 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025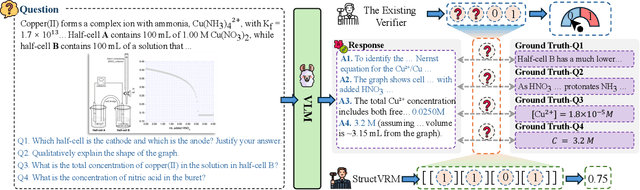

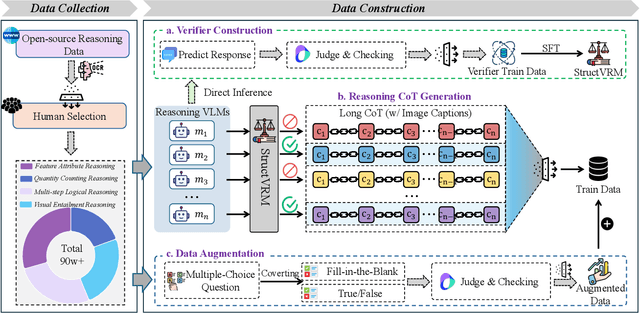
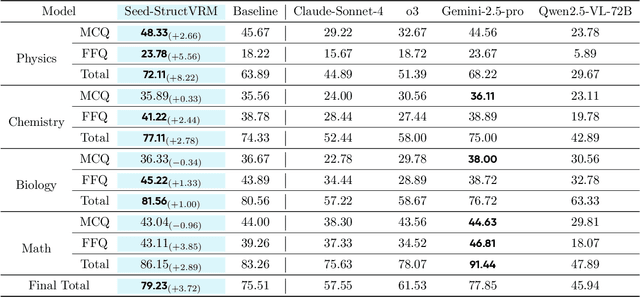
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Digital Twin Calibration with Model-Based Reinforcement Learning
Jan 04, 2025This paper presents a novel methodological framework, called the Actor-Simulator, that incorporates the calibration of digital twins into model-based reinforcement learning for more effective control of stochastic systems with complex nonlinear dynamics. Traditional model-based control often relies on restrictive structural assumptions (such as linear state transitions) and fails to account for parameter uncertainty in the model. These issues become particularly critical in industries such as biopharmaceutical manufacturing, where process dynamics are complex and not fully known, and only a limited amount of data is available. Our approach jointly calibrates the digital twin and searches for an optimal control policy, thus accounting for and reducing model error. We balance exploration and exploitation by using policy performance as a guide for data collection. This dual-component approach provably converges to the optimal policy, and outperforms existing methods in extensive numerical experiments based on the biopharmaceutical manufacturing domain.
Digital Twin Calibration for Biological System-of-Systems: Cell Culture Manufacturing Process
May 07, 2024
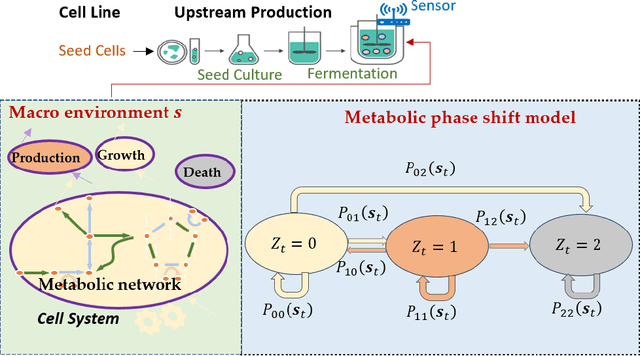
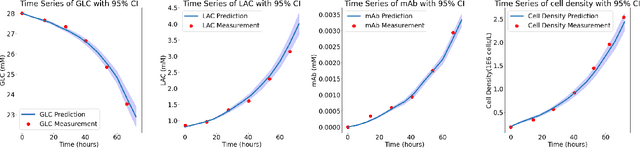
Biomanufacturing innovation relies on an efficient design of experiments (DoE) to optimize processes and product quality. Traditional DoE methods, ignoring the underlying bioprocessing mechanisms, often suffer from a lack of interpretability and sample efficiency. This limitation motivates us to create a new optimal learning approach that can guide a sequential DoEs for digital twin model calibration. In this study, we consider a multi-scale mechanistic model for cell culture process, also known as Biological Systems-of-Systems (Bio-SoS), as our digital twin. This model with modular design, composed of sub-models, allows us to integrate data across various production processes. To calibrate the Bio-SoS digital twin, we evaluate the mean squared error of model prediction and develop a computational approach to quantify the impact of parameter estimation error of individual sub-models on the prediction accuracy of digital twin, which can guide sample-efficient and interpretable DoEs.
