 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Medical Multimodal Diagnostic Framework Integrating Vision-Language Models and Logic Tree Reasoning
Dec 25, 2025With the rapid growth of large language models (LLMs) and vision-language models (VLMs) in medicine, simply integrating clinical text and medical imaging does not guarantee reliable reasoning. Existing multimodal models often produce hallucinations or inconsistent chains of thought, limiting clinical trust. We propose a diagnostic framework built upon LLaVA that combines vision-language alignment with logic-regularized reasoning. The system includes an input encoder for text and images, a projection module for cross-modal alignment, a reasoning controller that decomposes diagnostic tasks into steps, and a logic tree generator that assembles stepwise premises into verifiable conclusions. Evaluations on MedXpertQA and other benchmarks show that our method improves diagnostic accuracy and yields more interpretable reasoning traces on multimodal tasks, while remaining competitive on text-only settings. These results suggest a promising step toward trustworthy multimodal medical AI.
Adaptive Label Correction for Robust Medical Image Segmentation with Noisy Labels
Mar 15, 2025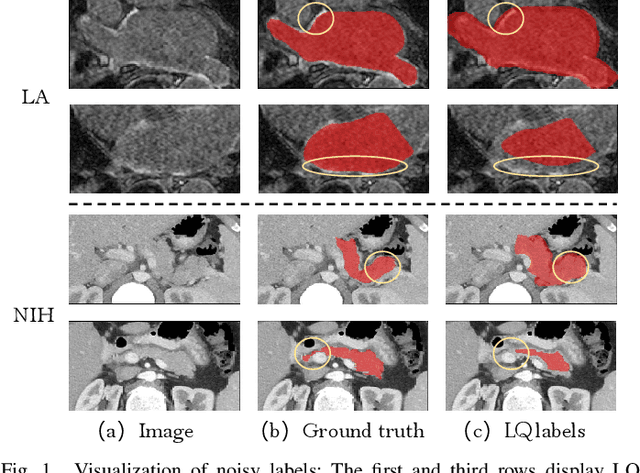
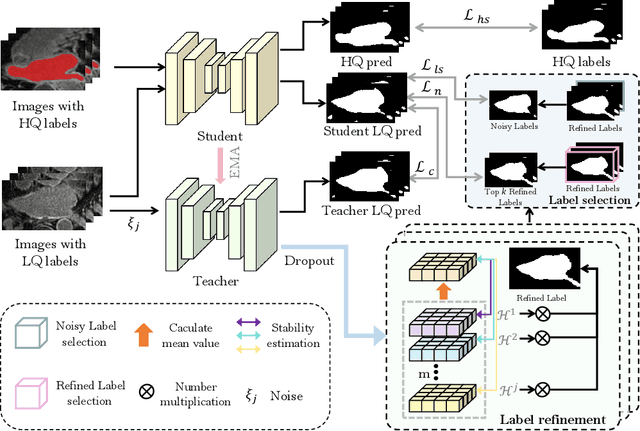
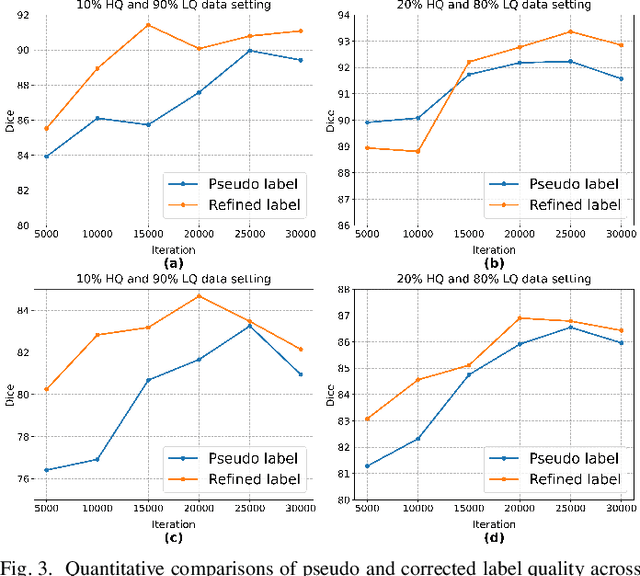

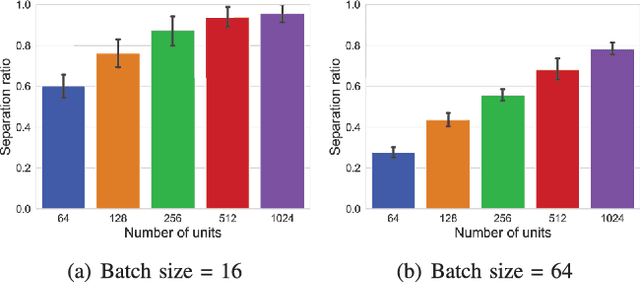
Deep learning has shown remarkable success in medical image analysis, but its reliance on large volumes of high-quality labeled data limits its applicability. While noisy labeled data are easier to obtain, directly incorporating them into training can degrade model performance. To address this challenge, we propose a Mean Teacher-based Adaptive Label Correction (ALC) self-ensemble framework for robust medical image segmentation with noisy labels. The framework leverages the Mean Teacher architecture to ensure consistent learning under noise perturbations. It includes an adaptive label refinement mechanism that dynamically captures and weights differences across multiple disturbance versions to enhance the quality of noisy labels. Additionally, a sample-level uncertainty-based label selection algorithm is introduced to prioritize high-confidence samples for network updates, mitigating the impact of noisy annotations. Consistency learning is