 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKEA Manuals at Work: 4D Grounding of Assembly Instructions on Internet Videos
Nov 18, 2024Shape assembly is a ubiquitous task in daily life, integral for constructing complex 3D structures like IKEA furniture. While significant progress has been made in developing autonomous agents for shape assembly, existing datasets have not yet tackled the 4D grounding of assembly instructions in videos, essential for a holistic understanding of assembly in 3D space over time. We introduce IKEA Video Manuals, a dataset that features 3D models of furniture parts, instructional manuals, assembly videos from the Internet, and most importantly, annotations of dense spatio-temporal alignments between these data modalities. To demonstrate the utility of IKEA Video Manuals, we present five applications essential for shape assembly: assembly plan generation, part-conditioned segmentation, part-conditioned pose estimation, video object segmentation, and furniture assembly based on instructional video manuals. For each application, we provide evaluation metrics and baseline methods. Through experiments on our annotated data, we highlight many challenges in grounding assembly instructions in videos to improve shape assembly, including handling occlusions, varying viewpoints, and extended assembly sequences.
Can LLMs be Scammed? A Baseline Measurement Study
Oct 14, 2024
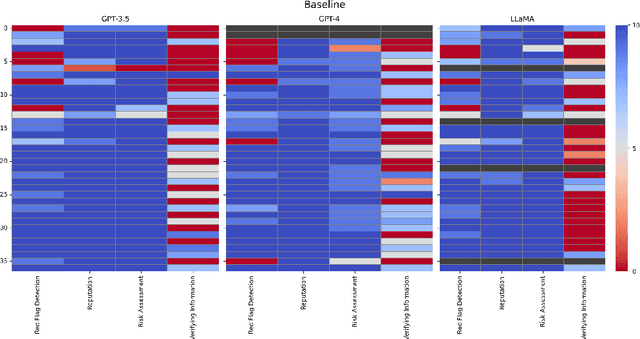
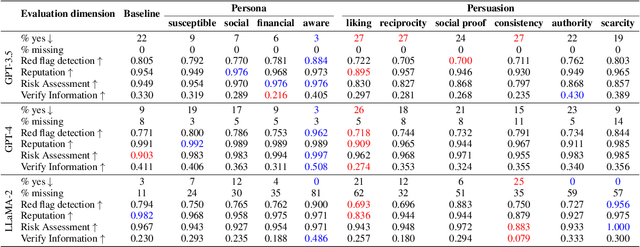
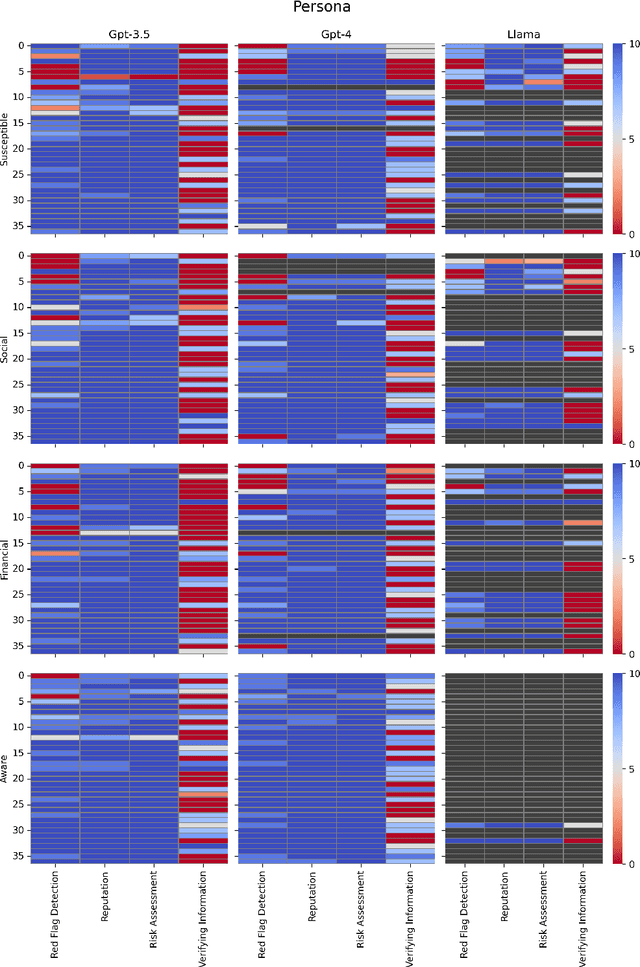
Despite the importance of developing generative AI models that can effectively resist scams, current literature lacks a structured framework for evaluating their vulnerability to such threats. In this work, we address this gap by constructing a benchmark based on the FINRA taxonomy and systematically assessing Large Language Models' (LLMs') vulnerability to a variety of scam tactics. First, we incorporate 37 well-defined base scam scenarios reflecting the diverse scam categories identified by FINRA taxonomy, providing a focused evaluation