 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradeoffs in Streaming Binary Classification under Limited Inspection Resources
Oct 05, 2021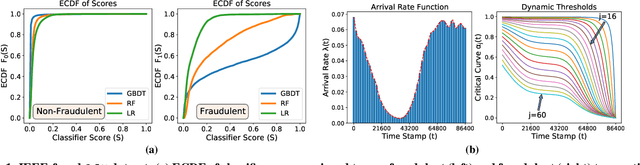
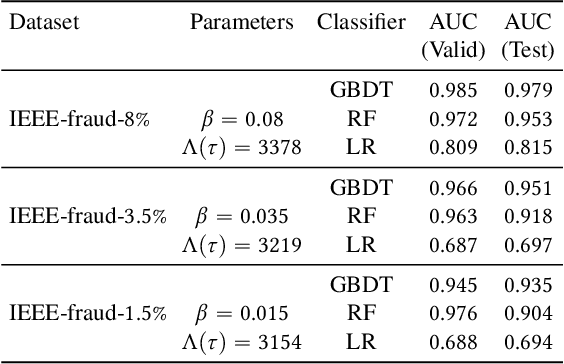
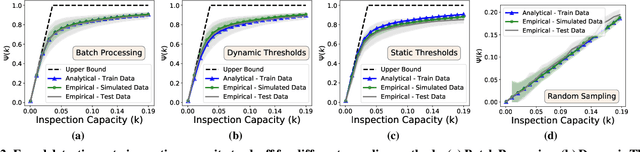
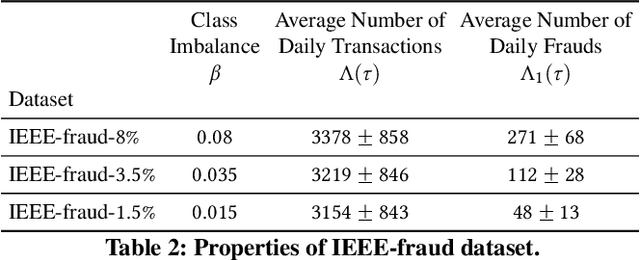
Institutions are increasingly relying on machine learning models to identify and alert on abnormal events, such as fraud, cyber attacks and system failures. These alerts often need to be manually investigated by specialists. Given the operational cost of manual inspections, the suspicious events are selected by alerting systems with carefully designed thresholds. In this paper, we consider an imbalanced binary classification problem, where events arrive sequentially and only a limited number of suspicious events can be inspected. We model the event arrivals as a non-homogeneous Poisson process, and compare various suspicious event selection methods including those based on static and adaptive thresholds. For each method, we analytically characterize the tradeoff between the minority-class detection rate and the inspection capacity as a function of the data class imbalance and the classifier confidence score densities. We implement the selection methods on a real public fraud detection dataset and compare the empirical results with analytical bounds. Finally, we investigate how class imbalance and the choice of classifier impact the tradeoff.
Non-Parametric Stochastic Sequential Assignment With Random Arrival Times
Jun 09, 2021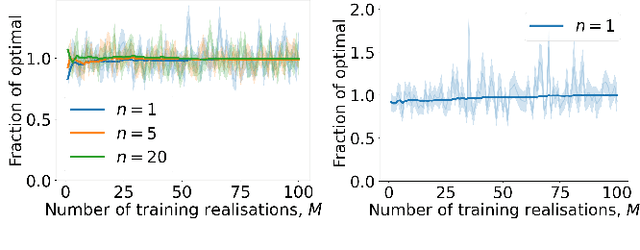

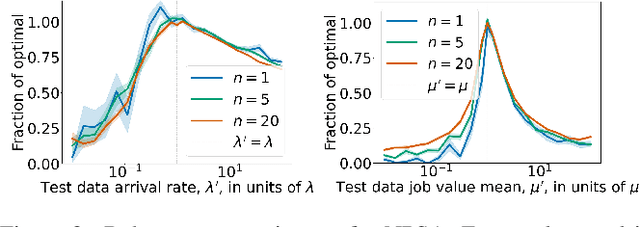

We consider a problem wherein jobs arrive at random times and assume random values. Upon each job arrival, the decision-maker must decide immediately whether or not to accept the job and gain the value on offer as a reward, with the constraint that they may only accept at most $n$ jobs over some reference time period. The decision-maker only has access to $M$ independent realisations of the job arrival process. We propose an algorithm, Non-Parametric Sequential Allocation (NPSA), for solving this problem. Moreover, we prove that the expected reward returned by the NPSA algorithm converges in probability to optimality as $M$ grows large. We demonstrate the effectiveness of the algorithm empirically on synthetic data and on public fraud-detection datasets, from where the motivation for this work is derived.