SiGeo: Sub-One-Shot NAS via Information Theory and Geometry of Loss Landscape
Nov 22, 2023Neural Architecture Search (NAS) has become a widely used tool for automating neural network design. While one-shot NAS methods have successfully reduced computational requirements, they often require extensive training. On the other hand, zero-shot NAS utilizes training-free proxies to evaluate a candidate architecture's test performance but has two limitations: (1) inability to use the information gained as a network improves with training and (2) unreliable performance, particularly in complex domains like RecSys, due to the multi-modal data inputs and complex architecture configurations. To synthesize the benefits of both methods, we introduce a "sub-one-shot" paradigm that serves as a bridge between zero-shot and one-shot NAS. In sub-one-shot NAS, the supernet is trained using only a small subset of the training data, a phase we refer to as "warm-up." Within this framework, we present SiGeo, a proxy founded on a novel theoretical framework that connects the supernet warm-up with the efficacy of the proxy. Extensive experiments have shown that SiGeo, with the benefit of warm-up, consistently outperforms state-of-the-art NAS proxies on various established NAS benchmarks. When a supernet is warmed up, it can achieve comparable performance to weight-sharing one-shot NAS methods, but with a significant reduction ($\sim 60$\%) in computational costs.
Compressed domain vibration detection and classification for distributed acoustic sensing
Dec 27, 2022



Distributed acoustic sensing (DAS) is a novel enabling technology that can turn existing fibre optic networks to distributed acoustic sensors. However, it faces the challenges of transmitting, storing, and processing massive streams of data which are orders of magnitude larger than that collected from point sensors. The gap between intensive data generated by DAS and modern computing system with limited reading/writing speed and storage capacity imposes restrictions on many applications. Compressive sensing (CS) is a revolutionary signal acquisition method that allows a signal to be acquired and reconstructed with significantly fewer samples than that required by Nyquist-Shannon theorem. Though the data size is greatly reduced in the sampling stage, the reconstruction of the compressed data is however time and computation consuming. To address this challenge, we propose to map the feature extractor from Nyquist-domain to compressed-domain and therefore vibration detection and classification can be directly implemented in compressed-domain. The measured results show that our framework can be used to reduce the transmitted data size by 70% while achieves 99.4% true positive rate (TPR) and 0.04% false positive rate (TPR) along 5 km sensing fibre and 95.05% classification accuracy on a 5-class classification task.
Variance Reduction based Experience Replay for Policy Optimization
Aug 25, 2022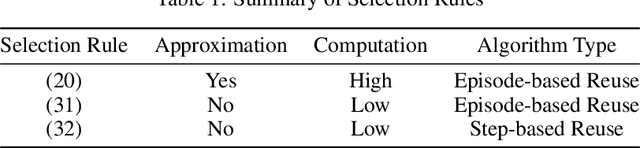
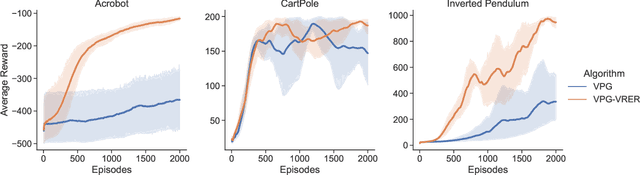
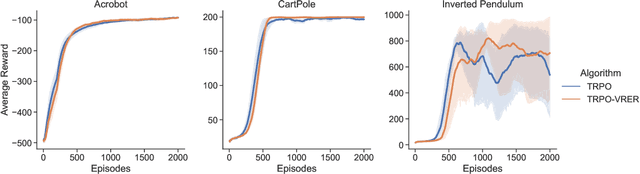
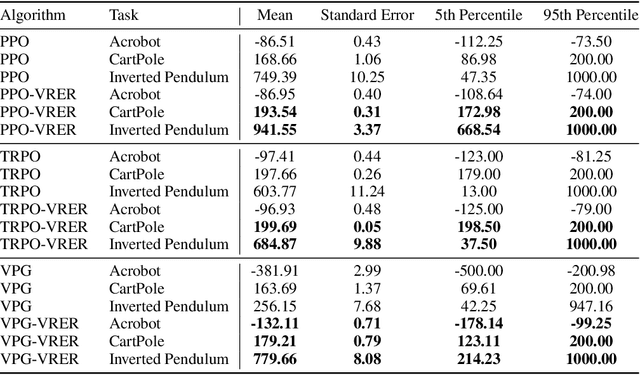
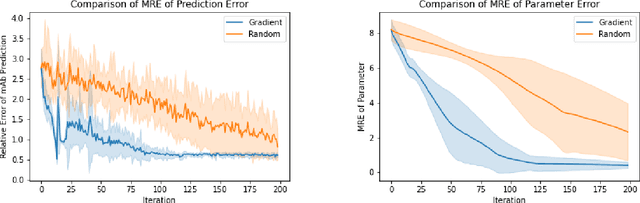
For reinforcement learning on complex stochastic systems where many factors dynamically impact the output trajectories, it is desirable to effectively leverage the information from historical samples collected in previous iterations to accelerate policy optimization. Classical experience replay allows agents to remember by reusing historical observations. However, the uniform reuse strategy that treats all observations equally overlooks the relative importance of different samples. To overcome this limitation, we propose a general variance reduction based experience replay (VRER) framework that can selectively reuse the most relevant samples to improve policy gradient estimation. This selective mechanism can adaptively put more weight on past samples that are more likely to be generated by the current target distribution. Our theoretical and empirical studies show that the proposed VRER can accelerate the learning of optimal policy and enhance the performance of state-of-the-art policy optimization approaches.
