 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
Mar 04, 2026Large language model (LLM) agents are fundamentally bottlenecked by finite context windows on long-horizon tasks. As trajectories grow, retaining tool outputs and intermediate reasoning in-context quickly becomes infeasible: the working context becomes prohibitively long, eventually exceeds the context budget, and makes distant evidence harder to use even when it is still present. Existing solutions typically shorten context through truncation or running summaries, but these methods are fundamentally lossy because they compress or discard past evidence itself. We introduce Memex, an indexed experience memory mechanism that instead compresses context without discarding evidence. Memex maintains a compact working context consisting of concise structured summaries and stable indices, while storing full-fidelity underlying interactions in an external experience database under those indices. The agent can then decide when to dereference an index and recover the exact past evidence needed for the current subgoal. We optimize both write and read behaviors with our reinforcement learning framework MemexRL, using reward shaping tailored to indexed memory usage under a context budget, so the agent learns what to summarize, what to archive, how to index it, and when to retrieve it. This yields a substantially less lossy form of long-horizon memory than summary-only approaches. We further provide a theoretical analysis showing the potential of the Memex loop to preserve decision quality with bounded dereferencing while keeping effective in-context computation bounded as history grows. Empirically, on challenging long-horizon tasks, Memex agent trained with MemexRL improves task success while using a significantly smaller working context.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
Reasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
Read the Scene, Not the Script: Outcome-Aware Safety for LLMs
Oct 05, 2025Safety-aligned Large Language Models (LLMs) still show two dominant failure modes: they are easily jailbroken, or they over-refuse harmless inputs that contain sensitive surface signals. We trace both to a common cause: current models reason weakly about links between actions and outcomes and over-rely on surface-form signals, lexical or stylistic cues that do not encode consequences. We define this failure mode as Consequence-blindness. To study consequence-blindness, we build a benchmark named CB-Bench covering four risk scenarios that vary whether semantic risk aligns with outcome risk, enabling evaluation under both matched and mismatched conditions which are often ignored by existing safety benchmarks. Mainstream models consistently fail to separate these risks and exhibit consequence-blindness, indicating that consequence-blindness is widespread and systematic. To mitigate consequence-blindness, we introduce CS-Chain-4k, a consequence-reasoning dataset for safety alignment. Models fine-tuned on CS-Chain-4k show clear gains against semantic-camouflage jailbreaks and reduce over-refusal on harmless inputs, while maintaining utility and generalization on other benchmarks. These results clarify the limits of current alignment, establish consequence-aware reasoning as a core alignment goal and provide a more practical and reproducible evaluation path.
EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning
Sep 26, 2025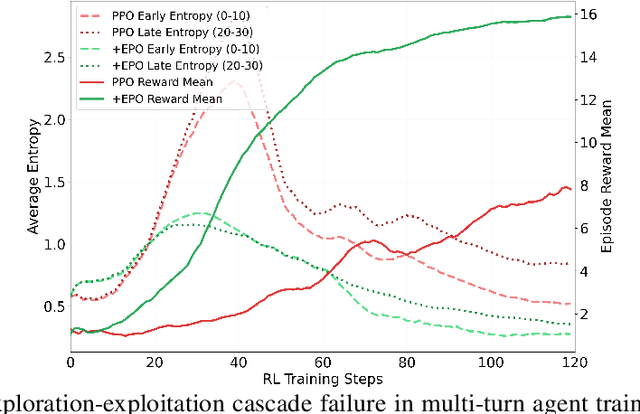
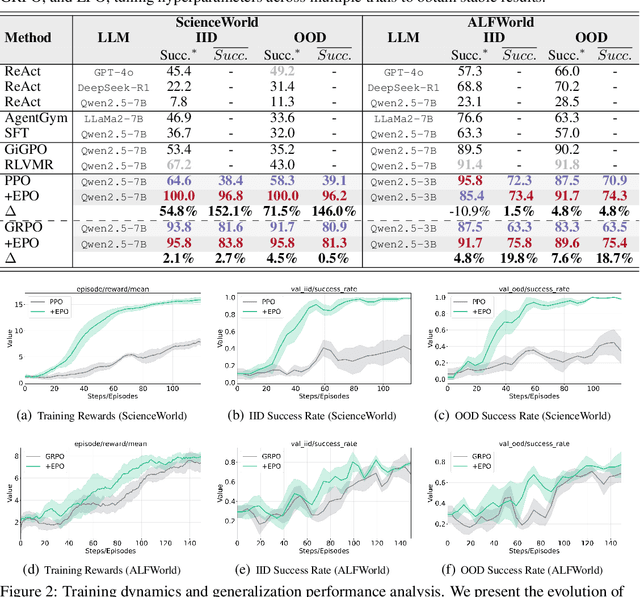


Training LLM agents in multi-turn environments with sparse rewards, where completing a single task requires 30+ turns of interaction within an episode, presents a fundamental challenge for reinforcement learning. We identify a critical failure mode unique to this setting: the exploration-exploitation cascade failure. This cascade begins with early-stage policy premature convergence, where sparse feedback causes agents to commit to flawed, low-entropy strategies. Subsequently, agents enter late-stage policy collapse, where conventional entropy regularization becomes counterproductive, promoting chaotic exploration that destabilizes training. We propose Entropy-regularized Policy Optimization (EPO), a general framework that breaks this failure cycle through three synergistic mechanisms: (1) adopting entropy regularization in multi-turn settings to enhance exploration, (2) an entropy smoothing regularizer that bounds policy entropy within historical averages to prevent abrupt fluctuations, and (3) adaptive phase-based weighting that balances exploration and exploitation across training. Our analysis justifies that EPO guarantees monotonically decreasing entropy variance while maintaining convergence. EPO achieves up to 152% performance improvement on ScienceWorld and up to 19.8% on ALFWorld. Our work demonstrates that multi-turn sparse-reward settings require fundamentally different entropy control than traditional RL, with broad implications for LLM agent training.
DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
Apr 13, 2025Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.
Scaling Laws of Scientific Discovery with AI and Robot Scientists
Mar 28, 2025



The rapid evolution of scientific inquiry highlights an urgent need for groundbreaking methodologies that transcend the limitations of traditional research. Conventional approaches, bogged down by manual processes and siloed expertise, struggle to keep pace with the demands of modern discovery. We envision an autonomous generalist scientist (AGS) system-a fusion of agentic AI and embodied robotics-that redefines the research lifecycle. This system promises to autonomously navigate physical and digital realms, weaving together insights from disparate disciplines with unprecedented efficiency. By embedding advanced AI and robot technologies into every phase-from hypothesis formulation to peer-ready manuscripts-AGS could slash the time and resources needed for scientific research in diverse field. We foresee a future where scientific discovery follows new scaling laws, driven by the proliferation and sophistication of such systems. As these autonomous agents and robots adapt to extreme environments and leverage a growing reservoir of knowledge, they could spark a paradigm shift, pushing the boundaries of what's possible and ushering in an era of relentless innovation.
LED: LLM Enhanced Open-Vocabulary Object Detection without Human Curated Data Generation
Mar 18, 2025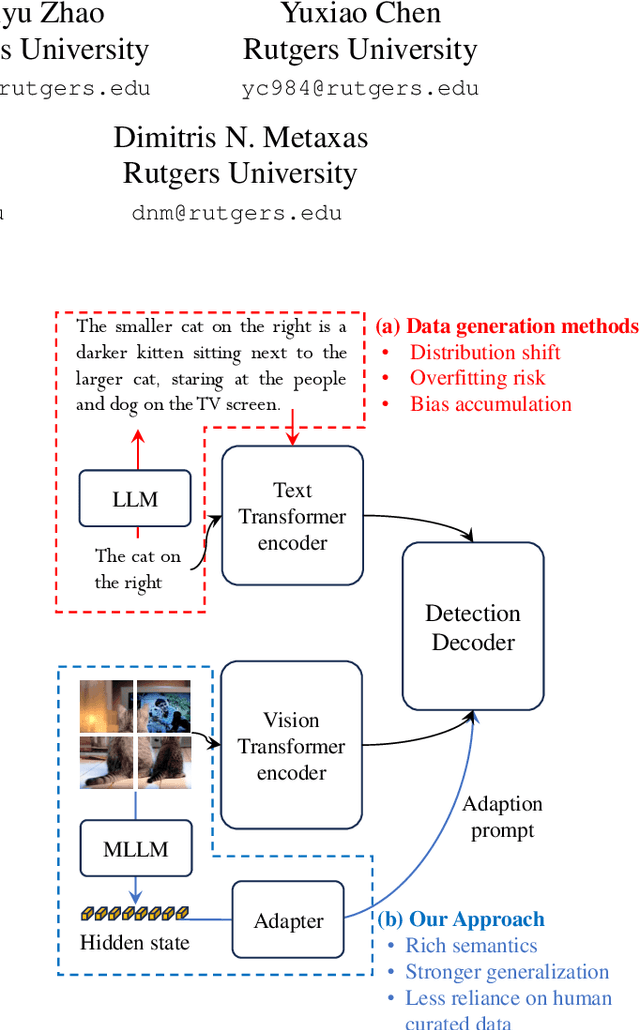
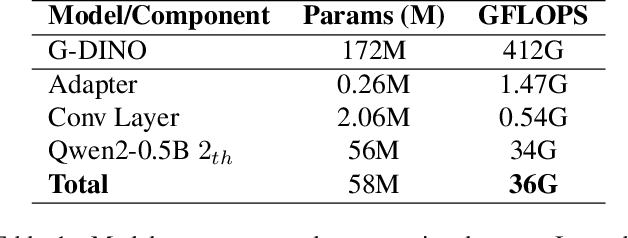
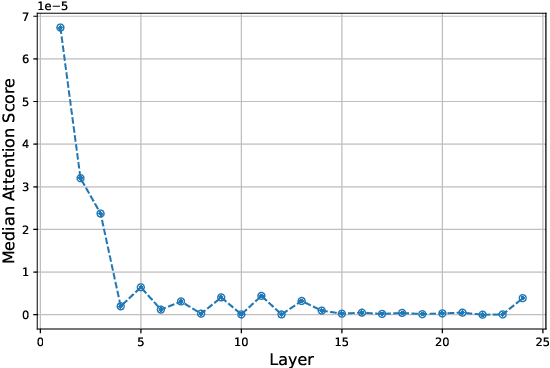
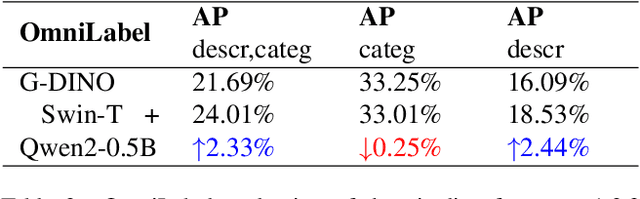
Large foundation models trained on large-scale visual-text data can significantly enhance Open Vocabulary Object Detection (OVD) through data generation. However, this may lead to biased synthetic data and overfitting to specific configurations. It can sidestep biases of manually curated data generation by directly leveraging hidden states of Large Language Models (LLMs), which is surprisingly rarely explored. This paper presents a systematic method to enhance visual grounding by utilizing decoder layers of the LLM of a MLLM. We introduce a zero-initialized cross-attention adapter to enable efficient knowledge transfer from LLMs to object detectors, an new approach called LED (LLM Enhanced Open-Vocabulary Object Detection). We demonstrate that intermediate hidden states from early LLM layers retain strong spatial-semantic correlations that are beneficial to grounding tasks. Experiments show that our adaptation strategy significantly enhances the performance on complex free-form text queries while remaining the same on plain categories. With our adaptation, Qwen2-0.5B with Swin-T as the vision encoder improves GroundingDINO by 2.33% on Omnilabel, at the overhead of 8.7% more GFLOPs. Qwen2-0.5B with a larger vision encoder can further boost the performance by 6.22%. We further validate our design by ablating on varied adapter architectures, sizes of LLMs, and which layers to add adaptation.