AI pptX: Robust Continuous Learning for Document Generation with AI Insights
Oct 02, 2020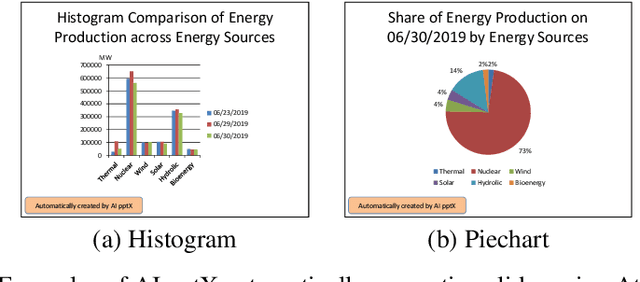
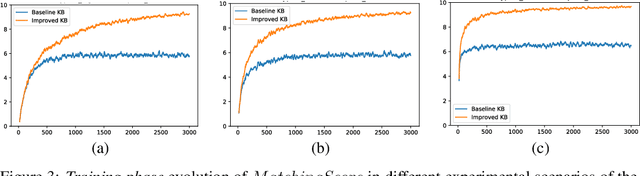
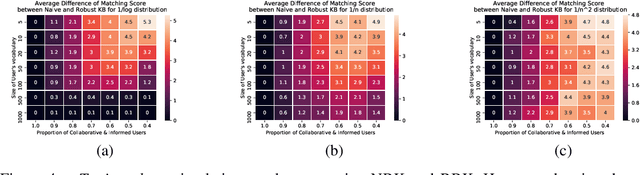
Business analysts create billions of slide decks, reports and documents annually. Most of these documents have well-defined structure comprising of similar content generated from data. We present 'AI pptX', a novel AI framework for creating and modifying documents as well as extract insights in the form of natural language sentences from data. AI pptX has three main components: (i) a component that translates users' natural language input into 'skills' that encapsulate content editing and formatting commands, (ii) a robust continuously learning component that interacts with users, and (iii) a component that automatically generates hierarchical insights in the form of natural language sentences. We illustrate (i) and (ii) with a study of 18 human users tasked to create a presentation deck and observe the learning capability from a decrease in user-input commands by up to 45%. We demonstrate the robust learning capability of AI pptX with experimental simulations of non-collaborative users. We illustrate (i) and (iii) by automatically generating insights in natural language using a data set from the Electricity Transmission Network of France (RTE); we show that a complex statistical analysis of series can automatically be distilled into easily interpretable explanations called AI Insights.
Calibration of Shared Equilibria in General Sum Partially Observable Markov Games
Jun 23, 2020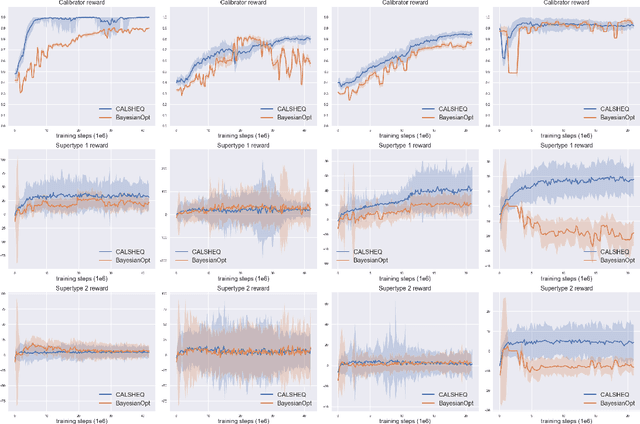
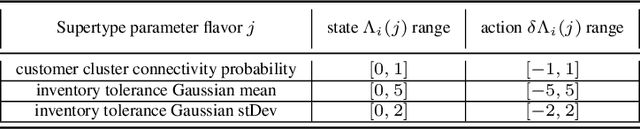
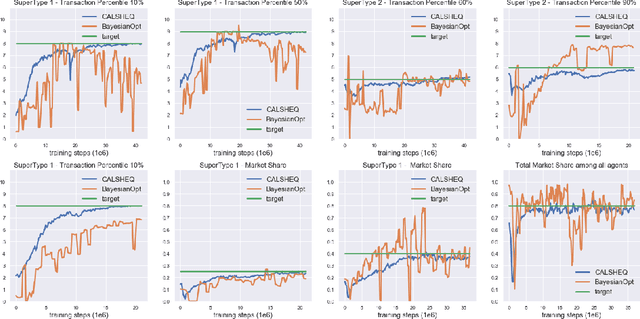
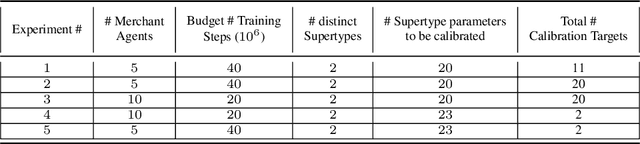
