 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Verifier: Collaborative Multimodal Reasoning via Dynamic Process Supervision
Feb 04, 2026Reinforcement Learning (RL) has emerged as a pivotal mechanism for enhancing the complex reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevailing paradigms typically rely on solitary rollout strategies where the model works alone. This lack of intermediate oversight renders the reasoning process susceptible to error propagation, where early logical deviations cascade into irreversible failures, resulting in noisy optimization signals. In this paper, we propose the \textbf{Guided Verifier} framework to address these structural limitations. Moving beyond passive terminal rewards, we introduce a dynamic verifier that actively co-solves tasks alongside the policy. During the rollout phase, this verifier interacts with the policy model in real-time, detecting inconsistencies and providing directional signals to steer the model toward valid trajectories. To facilitate this, we develop a specialized data synthesis pipeline targeting multimodal hallucinations, constructing \textbf{CoRe} dataset of process-level negatives and \textbf{Co}rrect-guide \textbf{Re}asoning trajectories to train the guided verifier. Extensive experiments on MathVista, MathVerse and MMMU indicate that by allocating compute to collaborative inference and dynamic verification, an 8B-parameter model can achieve strong performance.
GenProve: Learning to Generate Text with Fine-Grained Provenance
Jan 08, 2026Large language models (LLM) often hallucinate, and while adding citations is a common solution, it is frequently insufficient for accountability as users struggle to verify how a cited source supports a generated claim. Existing methods are typically coarse-grained and fail to distinguish between direct quotes and complex reasoning. In this paper, we introduce Generation-time Fine-grained Provenance, a task where models must generate fluent answers while simultaneously producing structured, sentence-level provenance triples. To enable this, we present ReFInE (Relation-aware Fine-grained Interpretability & Evidence), a dataset featuring expert verified annotations that distinguish between Quotation, Compression, and Inference. Building on ReFInE, we propose GenProve, a framework that combines Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO). By optimizing a composite reward for answer fidelity and provenance correctness, GenProve significantly outperforms 14 strong LLMs in joint evaluation. Crucially, our analysis uncovers a reasoning gap where models excel at surface-level quotation but struggle significantly with inference-based provenance, suggesting that verifiable reasoning remains a frontier challenge distinct from surface-level citation.
GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
Nov 14, 2025
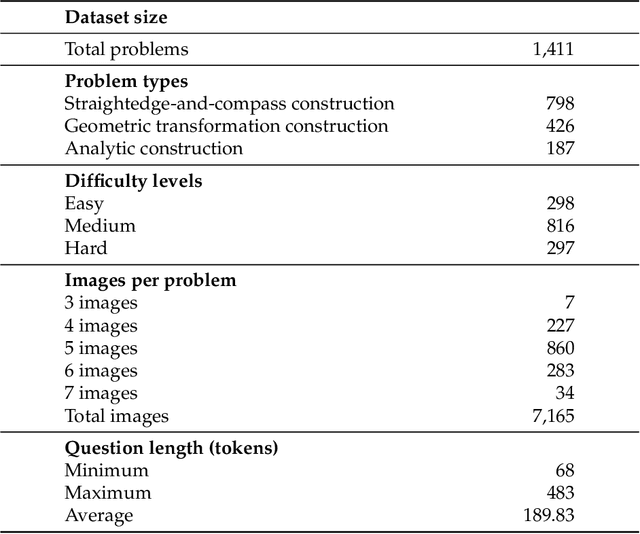
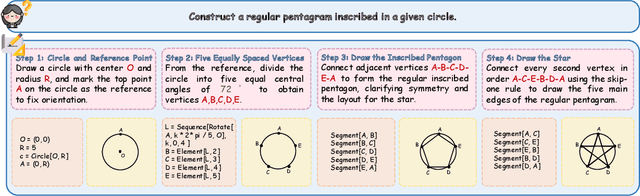

The advent of Unified Multimodal Models (UMMs) signals a paradigm shift in artificial intelligence, moving from passive perception to active, cross-modal generation. Despite their unprecedented ability to synthesize information, a critical gap persists in evaluation: existing benchmarks primarily assess discriminative understanding or unconstrained image generation separately, failing to measure the integrated cognitive process of generative reasoning. To bridge this gap, we propose that geometric construction provides an ideal testbed as it inherently demands a fusion of language comprehension and precise visual generation. We introduce GGBench, a benchmark designed specifically to evaluate geometric generative reasoning. It provides a comprehensive framework for systematically diagnosing a model's ability to not only understand and reason but to actively construct a solution, thereby setting a more rigorous standard for the next generation of intelligent systems. Project website: https://opendatalab-raiser.github.io/GGBench/.
