 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Imitation to Intuition: Intrinsic Reasoning for Open-Instance Video Classification
Mar 11, 2026Conventional video classification models, acting as effective imitators, excel in scenarios with homogeneous data distributions. However, real-world applications often present an open-instance challenge, where intra-class variations are vast and complex, beyond existing benchmarks. While traditional video encoder models struggle to fit these diverse distributions, vision-language models (VLMs) offer superior generalization but have not fully leveraged their reasoning capabilities (intuition) for such tasks. In this paper, we bridge this gap with an intrinsic reasoning framework that evolves open-instance video classification from imitation to intuition. Our approach, namely DeepIntuit, begins with a cold-start supervised alignment to initialize reasoning capability, followed by refinement using Group Relative Policy Optimization (GRPO) to enhance reasoning coherence through reinforcement learning. Crucially, to translate this reasoning into accurate classification, DeepIntuit then introduces an intuitive calibration stage. In this stage, a classifier is trained on this intrinsic reasoning traces generated by the refined VLM, ensuring stable knowledge transfer without distribution mismatch. Extensive experiments demonstrate that for open-instance video classification, DeepIntuit benefits significantly from transcending simple feature imitation and evolving toward intrinsic reasoning. Our project is available at https://bwgzk-keke.github.io/DeepIntuit/.
HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023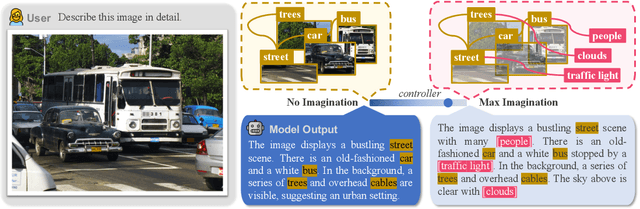
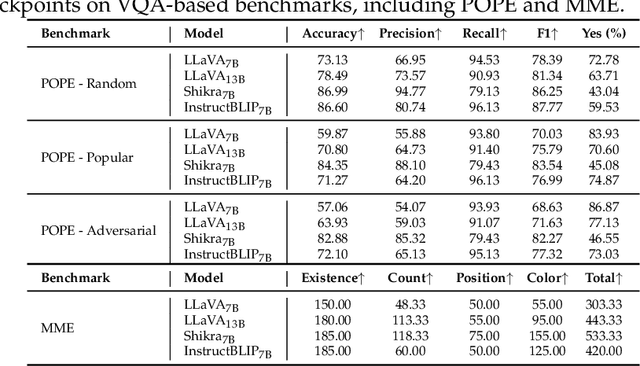

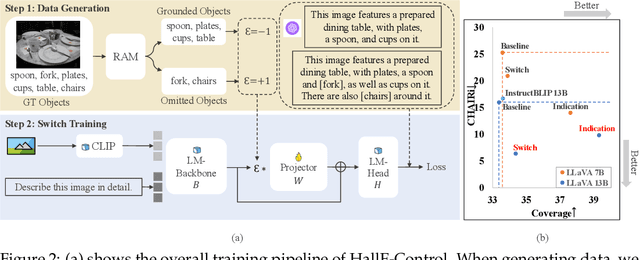
Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.
CenterFormer: Center-based Transformer for 3D Object Detection
Sep 12, 2022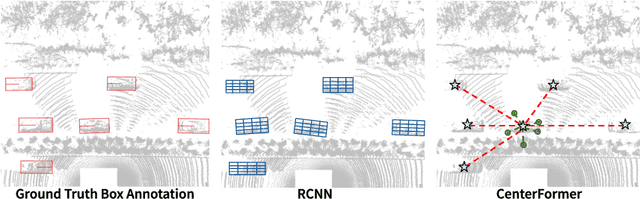
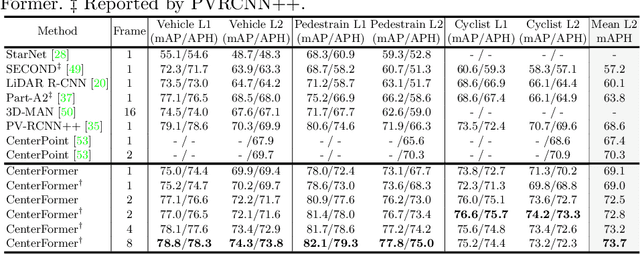
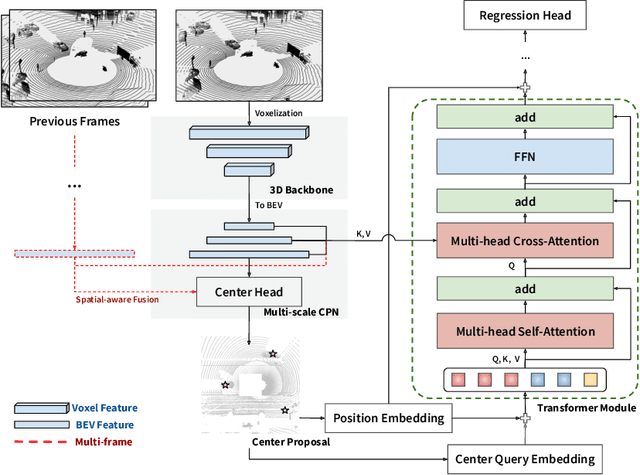
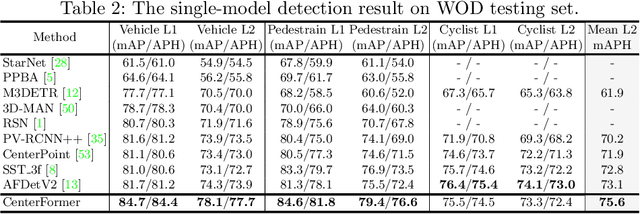
Query-based transformer has shown great potential in constructing long-range attention in many image-domain tasks, but has rarely been considered in LiDAR-based 3D object detection due to the overwhelming size of the point cloud data. In this paper, we propose CenterFormer, a center-based transformer network for 3D object detection. CenterFormer first uses a center heatmap to select center candidates on top of a standard voxel-based point cloud encoder. It then uses the feature of the center candidate as the query embedding in the transformer. To further aggregate features from multiple frames, we design an approach to fuse features through cross-attention. Lastly, regression heads are added to predict the bounding box on the output center feature representation. Our design reduces the convergence difficulty and computational complexity of the transformer structure. The results show significant improvements over the strong baseline of anchor-free object detection networks. CenterFormer achieves state-of-the-art performance for a single model on the Waymo Open Dataset, with 73.7% mAPH on the validation set and 75.6% mAPH on the test set, significantly outperforming all previously published CNN and transformer-based methods. Our code is publicly available at https://github.com/TuSimple/centerformer