Training multi-agent systems (MAS) to achieve realistic equilibria gives us a useful tool to understand and model real-world systems. We consider a general sum partially observable Markov game where agents of different types share a single policy network, conditioned on agent-specific information. This paper aims at i) formally understanding equilibria reached by such agents, and ii) matching emergent phenomena of such equilibria to real-world targets. Parameter sharing with decentralized execution has been introduced as an efficient way to train multiple agents using a single policy network. However, the nature of resulting equilibria reached by such agents is not yet understood: we introduce the novel concept of \textit{Shared equilibrium} as a symmetric pure Nash equilibrium of a certain Functional Form Game (FFG) and prove convergence to the latter for a certain class of games using self-play. In addition, it is important that such equilibria satisfy certain constraints so that MAS are \textit{calibrated} to real world data for practical use: we solve this problem by introducing a novel dual-Reinforcement Learning based approach that fits emergent behaviors of agents in a Shared equilibrium to externally-specified targets, and apply our methods to a $n$-player market example. We do so by calibrating parameters governing distributions of agent types rather than individual agents, which allows both behavior differentiation among agents and coherent scaling of the shared policy network to multiple agents.
Risk-Sensitive Reinforcement Learning: a Martingale Approach to Reward Uncertainty
Jun 23, 2020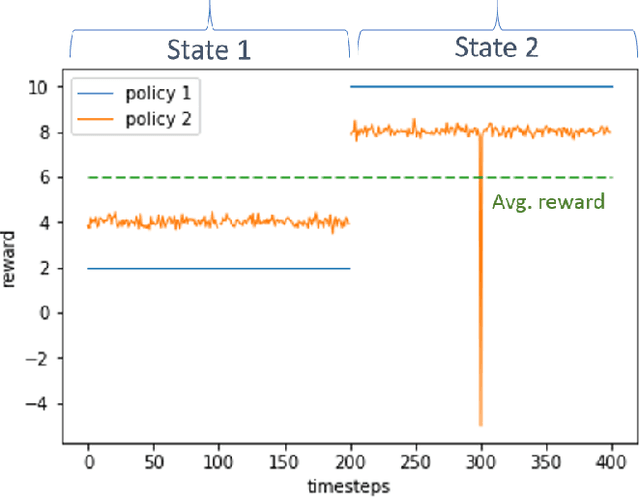
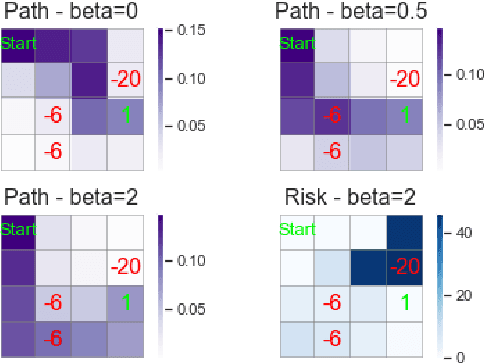

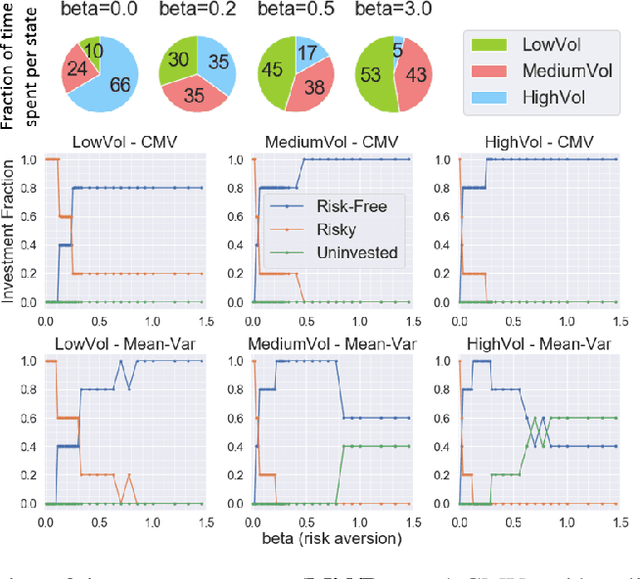
