 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents
Jan 28, 2026Tool-calling agents are increasingly deployed in real-world customer-facing workflows. Yet most studies on tool-calling agents focus on idealized settings with general, fixed, and well-specified tasks. In real-world applications, user requests are often (1) ambiguous, (2) changing over time, or (3) infeasible due to policy constraints, and training and evaluation data that cover these diverse, complex interaction patterns remain under-represented. To bridge the gap, we present Trajectory2Task, a verifiable data generation pipeline for studying tool use at scale under three realistic user scenarios: ambiguous intent, changing intent, and infeasible intents. The pipeline first conducts multi-turn exploration to produce valid tool-call trajectories. It then converts these trajectories into user-facing tasks with controlled intent adaptations. This process yields verifiable task that support closed-loop evaluation and training. We benchmark seven state-of-the-art LLMs on the generated complex user scenario tasks and observe frequent failures. Finally, using successful trajectories obtained from task rollouts, we fine-tune lightweight LLMs and find consistent improvements across all three conditions, along with better generalization to unseen tool-use domains, indicating stronger general tool-calling ability.
Artificial Entanglement in the Fine-Tuning of Large Language Models
Jan 11, 2026Large language models (LLMs) can be adapted to new tasks using parameter-efficient fine-tuning (PEFT) methods that modify only a small number of trainable parameters, often through low-rank updates. In this work, we adopt a quantum-information-inspired perspective to understand their effectiveness. From this perspective, low-rank parameterizations naturally correspond to low-dimensional Matrix Product States (MPS) representations, which enable