integrated to align the predictions of the student and teacher networks, further enhancing model robustness. Extensive experiments on two public datasets demonstrate the effectiveness of the proposed framework, showing significant improvements in segmentation performance. By fully exploiting the strengths of the Mean Teacher structure, the ALC framework effectively processes noisy labels, adapts to challenging scenarios, and achieves competitive results compared to state-of-the-art methods.
Local Differential Privacy is Not Enough: A Sample Reconstruction Attack against Federated Learning with Local Differential Privacy
Feb 12, 2025
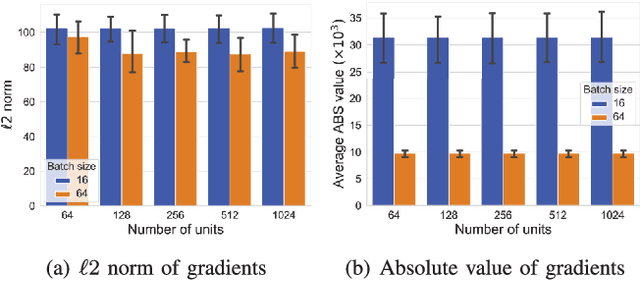
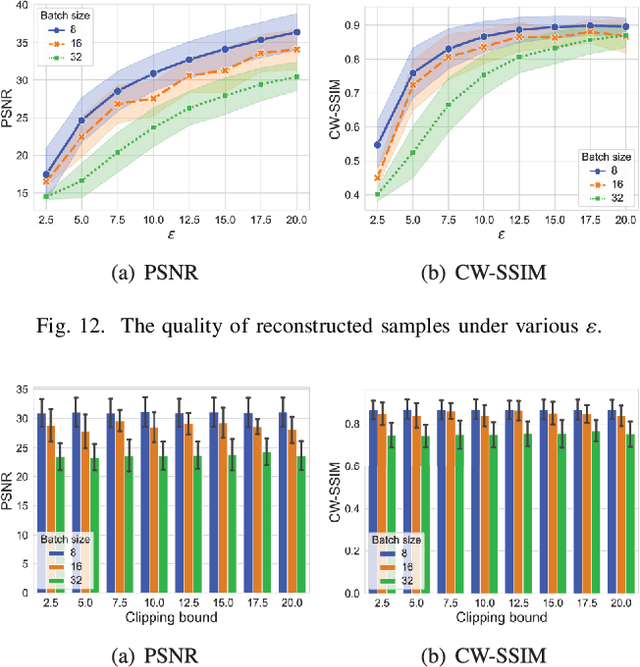
Reconstruction attacks against federated learning (FL) aim to reconstruct users' samples through users' uploaded gradients. Local differential privacy (LDP) is regarded as an effective defense against various attacks, including sample reconstruction in FL, where gradients are clipped and perturbed. Existing attacks are ineffective in FL with LDP since clipped and perturbed gradients obliterate most sample information for reconstruction. Besides, existing attacks embed additional sample information into gradients to improve the attack effect and cause gradient expansion, leading to a more severe gradient clipping in FL with LDP. In this paper, we propose a sample reconstruction attack against LDP-based FL with any target models to reconstruct victims' sensitive samples to illustrate that FL with LDP is not flawless. Considering gradient expansion in reconstruction attacks and noise in LDP, the core of the proposed attack is gradient compression and reconstructed sample denoising. For gradient compression, an inference structure based on sample characteristics is presented to reduce redundant gradients against LDP. For reconstructed sample denoising, we artificially introduce zero gradients to observe noise distribution and scale confidence interval to filter the noise. Theoretical proof guarantees the effectiveness of the proposed attack. Evaluations show that the proposed attack is the only attack that reconstructs victims' training samples in LDP-based FL and has little impact on the target model's accuracy. We conclude that LDP-based FL needs further improvements to defend against sample reconstruction attacks effectively.