We introduce a novel framework to account for sensitivity to rewards uncertainty in sequential decision-making problems. While risk-sensitive formulations for Markov decision processes studied so far focus on the distribution of the cumulative reward as a whole, we aim at learning policies sensitive to the uncertain/stochastic nature of the rewards, which has the advantage of being conceptually more meaningful in some cases. To this end, we present a new decomposition of the randomness contained in the cumulative reward based on the Doob decomposition of a stochastic process, and introduce a new conceptual tool - the \textit{chaotic variation} - which can rigorously be interpreted as the risk measure of the martingale component associated to the cumulative reward process. We innovate on the reinforcement learning side by incorporating this new risk-sensitive approach into model-free algorithms, both policy gradient and value function based, and illustrate its relevance on grid world and portfolio optimization problems.
Latent Bayesian Inference for Robust Earnings Estimates
Apr 14, 2020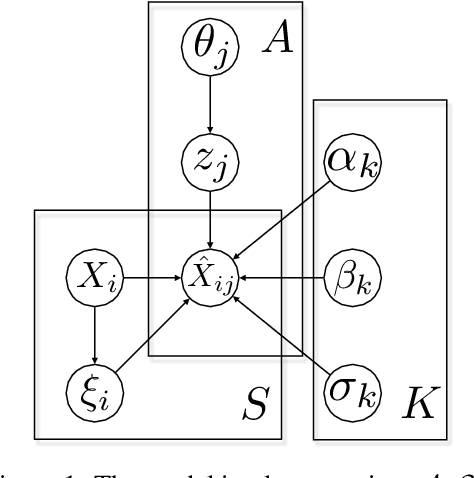
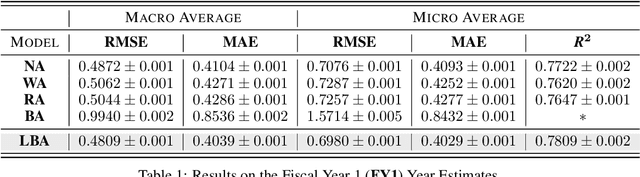
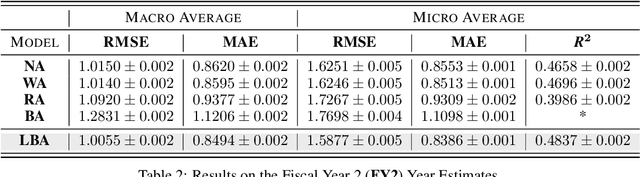
Equity research analysts at financial institutions play a pivotal role in capital markets; they provide an efficient conduit between investors and companies' management and facilitate the efficient flow of information from companies, promoting functional and liquid markets. However, previous research in the academic finance and behavioral economics communities has found that analysts' estimates of future company earnings and other financial quantities can be affected by a number of behavioral, incentive-based and discriminatory biases and systematic errors, which can detrimentally affect both investors and public companies. We propose a Bayesian latent variable model for analysts' systematic errors and biases which we use to generate a robust bias-adjusted consensus estimate of company earnings. Experiments using historical earnings estimates data show that our model is more accurate than the consensus average of estimates and other related approaches.