entanglement-based characterizations of parameter structure. Thereby, we term and measure "Artificial Entanglement", defined as the entanglement entropy of the parameters in artificial neural networks (in particular the LLMs). We first study the representative low-rank adaptation (LoRA) PEFT method, alongside full fine-tuning (FFT), using LLaMA models at the 1B and 8B scales trained on the Tulu3 and OpenThoughts3 datasets, and uncover: (i) Internal artificial entanglement in the updates of query and value projection matrices in LoRA follows a volume law with a central suppression (termed as the "Entanglement Valley"), which is sensitive to hyper-parameters and is distinct from that in FFT; (ii) External artificial entanglement in attention matrices, corresponding to token-token correlations in representation space, follows an area law with logarithmic corrections and remains robust to LoRA hyper-parameters and training steps. Drawing a parallel to the No-Hair Theorem in black hole physics, we propose that although LoRA and FFT induce distinct internal entanglement signatures, such differences do not manifest in the attention outputs, suggesting a "no-hair" property that results in the effectiveness of low rank updates. We further provide theoretical support based on random matrix theory, and extend our analysis to an MPS Adaptation PEFT method, which exhibits qualitatively similar behaviors.
Adaptation of Agentic AI
Dec 22, 2025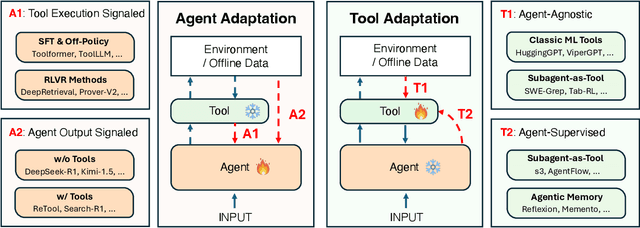
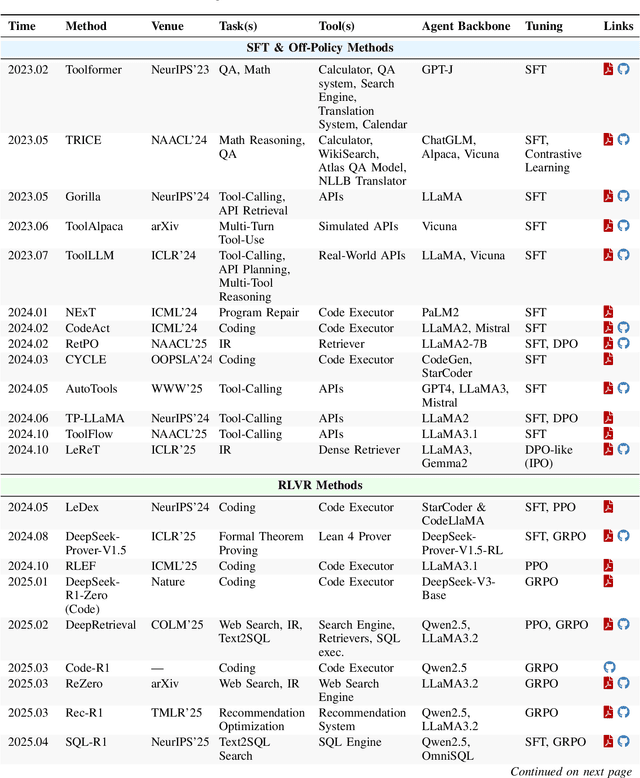
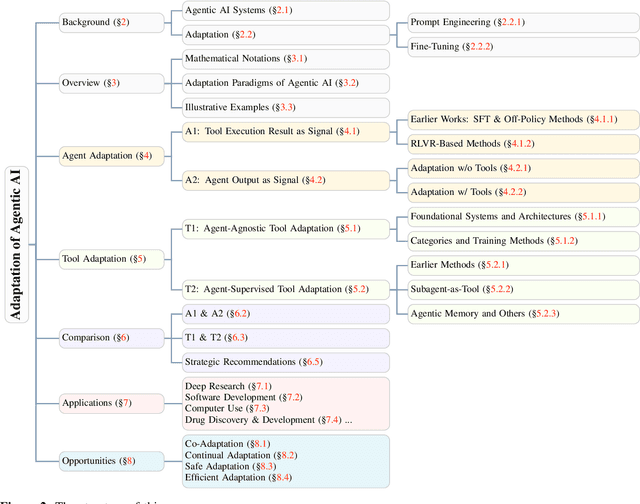
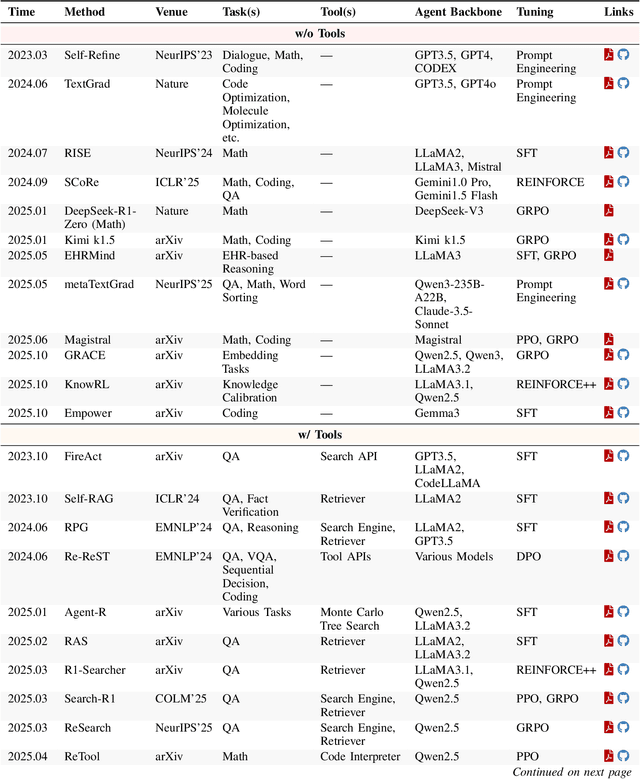
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025



LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Spatial Mental Modeling from Limited Views
Jun 26, 2025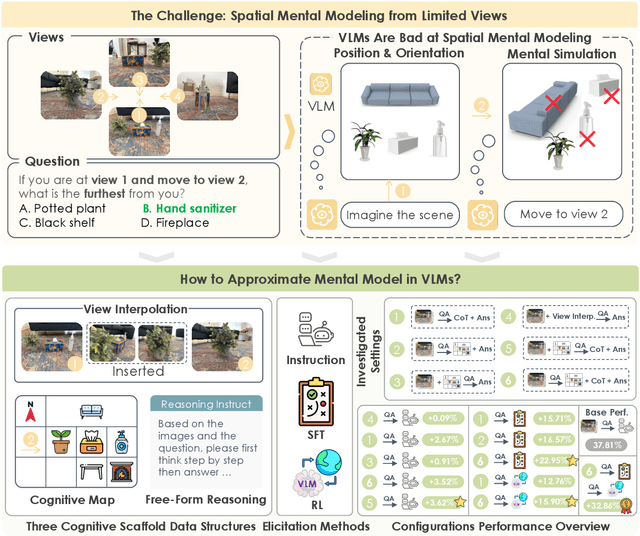

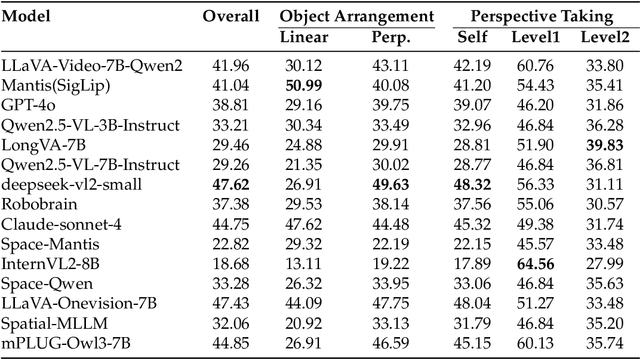
Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.