Rethinking Text-to-SQL: Dynamic Multi-turn SQL Interaction for Real-world Database Exploration
Oct 30, 2025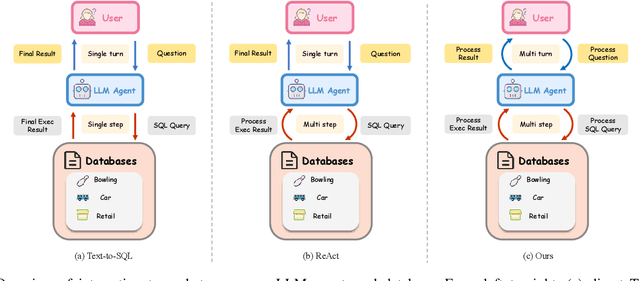



Recent advances in Text-to-SQL have achieved strong results in static, single-turn tasks, where models generate SQL queries from natural language questions. However, these systems fall short in real-world interactive scenarios, where user intents evolve and queries must be refined over multiple turns. In applications such as finance and business analytics, users iteratively adjust query constraints or dimensions based on intermediate results. To evaluate such dynamic capabilities, we introduce DySQL-Bench, a benchmark assessing model performance under evolving user interactions. Unlike previous manually curated datasets, DySQL-Bench is built through an automated two-stage pipeline of task synthesis and verification. Structured tree representations derived from raw database tables guide LLM-based task generation, followed by interaction-oriented filtering and expert validation. Human evaluation confirms 100% correctness of the synthesized data. We further propose a multi-turn evaluation framework simulating realistic interactions among an LLM-simulated user, the model under test, and an executable database. The model must adapt its reasoning and SQL generation as user intents change. DySQL-Bench covers 13 domains across BIRD and Spider 2 databases, totaling 1,072 tasks. Even GPT-4o attains only 58.34% overall accuracy and 23.81% on the Pass@5 metric, underscoring the benchmark's difficulty. All code and data are released at https://github.com/Aurora-slz/Real-World-SQL-Bench .
ResearchPulse: Building Method-Experiment Chains through Multi-Document Scientific Inference
Sep 03, 2025Understanding how scientific ideas evolve requires more than summarizing individual papers-it demands structured, cross-document reasoning over thematically related research. In this work, we formalize multi-document scientific inference, a new task that extracts and aligns motivation, methodology, and experimental results across related papers to reconstruct research development chains. This task introduces key challenges, including temporally aligning loosely structured methods and standardizing heterogeneous experimental tables. We present ResearchPulse, an agent-based framework that integrates instruction planning, scientific content extraction, and structured visualization. It consists of three coordinated agents: a Plan Agent for task decomposition, a Mmap-Agent that constructs motivation-method mind maps, and a Lchart-Agent that synthesizes experimental line charts. To support this task, we introduce ResearchPulse-Bench, a citation-aware benchmark of annotated paper clusters. Experiments show that our system, despite using 7B-scale agents, consistently outperforms strong baselines like GPT-4o in semantic alignment, structural consistency, and visual fidelity. The dataset are available in https://huggingface.co/datasets/ResearchPulse/ResearchPulse-Bench.
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025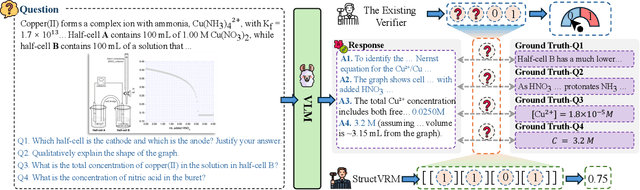

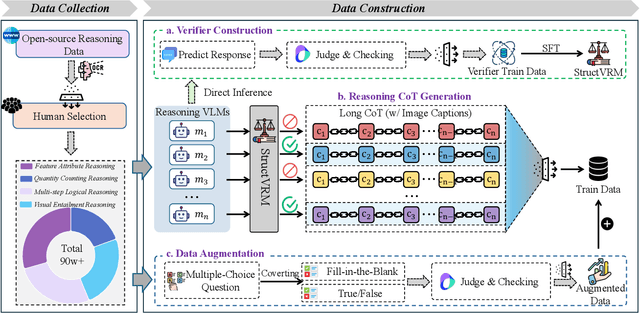
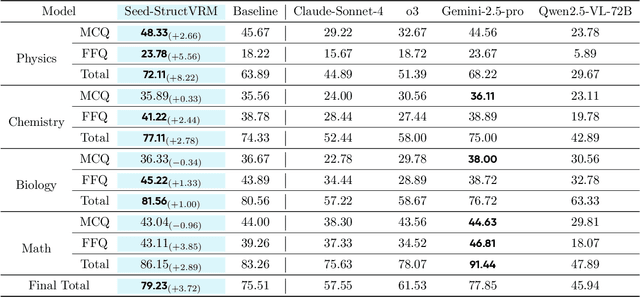
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
ChartReasoner: Code-Driven Modality Bridging for Long-Chain Reasoning in Chart Question Answering
Jun 11, 2025Recently, large language models have shown remarkable reasoning capabilities through long-chain reasoning before responding. However, how to extend this capability to visual reasoning tasks remains an open challenge. Existing multimodal reasoning approaches transfer such visual reasoning task into textual reasoning task via several image-to-text conversions, which often lose critical structural and semantic information embedded in visualizations, especially for tasks like chart question answering that require a large amount of visual details. To bridge this gap, we propose ChartReasoner, a code-driven novel two-stage framework designed to enable precise, interpretable reasoning over charts. We first train a high-fidelity model to convert diverse chart images into structured ECharts codes, preserving both layout and data semantics as lossless as possible. Then, we design a general chart reasoning data synthesis pipeline, which leverages this pretrained transport model to automatically and scalably generate chart reasoning trajectories and utilizes a code validator to filter out low-quality samples. Finally, we train the final multimodal model using a combination of supervised fine-tuning and reinforcement learning on our synthesized chart reasoning dataset and experimental results on four public benchmarks clearly demonstrate the effectiveness of our proposed ChartReasoner. It can preserve the original details of the charts as much as possible and perform comparably with state-of-the-art open-source models while using fewer parameters, approaching the performance of proprietary systems like GPT-4o in out-of-domain settings.
