cloud learning. Grid-GCN uses a novel data structuring strategy, Coverage-Aware Grid Query (CAGQ). By leveraging the efficiency of grid space, CAGQ improves spatial coverage while reducing the theoretical time complexity. Compared with popular sampling methods such as Farthest Point Sampling (FPS) and Ball Query, CAGQ achieves up to 50X speed-up. With a Grid Context Aggregation (GCA) module, Grid-GCN achieves state-of-the-art performance on major point cloud classification and segmentation benchmarks with significantly faster runtime than previous studies. Remarkably, Grid-GCN achieves the inference speed of 50fps on ScanNet using 81920 points per scene as input.
HPLFlowNet: Hierarchical Permutohedral Lattice FlowNet for Scene Flow Estimation on Large-scale Point Clouds
Jun 12, 2019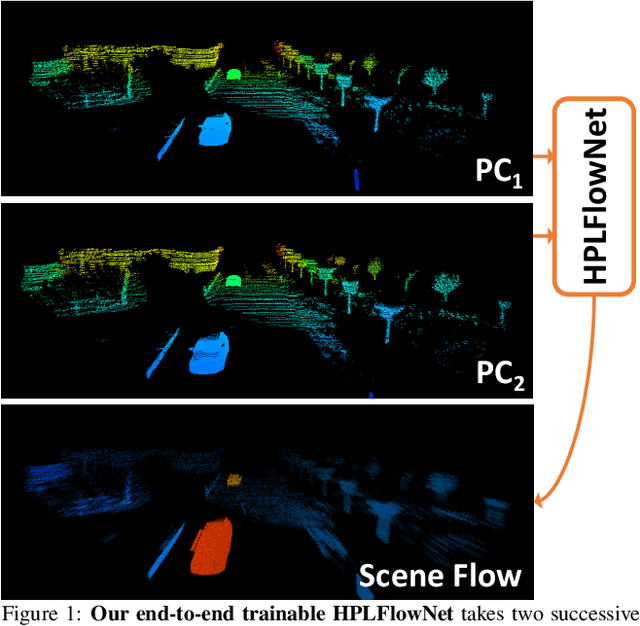


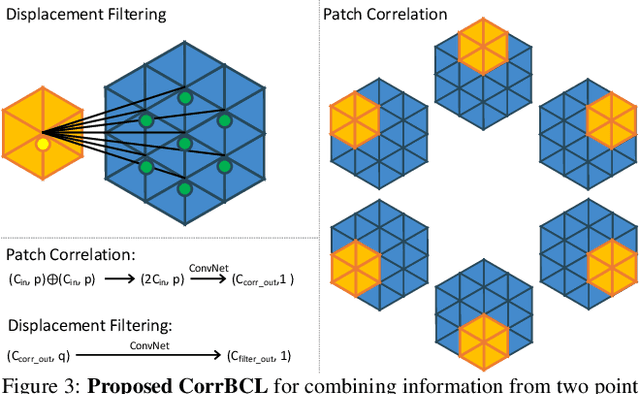
We present a novel deep neural network architecture for end-to-end scene flow estimation that directly operates on large-scale 3D point clouds. Inspired by Bilateral Convolutional Layers (BCL), we propose novel DownBCL, UpBCL, and CorrBCL operations that restore structural information from unstructured point clouds, and fuse information from two consecutive point clouds. Operating on discrete and sparse permutohedral lattice points, our architectural design is parsimonious in computational cost. Our model can efficiently process a pair of point cloud frames at once with a maximum of 86K points per frame. Our approach achieves state-of-the-art performance on the FlyingThings3D and KITTI Scene Flow 2015 datasets. Moreover, trained on synthetic data, our approach shows great generalization ability on real-world data and on different point densities without fine-tuning.
Understanding Convolution for Semantic Segmentation
Jun 01, 2018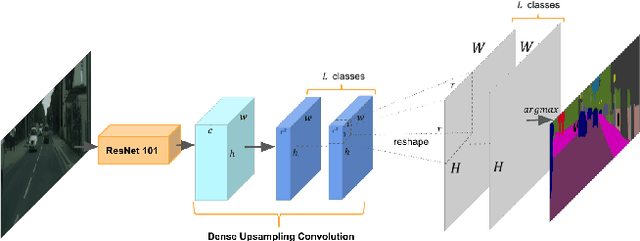
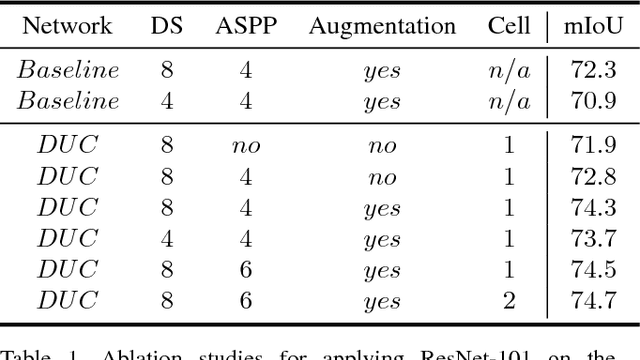
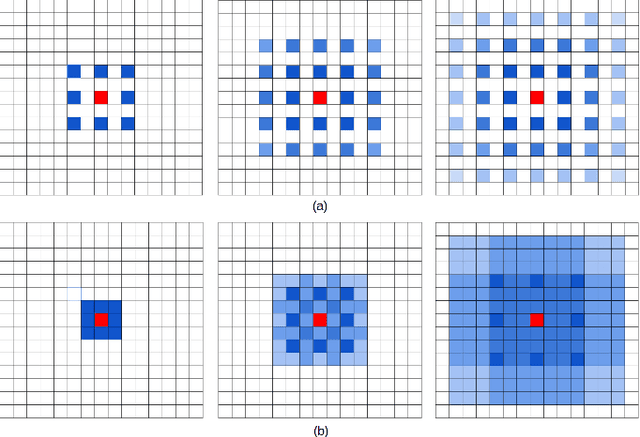
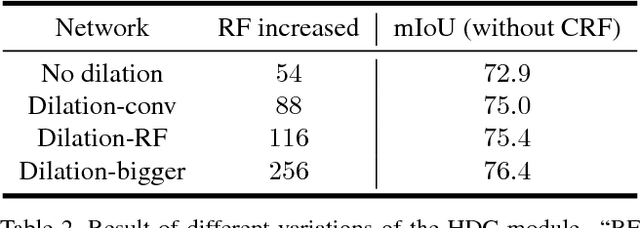
Recent advances in deep learning, especially deep convolutional neural networks (CNNs), have led to significant improvement over previous semantic segmentation systems. Here we show how to improve pixel-wise semantic segmentation by manipulating convolution-related operations that are of both theoretical and practical value. First, we design dense upsampling convolution (DUC) to generate pixel-level prediction, which is able to capture and decode more detailed information that is generally missing in bilinear upsampling. Second, we propose a hybrid dilated convolution (HDC) framework in the encoding phase. This framework 1) effectively enlarges the receptive fields (RF) of the network to aggregate global information; 2) alleviates what we call the "gridding issue" caused by the standard dilated convolution operation. We evaluate our approaches thoroughly on the Cityscapes dataset, and achieve a state-of-art result of 80.1% mIOU in the test set at the time of submission. We also have achieved state-of-the-art overall on the KITTI road estimation benchmark and the PASCAL VOC2012 segmentation task. Our source code can be found at https://github.com/TuSimple/TuSimple-DUC .