 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Modeling for Multi-Agent Orchestration
Jun 11, 2026Multi-Agent Systems (MAS) built on Large Language Models (LLMs) require effective orchestration to coordinate specialized agents, yet training such orchestrators is hindered by limited supervision and high computational cost. We propose Orchestration Reward Modeling (OrchRM), a self-supervised framework for evaluating orchestration quality without human annotations. OrchRM leverages intermediate artifacts from multi-agent executions to construct win-lose pairs for Bradley-Terry reward model training. Unlike existing MAS test-time scaling and orchestrator training frameworks that rely on costly sub-agent rollouts, OrchRM operates directly at the orchestration level, enabling efficient and high-performing reward-guided orchestrator training and MAS test-time scaling. OrchRM improves training efficiency by up to 10x in token usage while improving MAS test-time scaling performance by up to 8% in accuracy. These gains consistently transfer across multiple domains, including mathematical reasoning, web-based question answering, and multi-hop reasoning, demonstrating orchestration-level reward modeling as a scalable direction for robust multi-agent orchestration. Code will be available at https://github.com/Wang-ML-Lab/OrchRM.
iLoRA: Bayesian Low-Rank Adaptation with Latent Interaction Graphs for Microbiome Diagnosis
May 28, 2026Parameter-efficient adaptation has made LLMs practical for domain prediction, but standard LoRA still relies on a static low-rank update and does not expose the latent interactions that often drive scientific labels. We introduce iLoRA. To our knowledge, it is the first Bayesian graph-conditioned LoRA framework. It infers a latent interaction graph from the input and uses it to generate input-conditioned LoRA updates. As a result, iLoRA learns prediction and latent interaction structure jointly, rather than training a predictor and applying interaction analysis only post hoc. We instantiate this idea for microbiome diagnosis, where disease state can depend on both species-level abundance and microbe-microbe cross-talk, and evaluate it in two complementary settings: interactive QA with human-annotated graphs, which tests latent structure recovery, and multi-cohort IBD diagnosis, which tests biomedical utility. Across both settings, iLoRA improves over strong LoRA and Bayesian adaptation baselines, recovers graphs aligned with human annotations and cohort-level microbiome associations, and provides calibrated uncertainty with moderate graph-branch overhead.
T3D: Few-Step Diffusion Language Models via Trajectory Self-Distillation with Direct Discriminative Optimization
Feb 13, 2026Diffusion large language models (DLLMs) have the potential to enable fast text generation by decoding multiple tokens in parallel. However, in practice, their inference efficiency is constrained by the need for many refinement steps, while aggressively reducing the number of steps leads to a substantial degradation in generation quality. To alleviate this, we propose a trajectory self-distillation framework that improves few-step decoding by distilling the model's own generative trajectories. We incorporate Direct Discriminative Optimization (DDO), a reverse-KL objective that promotes mode-seeking distillation and encourages the student to concentrate on high-probability teacher modes. Across benchmarks, our approach consistently outperforms strong few-step baselines and standard training under tight step budgets. Although full-step decoding remains superior, we substantially narrow the gap, establishing a strong foundation towards practical few-step DLLMs. The source code is available at https://github.com/Tyrion58/T3D.
MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Feb 03, 2026Multi-Agent Systems (MAS) built on Large Language Models (LLMs) often exhibit high variance in their reasoning trajectories. Process verification, which evaluates intermediate steps in trajectories, has shown promise in general reasoning settings, and has been suggested as a potential tool for guiding coordination of MAS; however, its actual effectiveness in MAS remains unclear. To fill this gap, we present MAS-ProVe, a systematic empirical study of process verification for multi-agent systems (MAS). Our study spans three verification paradigms (LLM-as-a-Judge, reward models, and process reward models), evaluated across two levels of verification granularity (agent-level and iteration-level). We further examine five representative verifiers and four context management strategies, and conduct experiments over six diverse MAS frameworks on multiple reasoning benchmarks. We find that process-level verification does not consistently improve performance and frequently exhibits high variance, highlighting the difficulty of reliably evaluating partial multi-agent trajectories. Among the methods studied, LLM-as-a-Judge generally outperforms reward-based approaches, with trained judges surpassing general-purpose LLMs. We further observe a small performance gap between LLMs acting as judges and as single agents, and identify a context-length-performance trade-off in verification. Overall, our results suggest that effective and robust process verification for MAS remains an open challenge, requiring further advances beyond current paradigms. Code is available at https://github.com/Wang-ML-Lab/MAS-ProVe.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025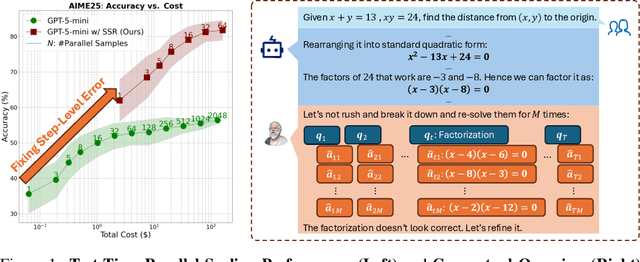
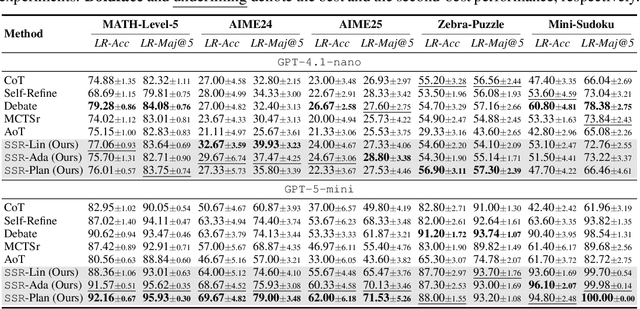
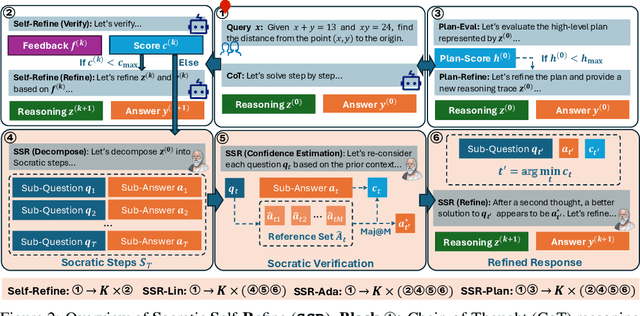
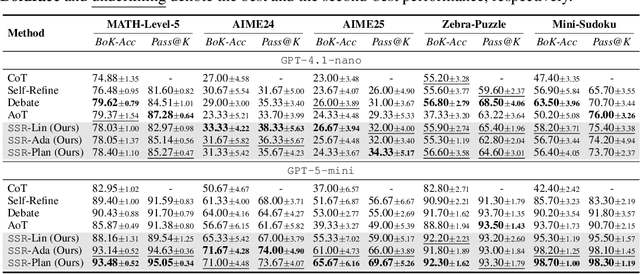
Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Token-Level Uncertainty Estimation for Large Language Model Reasoning
May 16, 2025While Large Language Models (LLMs) have demonstrated impressive capabilities, their output quality remains inconsistent across various application scenarios, making it difficult to identify trustworthy responses, especially in complex tasks requiring multi-step reasoning. In this paper, we propose a token-level uncertainty estimation framework to enable LLMs to self-assess and self-improve their generation quality in mathematical reasoning. Specifically, we introduce low-rank random weight perturbation to LLM decoding, generating predictive distributions that we use to estimate token-level uncertainties. We then aggregate these uncertainties to reflect semantic uncertainty of the generated sequences. Experiments on mathematical reasoning datasets of varying difficulty demonstrate that our token-level uncertainty metrics strongly correlate with answer correctness and model robustness. Additionally, we explore using uncertainty to directly enhance the model's reasoning performance through multiple generations and the particle filtering algorithm. Our approach consistently outperforms existing uncertainty estimation methods, establishing effective uncertainty estimation as a valuable tool for both evaluating and improving reasoning generation in LLMs.