ChartMind: A Comprehensive Benchmark for Complex Real-world Multimodal Chart Question Answering
May 29, 2025Chart question answering (CQA) has become a critical multimodal task for evaluating the reasoning capabilities of vision-language models. While early approaches have shown promising performance by focusing on visual features or leveraging large-scale pre-training, most existing evaluations rely on rigid output formats and objective metrics, thus ignoring the complex, real-world demands of practical chart analysis. In this paper, we introduce ChartMind, a new benchmark designed for complex CQA tasks in real-world settings. ChartMind covers seven task categories, incorporates multilingual contexts, supports open-domain textual outputs, and accommodates diverse chart formats, bridging the gap between real-world applications and traditional academic benchmarks. Furthermore, we propose a context-aware yet model-agnostic framework, ChartLLM, that focuses on extracting key contextual elements, reducing noise, and enhancing the reasoning accuracy of multimodal large language models. Extensive evaluations on ChartMind and three representative public benchmarks with 14 mainstream multimodal models show our framework significantly outperforms the previous three common CQA paradigms: instruction-following, OCR-enhanced, and chain-of-thought, highlighting the importance of flexible chart understanding for real-world CQA. These findings suggest new directions for developing more robust chart reasoning in future research.
MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification
Feb 19, 2025



According to the Test-Time Scaling, the integration of External Slow-Thinking with the Verify mechanism has been demonstrated to enhance multi-round reasoning in large language models (LLMs). However, in the multimodal (MM) domain, there is still a lack of a strong MM-Verifier. In this paper, we introduce MM-Verifier and MM-Reasoner to enhance multimodal reasoning through longer inference and more robust verification. First, we propose a two-step MM verification data synthesis method, which combines a simulation-based tree search with verification and uses rejection sampling to generate high-quality Chain-of-Thought (COT) data. This data is then used to fine-tune the verification model, MM-Verifier. Additionally, we present a more efficient method for synthesizing MMCOT data, bridging the gap between text-based and multimodal reasoning. The synthesized data is used to fine-tune MM-Reasoner. Our MM-Verifier outperforms all larger models on the MathCheck, MathVista, and MathVerse benchmarks. Moreover, MM-Reasoner demonstrates strong effectiveness and scalability, with performance improving as data size increases. Finally, our approach achieves strong performance when combining MM-Reasoner and MM-Verifier, reaching an accuracy of 65.3 on MathVista, surpassing GPT-4o (63.8) with 12 rollouts.
Synth-Empathy: Towards High-Quality Synthetic Empathy Data
Jul 31, 2024In recent years, with the rapid advancements in large language models (LLMs), achieving excellent empathetic response capabilities has become a crucial prerequisite. Consequently, managing and understanding empathetic datasets have gained increasing significance. However, empathetic data are typically human-labeled, leading to insufficient datasets and wasted human labor. In this work, we present Synth-Empathy, an LLM-based data generation and quality and diversity selection pipeline that automatically generates high-quality empathetic data while discarding low-quality data. With the data generated from a low empathetic model, we are able to further improve empathetic response performance and achieve state-of-the-art (SoTA) results across multiple benchmarks. Moreover, our model achieves SoTA performance on various human evaluation benchmarks, demonstrating its effectiveness and robustness in real-world applications. Furthermore, we show the trade-off between data quantity and quality, providing insights into empathetic data generation and selection.