Dynamic Bayesian Network Auxiliary ABC-SMC for Hybrid Model Bayesian Inference to Accelerate Biomanufacturing Process Mechanism Learning and Robust Control
May 09, 2022
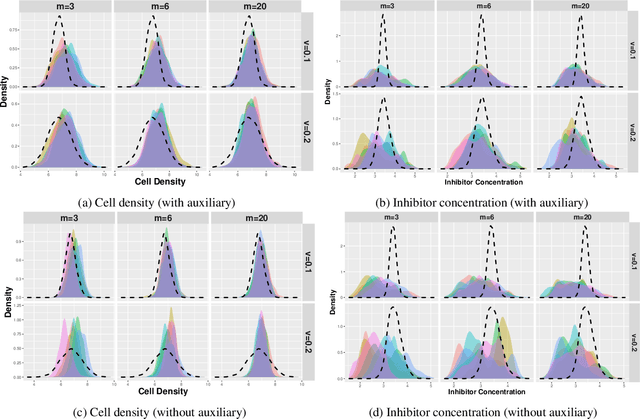

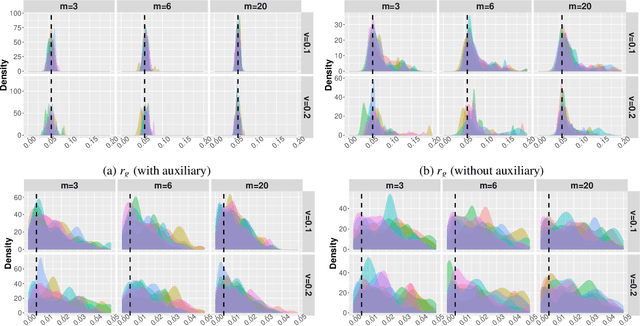
Driven by the critical needs of biomanufacturing 4.0, we present a probabilistic knowledge graph hybrid model characterizing complex spatial-temporal causal interdependencies of underlying bioprocessing mechanisms. It can faithfully capture the important properties, including nonlinear reactions, partially observed state, and nonstationary dynamics. Given limited process observations, we derive a posterior distribution quantifying model uncertainty, which can facilitate mechanism learning and support robust process control. To avoid evaluation of intractable likelihood, Approximate Bayesian Computation sampling with Sequential Monte Carlo (ABC-SMC) is developed to approximate the posterior distribution. Given high stochastic and model uncertainties, it is computationally expensive to match process output trajectories. Therefore, we propose a linear Gaussian dynamic Bayesian network (LG-DBN) auxiliary likelihood-based ABC-SMC algorithm. Through matching observed and simulated summary statistics, the proposed approach can dramatically reduce the computation cost and improve the posterior distribution approximation.
Variance Reduction based Partial Trajectory Reuse to Accelerate Policy Gradient Optimization
May 06, 2022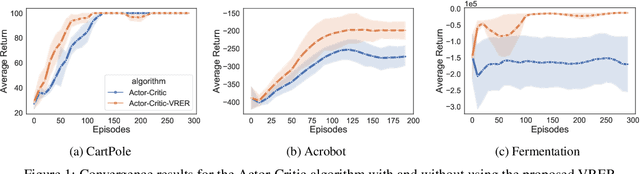
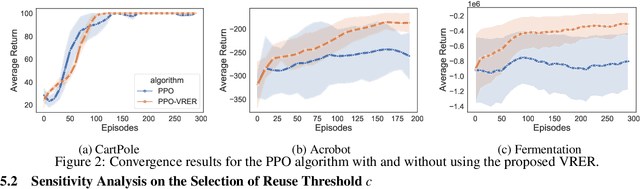
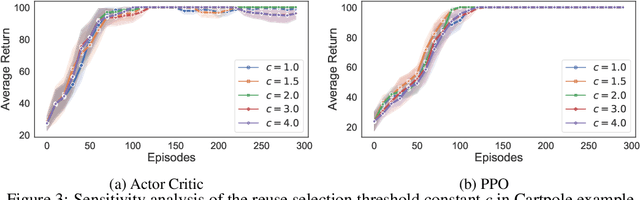
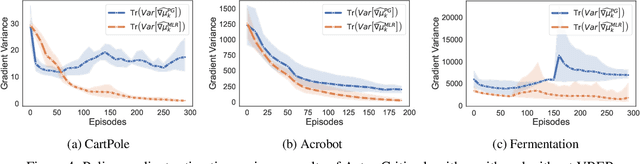
We extend the idea underlying the success of green simulation assisted policy gradient (GS-PG) to partial historical trajectory reuse for infinite-horizon Markov Decision Processes (MDP). The existing GS-PG method was designed to learn from complete episodes or process trajectories, which limits its applicability to low-data environment and online process control. In this paper, the mixture likelihood ratio (MLR) based policy gradient estimation is used to leverage the information from historical state decision transitions generated under different behavioral policies. We propose a variance reduction experience replay (VRER) approach that can intelligently select and reuse most relevant transition observations, improve the policy gradient estimation accuracy, and accelerate the learning of optimal policy. Then we create a process control strategy by incorporating VRER with the state-of-the-art step-based policy optimization approaches such as actor-critic method and proximal policy optimizations. The empirical study demonstrates that the proposed policy gradient methodology can significantly outperform the existing policy optimization approaches.