Visual Agents as Fast and Slow Thinkers
Aug 16, 2024



Achieving human-level intelligence requires refining cognitive distinctions between System 1 and System 2 thinking. While contemporary AI, driven by large language models, demonstrates human-like traits, it falls short of genuine cognition. Transitioning from structured benchmarks to real-world scenarios presents challenges for visual agents, often leading to inaccurate and overly confident responses. To address the challenge, we introduce FaST, which incorporates the Fast and Slow Thinking mechanism into visual agents. FaST employs a switch adapter to dynamically select between System 1/2 modes, tailoring the problem-solving approach to different task complexity. It tackles uncertain and unseen objects by adjusting model confidence and integrating new contextual data. With this novel design, we advocate a flexible system, hierarchical reasoning capabilities, and a transparent decision-making pipeline, all of which contribute to its ability to emulate human-like cognitive processes in visual intelligence. Empirical results demonstrate that FaST outperforms various well-known baselines, achieving 80.8% accuracy over VQA^{v2} for visual question answering and 48.7% GIoU score over ReasonSeg for reasoning segmentation, demonstrate FaST's superior performance. Extensive testing validates the efficacy and robustness of FaST's core components, showcasing its potential to advance the development of cognitive visual agents in AI systems.
Evaluating Large Language Models for Anxiety and Depression Classification using Counseling and Psychotherapy Transcripts
Jul 18, 2024


We aim to evaluate the efficacy of traditional machine learning and large language models (LLMs) in classifying anxiety and depression from long conversational transcripts. We fine-tune both established transformer models (BERT, RoBERTa, Longformer) and more recent large models (Mistral-7B), trained a Support Vector Machine with feature engineering, and assessed GPT models through prompting. We observe that state-of-the-art models fail to enhance classification outcomes compared to traditional machine learning methods.
BioKGBench: A Knowledge Graph Checking Benchmark of AI Agent for Biomedical Science
Jun 29, 2024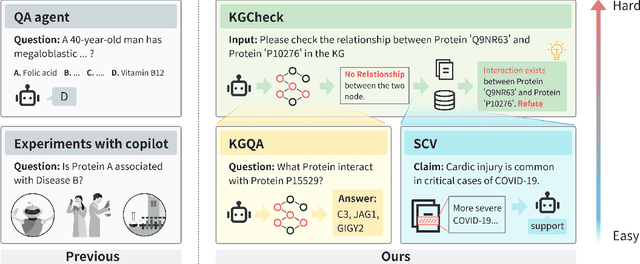
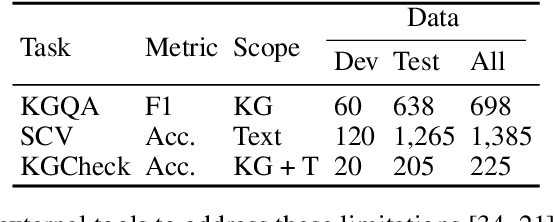
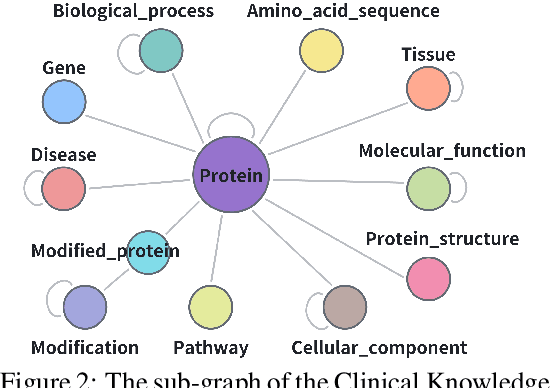
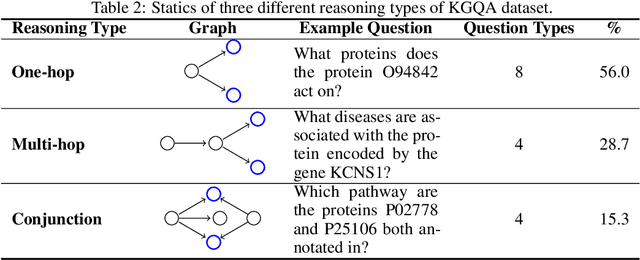
Pursuing artificial intelligence for biomedical science, a.k.a. AI Scientist, draws increasing attention, where one common approach is to build a copilot agent driven by Large Language Models (LLMs). However, to evaluate such systems, people either rely on direct Question-Answering (QA) to the LLM itself, or in a biomedical experimental manner. How to precisely benchmark biomedical agents from an AI Scientist perspective remains largely unexplored. To this end, we draw inspiration from one most important abilities of scientists, understanding the literature, and introduce BioKGBench. In contrast to traditional evaluation benchmark that only focuses on factual QA, where the LLMs are known to have hallucination issues, we first disentangle "Understanding Literature" into two atomic abilities, i) "Understanding" the unstructured text from research papers by performing scientific claim verification, and ii) Ability to interact with structured Knowledge-Graph Question-Answering (KGQA) as a form of "Literature" grounding. We then formulate a novel agent task, dubbed KGCheck, using