Heuristics for Link Prediction in Multiplex Networks
Apr 09, 2020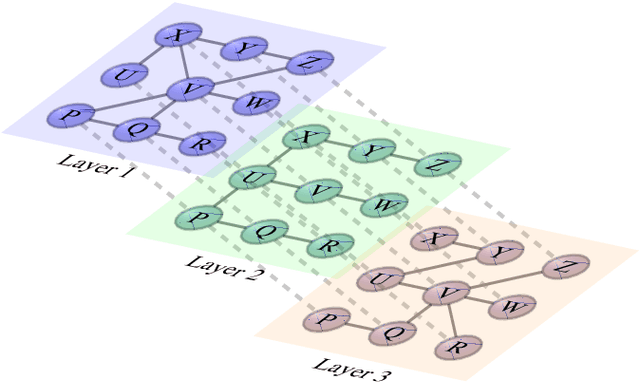
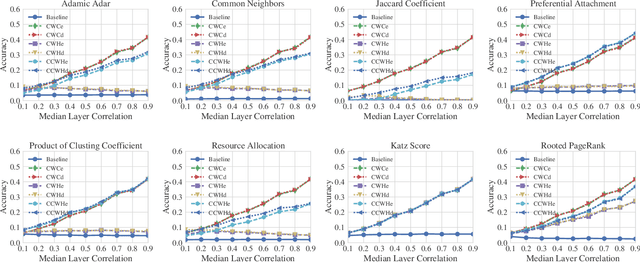

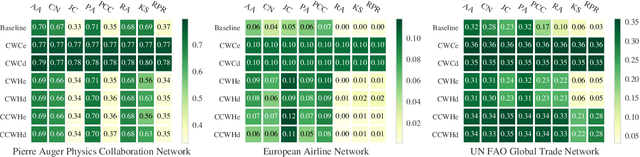
Link prediction, or the inference of future or missing connections between entities, is a well-studied problem in network analysis. A multitude of heuristics exist for link prediction in ordinary networks with a single type of connection. However, link prediction in multiplex networks, or networks with multiple types of connections, is not a well understood problem. We propose a novel general framework and three families of heuristics for multiplex network link prediction that are simple, interpretable, and take advantage of the rich connection type correlation structure that exists in many real world networks. We further derive a theoretical threshold for determining when to use a different connection type based on the number of links that overlap with an Erdos-Renyi random graph. Through experiments with simulated and real world scientific collaboration, transportation and global trade networks, we demonstrate that the proposed heuristics show increased performance with the richness of connection type correlation structure and significantly outperform their baseline heuristics for ordinary networks with a single connection type.
Reinforcement Learning for Market Making in a Multi-agent Dealer Market
Nov 14, 2019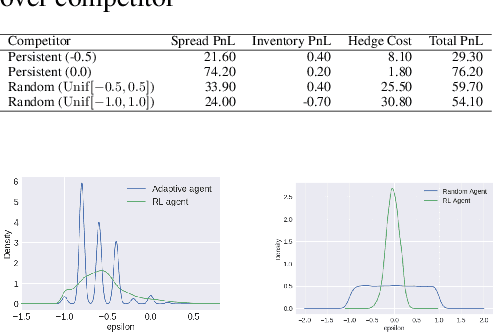
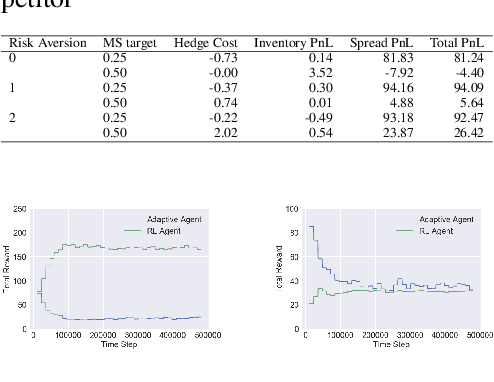
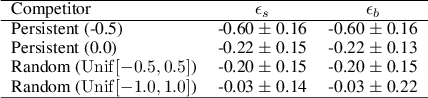

Market makers play an important role in providing liquidity to markets by continuously quoting prices at which they are willing to buy and sell, and managing inventory risk. In this paper, we build a multi-agent simulation of a dealer market and demonstrate that it can be used to understand the behavior of a reinforcement learning (RL) based market maker agent. We use the simulator to train an RL-based market maker agent with different competitive scenarios, reward formulations and market price trends (drifts). We show that the reinforcement learning agent is able to learn about its competitor's pricing policy; it also learns to manage inventory by smartly selecting asymmetric prices on the buy and sell sides (skewing), and maintaining a positive (or negative) inventory depending on whether the market price drift is positive (or negative). Finally, we propose and test reward formulations for creating risk averse RL-based market maker agents.