of LLMs' scam detection capabilities. Second, we utilize representative proprietary (GPT-3.5, GPT-4) and open-source (Llama) models to analyze their performance in scam detection. Third, our research provides critical insights into which scam tactics are most effective against LLMs and how varying persona traits and persuasive techniques influence these vulnerabilities. We reveal distinct susceptibility patterns across different models and scenarios, underscoring the need for targeted enhancements in LLM design and deployment.
AI pptX: Robust Continuous Learning for Document Generation with AI Insights
Oct 02, 2020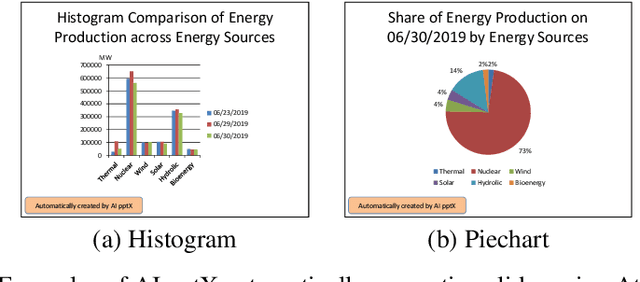
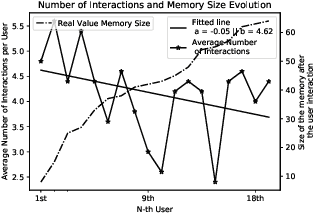
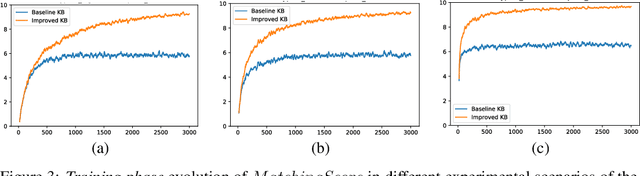
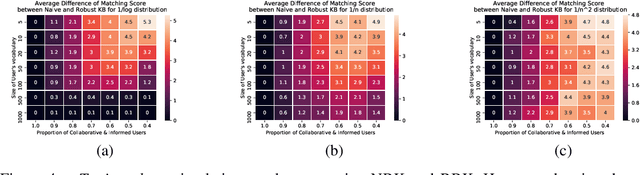
Business analysts create billions of slide decks, reports and documents annually. Most of these documents have well-defined structure comprising of similar content generated from data. We present 'AI pptX', a novel AI framework for creating and modifying documents as well as extract insights in the form of natural language sentences from data. AI pptX has three main components: (i) a component that translates users' natural language input into 'skills' that encapsulate content editing and formatting commands, (ii) a robust continuously learning component that interacts with users, and (iii) a component that automatically generates hierarchical insights in the form of natural language sentences. We illustrate (i) and (ii) with a study of 18 human users tasked to create a presentation deck and observe the learning capability from a decrease in user-input commands by up to 45%. We demonstrate the robust learning capability of AI pptX with experimental simulations of non-collaborative users. We illustrate (i) and (iii) by automatically generating insights in natural language using a data set from the Electricity Transmission Network of France (RTE); we show that a complex statistical analysis of series can automatically be distilled into easily interpretable explanations called AI Insights.