KGQA and domain-based Retrieval-Augmented Generation (RAG) to identify the factual errors of existing large-scale knowledge graph databases. We collect over two thousand data for two atomic tasks and 225 high-quality annotated data for the agent task. Surprisingly, we discover that state-of-the-art agents, both daily scenarios and biomedical ones, have either failed or inferior performance on our benchmark. We then introduce a simple yet effective baseline, dubbed BKGAgent. On the widely used popular knowledge graph, we discover over 90 factual errors which provide scenarios for agents to make discoveries and demonstrate the effectiveness of our approach. The code and data are available at https://github.com/westlake-autolab/BioKGBench.
Peer Review as A Multi-Turn and Long-Context Dialogue with Role-Based Interactions
Jun 09, 2024Large Language Models (LLMs) have demonstrated wide-ranging applications across various fields and have shown significant potential in the academic peer-review process. However, existing applications are primarily limited to static review generation based on submitted papers, which fail to capture the dynamic and iterative nature of real-world peer reviews. In this paper, we reformulate the peer-review process as a multi-turn, long-context dialogue, incorporating distinct roles for authors, reviewers, and decision makers. We construct a comprehensive dataset containing over 26,841 papers with 92,017 reviews collected from multiple sources, including the top-tier conference and prestigious journal. This dataset is meticulously designed to facilitate the applications of LLMs for multi-turn dialogues, effectively simulating the complete peer-review process. Furthermore, we propose a series of metrics to evaluate the performance of LLMs for each role under this reformulated peer-review setting, ensuring fair and comprehensive evaluations. We believe this work provides a promising perspective on enhancing the LLM-driven peer-review process by incorporating dynamic, role-based interactions. It aligns closely with the iterative and interactive nature of real-world academic peer review, offering a robust foundation for future research and development in this area. We open-source the dataset at https://github.com/chengtan9907/ReviewMT.
Parameter-Saving Adversarial Training: Reinforcing Multi-Perturbation Robustness via Hypernetworks
Sep 28, 2023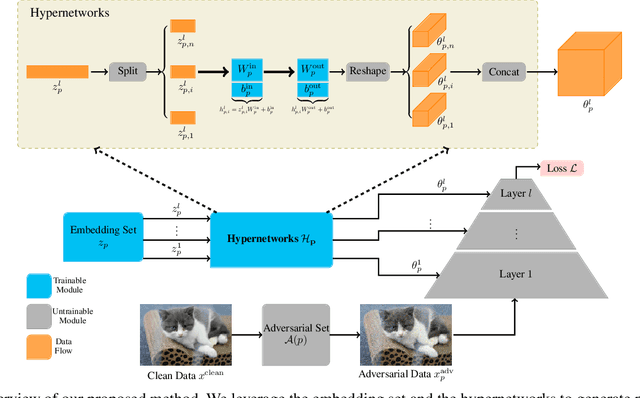


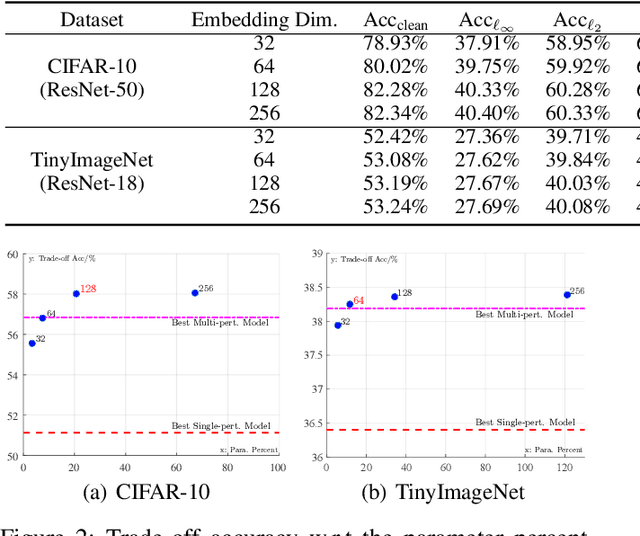
Adversarial training serves as one of the most popular and effective methods to defend against adversarial perturbations. However, most defense mechanisms only consider a single type of perturbation while various attack methods might be adopted to perform stronger adversarial attacks against the deployed model in real-world scenarios, e.g., $\ell_2$ or $\ell_\infty$. Defending against various attacks can be a challenging problem since multi-perturbation adversarial training and its variants only achieve suboptimal robustness trade-offs, due to the theoretical limit to multi-perturbation robustness for a single model. Besides, it is impractical to deploy large models in some storage-efficient scenarios. To settle down these drawbacks, in this paper we propose a novel multi-perturbation adversarial training framework, parameter-saving adversarial training (PSAT), to reinforce multi-perturbation robustness with an advantageous side effect of saving parameters, which leverages hypernetworks to train specialized