Opportunities of Hybrid Model-based Reinforcement Learning for Cell Therapy Manufacturing Process Control
Jan 26, 2022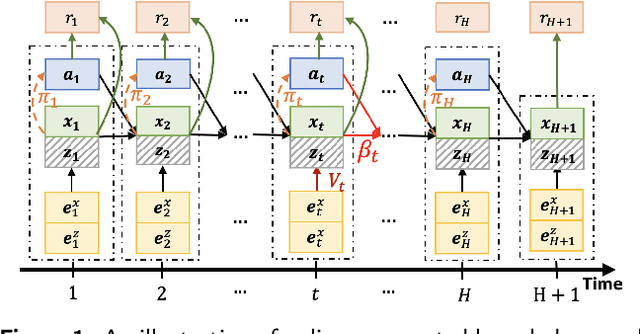
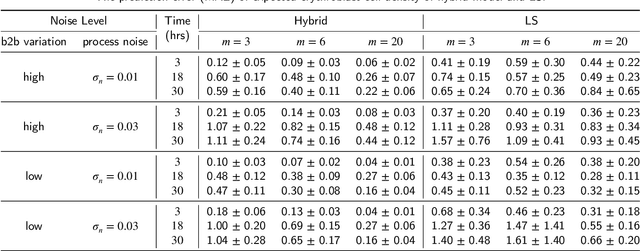
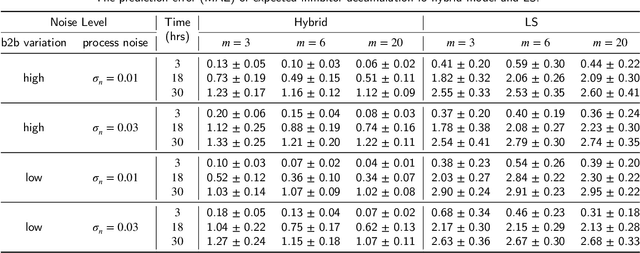
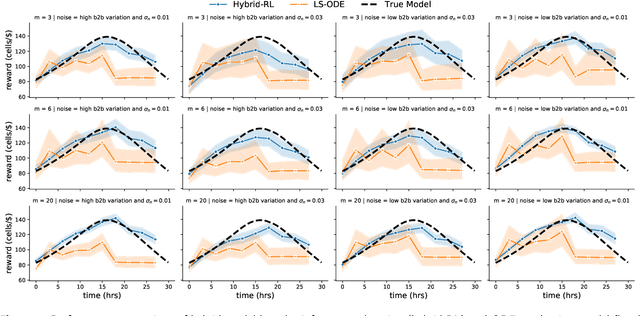
Driven by the key challenges of cell therapy manufacturing, including high complexity, high uncertainty, and very limited process observations, we propose a hybrid model-based reinforcement learning (RL) to efficiently guide process control. We first create a probabilistic knowledge graph (KG) hybrid model characterizing the risk- and science-based understanding of biomanufacturing process mechanisms and quantifying inherent stochasticity, e.g., batch-to-batch variation. It can capture the key features, including nonlinear reactions, nonstationary dynamics, and partially observed state. This hybrid model can leverage existing mechanistic models and facilitate learning from heterogeneous process data. A computational sampling approach is used to generate posterior samples quantifying model uncertainty. Then, we introduce hybrid model-based Bayesian RL, accounting for both inherent stochasticity and model uncertainty, to guide optimal, robust, and interpretable dynamic decision making. Cell therapy manufacturing examples are used to empirically demonstrate that the proposed framework can outperform the classical deterministic mechanistic model assisted process optimization.