Can Large Vision-Language Models Detect Images Copyright Infringement from GenAI?
Feb 23, 2025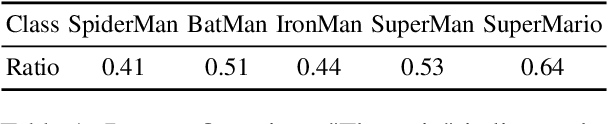


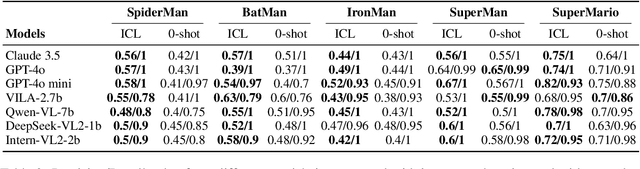
Generative AI models, renowned for their ability to synthesize high-quality content, have sparked growing concerns over the improper generation of copyright-protected material. While recent studies have proposed various approaches to address copyright issues, the capability of large vision-language models (LVLMs) to detect copyright infringements remains largely unexplored. In this work, we focus on evaluating the copyright detection abilities of state-of-the-art LVLMs using a various set of image samples. Recognizing the absence of a comprehensive dataset that includes both IP-infringement samples and ambiguous non-infringement negative samples, we construct a benchmark dataset comprising positive samples that violate the copyright protection of well-known IP figures, as well as negative samples that resemble these figures but do not raise copyright concerns. This dataset is created using advanced prompt engineering techniques. We then evaluate leading LVLMs using our benchmark dataset. Our experimental results reveal that LVLMs are prone to overfitting, leading to the misclassification of some negative samples as IP-infringement cases. In the final section, we analyze these failure cases and propose potential solutions to mitigate the overfitting problem.
ADO: Automatic Data Optimization for Inputs in LLM Prompts
Feb 17, 2025This study explores a novel approach to enhance the performance of Large Language Models (LLMs) through the optimization of input data within prompts. While previous research has primarily focused on refining instruction components and augmenting input data with in-context examples, our work investigates the potential benefits of optimizing the input data itself. We introduce a two-pronged strategy for input data optimization: content engineering and structural reformulation. Content engineering involves imputing missing values, removing irrelevant attributes, and enriching profiles by generating additional information inferred from existing attributes. Subsequent to content engineering, structural reformulation is applied to optimize the presentation of the modified content to LLMs, given their sensitivity to input format. Our findings suggest that these optimizations can significantly improve the performance of LLMs in various tasks, offering a promising avenue for future research in prompt engineering. The source code is available at https://anonymous.4open.science/r/ADO-6BC5/