models against a single perturbation and aggregate these specialized models to defend against multiple perturbations. Eventually, we extensively evaluate and compare our proposed method with state-of-the-art single/multi-perturbation robust methods against various latest attack methods on different datasets, showing the robustness superiority and parameter efficiency of our proposed method, e.g., for the CIFAR-10 dataset with ResNet-50 as the backbone, PSAT saves approximately 80\% of parameters with achieving the state-of-the-art robustness trade-off accuracy.
Reducing Adversarial Training Cost with Gradient Approximation
Sep 18, 2023



Deep learning models have achieved state-of-the-art performances in various domains, while they are vulnerable to the inputs with well-crafted but small perturbations, which are named after adversarial examples (AEs). Among many strategies to improve the model robustness against AEs, Projected Gradient Descent (PGD) based adversarial training is one of the most effective methods. Unfortunately, the prohibitive computational overhead of generating strong enough AEs, due to the maximization of the loss function, sometimes makes the regular PGD adversarial training impractical when using larger and more complicated models. In this paper, we propose that the adversarial loss can be approximated by the partial sum of Taylor series. Furthermore, we approximate the gradient of adversarial loss and propose a new and efficient adversarial training method, adversarial training with gradient approximation (GAAT), to reduce the cost of building up robust models. Additionally, extensive experiments demonstrate that this efficiency improvement can be achieved without any or with very little loss in accuracy on natural and adversarial examples, which show that our proposed method saves up to 60\% of the training time with comparable model test accuracy on MNIST, CIFAR-10 and CIFAR-100 datasets.
Stealthy Physical Masked Face Recognition Attack via Adversarial Style Optimization
Sep 18, 2023



Deep neural networks (DNNs) have achieved state-of-the-art performance on face recognition (FR) tasks in the last decade. In real scenarios, the deployment of DNNs requires taking various face accessories into consideration, like glasses, hats, and masks. In the COVID-19 pandemic era, wearing face masks is one of the most effective ways to defend against the novel coronavirus. However, DNNs are known to be vulnerable to adversarial examples with a small but elaborated perturbation. Thus, a facial mask with adversarial perturbations may pose a great threat to the widely used deep learning-based FR models. In this paper, we consider a challenging adversarial setting: targeted attack against FR models. We propose a new stealthy physical masked FR attack via adversarial style optimization. Specifically, we train an adversarial style mask generator that hides adversarial perturbations inside style masks. Moreover, to ameliorate the phenomenon of sub-optimization with one fixed style, we propose to discover the optimal style given a target through style optimization in a continuous relaxation manner. We simultaneously optimize the generator and the style selection for generating strong and stealthy adversarial style masks. We evaluated the effectiveness and transferability of our proposed method via extensive white-box and black-box digital experiments. Furthermore, we also conducted physical attack experiments against local FR models and online platforms.