Efficient Uncertainty Estimation via Distillation of Bayesian Large Language Models
May 16, 2025Recent advances in uncertainty estimation for Large Language Models (LLMs) during downstream adaptation have addressed key challenges of reliability and simplicity. However, existing Bayesian methods typically require multiple sampling iterations during inference, creating significant efficiency issues that limit practical deployment. In this paper, we investigate the possibility of eliminating the need for test-time sampling for LLM uncertainty estimation. Specifically, when given an off-the-shelf Bayesian LLM, we distill its aligned confidence into a non-Bayesian student LLM by minimizing the divergence between their predictive distributions. Unlike typical calibration methods, our distillation is carried out solely on the training dataset without the need of an additional validation dataset. This simple yet effective approach achieves N-times more efficient uncertainty estimation during testing, where N is the number of samples traditionally required by Bayesian LLMs. Our extensive experiments demonstrate that uncertainty estimation capabilities on training data can successfully generalize to unseen test data through our distillation technique, consistently producing results comparable to (or even better than) state-of-the-art Bayesian LLMs.
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering
Feb 05, 2025



Large Vision-Language Models (LVLMs) can reason effectively over both textual and visual inputs, but they tend to hallucinate syntactically coherent yet visually ungrounded contents. In this paper, we investigate the internal dynamics of hallucination by examining the tokens logits rankings throughout the generation process, revealing three key patterns in how LVLMs process information: (1) gradual visual information loss -- visually grounded tokens gradually become less favored throughout generation, and (2) early excitation -- semantically meaningful tokens achieve peak activation in the layers earlier than the final layer. (3) hidden genuine information -- visually grounded tokens though not being eventually decided still retain relatively high rankings at inference. Based on these insights, we propose VISTA (Visual Information Steering with Token-logit Augmentation), a training-free inference-time intervention framework that reduces hallucination while promoting genuine information. VISTA works by combining two complementary approaches: reinforcing visual information in activation space and leveraging early layer activations to promote semantically meaningful decoding. Compared to existing methods, VISTA requires no external supervision and is applicable to various decoding strategies. Extensive experiments show that VISTA on average reduces hallucination by abount 40% on evaluated open-ended generation task, and it consistently outperforms existing methods on four benchmarks across four architectures under three decoding strategies.
Rate-My-LoRA: Efficient and Adaptive Federated Model Tuning for Cardiac MRI Segmentation
Jan 06, 2025Cardiovascular disease (CVD) and cardiac dyssynchrony are major public health problems in the United States. Precise cardiac image segmentation is crucial for extracting quantitative measures that help categorize cardiac dyssynchrony. However, achieving high accuracy often depends on centralizing large datasets from different hospitals, which can be challenging due to privacy concerns. To solve this problem, Federated Learning (FL) is proposed to enable decentralized model training on such data without exchanging sensitive information. However, bandwidth limitations and data heterogeneity remain as significant challenges in conventional FL algorithms. In this paper, we propose a novel efficient and adaptive federate learning method for cardiac segmentation that improves model performance while reducing the bandwidth requirement. Our method leverages the low-rank adaptation (LoRA) to regularize model weight update and reduce communication overhead. We also propose a \mymethod{} aggregation technique to address data heterogeneity among clients. This technique adaptively penalizes the aggregated weights from different clients by comparing the validation accuracy in each client, allowing better generalization performance and fast local adaptation. In-client and cross-client evaluations on public cardiac MR datasets demonstrate the superiority of our method over other LoRA-based federate learning approaches.
Training-Free Bayesianization for Low-Rank Adapters of Large Language Models
Dec 07, 2024



Estimating the uncertainty of responses of Large Language Models~(LLMs) remains a critical challenge. While recent Bayesian methods have demonstrated effectiveness in quantifying uncertainty through low-rank weight updates, they typically require complex fine-tuning or post-training procedures. In this paper, we propose Training-Free Bayesianization~(TFB), a novel framework that transforms existing off-the-shelf trained LoRA adapters into Bayesian ones without additional training. TFB systematically searches for the maximally acceptable level of variance in the weight posterior, constrained within a family of low-rank isotropic Gaussian distributions. We theoretically demonstrate that under mild conditions, this search process is equivalent to variational inference for the weights. Through comprehensive experiments, we show that TFB achieves superior uncertainty estimation and generalization compared to existing methods while eliminating the need for complex training procedures. Code will be available at https://github.com/Wang-ML-Lab/bayesian-peft.