 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPDiT: Multi-Patch Global-to-Local Transformer Architecture For Efficient Flow Matching and Diffusion Model
Mar 27, 2026Transformer architectures, particularly Diffusion Transformers (DiTs), have become widely used in diffusion and flow-matching models due to their strong performance compared to convolutional UNets. However, the isotropic design of DiTs processes the same number of patchified tokens in every block, leading to relatively heavy computation during training process. In this work, we introduce a multi-patch transformer design in which early blocks operate on larger patches to capture coarse global context, while later blocks use smaller patches to refine local details. This hierarchical design could reduces computational cost by up to 50\% in GFLOPs while achieving good generative performance. In addition, we also propose improved designs for time and class embeddings that accelerate training convergence. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our architectural choices. Code is released at \url{https://github.com/quandao10/MPDiT}
MADCrowner: Margin Aware Dental Crown Design with Template Deformation and Refinement
Mar 05, 2026Dental crown restoration is one of the most common treatment modalities for tooth defect, where personalized dental crown design is critical. While computer-aided design (CAD) systems have notably enhanced the efficiency of dental crown design, extensive manual adjustments are still required in the clinic workflow. Recent studies have explored the application of learning-based methods for the automated generation of restorative dental crowns. Nevertheless, these approaches were challenged by inadequate spatial resolution, noisy outputs, and overextension of surface reconstruction. To address these limitations, we propose \totalframework, a margin-aware mesh generation framework comprising CrownDeformR and CrownSegger. Inspired by the clinic manual workflow of dental crown design, we designed CrownDeformR to deform an initial template to the target crown based on anatomical context, which is extracted by a multi-scale intraoral scan encoder. Additionally, we introduced \marginseg, a novel margin segmentation network, to extract the cervical margin of the target tooth. The performance of CrownDeformR improved with the cervical margin as an extra constraint. And it was also utilized as the boundary condition for the tailored postprocessing method, which removed the overextended area of the reconstructed surface. We constructed a large-scale intraoral scan dataset and performed extensive experiments. The proposed method significantly outperformed existing approaches in both geometric accuracy and clinical feasibility.
LUCID-SAE: Learning Unified Vision-Language Sparse Codes for Interpretable Concept Discovery
Feb 07, 2026Sparse autoencoders (SAEs) offer a natural path toward comparable explanations across different representation spaces. However, current SAEs are trained per modality, producing dictionaries whose features are not directly understandable and whose explanations do not transfer across domains. In this study, we introduce LUCID (Learning Unified vision-language sparse Codes for Interpretable concept Discovery), a unified vision-language sparse autoencoder that learns a shared latent dictionary for image patch and text token representations, while reserving private capacity for modality-specific details. We achieve feature alignment by coupling the shared codes with a learned optimal transport matching objective without the need of labeling. LUCID yields interpretable shared features that support patch-level grounding, establish cross-modal neuron correspondence, and enhance robustness against the concept clustering problem in similarity-based evaluation. Leveraging the alignment properties, we develop an automated dictionary interpretation pipeline based on term clustering without manual observations. Our analysis reveals that LUCID's shared features capture diverse semantic categories beyond objects, including actions, attributes, and abstract concepts, demonstrating a comprehensive approach to interpretable multimodal representations.
DeDPO: Debiased Direct Preference Optimization for Diffusion Models
Feb 05, 2026Direct Preference Optimization (DPO) has emerged as a predominant alignment method for diffusion models, facilitating off-policy training without explicit reward modeling. However, its reliance on large-scale, high-quality human preference labels presents a severe cost and scalability bottleneck. To overcome this, We propose a semi-supervised framework augmenting limited human data with a large corpus of unlabeled pairs annotated via cost-effective synthetic AI feedback. Our paper introduces Debiased DPO (DeDPO), which uniquely integrates a debiased estimation technique from causal inference into the DPO objective. By explicitly identifying and correcting the systematic bias and noise inherent in synthetic annotators, DeDPO ensures robust learning from imperfect feedback sources, including self-training and Vision-Language Models (VLMs). Experiments demonstrate that DeDPO is robust to the variations in synthetic labeling methods, achieving performance that matches and occasionally exceeds the theoretical upper bound of models trained on fully human-labeled data. This establishes DeDPO as a scalable solution for human-AI alignment using inexpensive synthetic supervision.
Data Augmentation for High-Fidelity Generation of CAR-T/NK Immunological Synapse Images
Feb 03, 2026Chimeric antigen receptor (CAR)-T and NK cell immunotherapies have transformed cancer treatment, and recent studies suggest that the quality of the CAR-T/NK cell immunological synapse (IS) may serve as a functional biomarker for predicting therapeutic efficacy. Accurate detection and segmentation of CAR-T/NK IS structures using artificial neural networks (ANNs) can greatly increase the speed and reliability of IS quantification. However, a persistent challenge is the limited size of annotated microscopy datasets, which restricts the ability of ANNs to generalize. To address this challenge, we integrate two complementary data-augmentation frameworks. First, we employ Instance Aware Automatic Augmentation (IAAA), an automated, instance-preserving augmentation method that generates synthetic CAR-T/NK IS images and corresponding segmentation masks by applying optimized augmentation policies to original IS data. IAAA supports multiple imaging modalities (e.g., fluorescence and brightfield) and can be applied directly to CAR-T/NK IS images derived from patient samples. In parallel, we introduce a Semantic-Aware AI Augmentation (SAAA) pipeline that combines a diffusion-based mask generator with a Pix2Pix conditional image synthesizer. This second method enables the creation of diverse, anatomically realistic segmentation masks and produces high-fidelity CAR-T/NK IS images aligned with those masks, further expanding the training corpus beyond what IAAA alone can provide. Together, these augmentation strategies generate synthetic images whose visual and structural properties closely match real IS data, significantly improving CAR-T/NK IS detection and segmentation performance. By enhancing the robustness and accuracy of IS quantification, this work supports the development of more reliable imaging-based biomarkers for predicting patient response to CAR-T/NK immunotherapy.
Anatomy-VLM: A Fine-grained Vision-Language Model for Medical Interpretation
Nov 11, 2025Accurate disease interpretation from radiology remains challenging due to imaging heterogeneity. Achieving expert-level diagnostic decisions requires integration of subtle image features with clinical knowledge. Yet major vision-language models (VLMs) treat images as holistic entities and overlook fine-grained image details that are vital for disease diagnosis. Clinicians analyze images by utilizing their prior medical knowledge and identify anatomical structures as important region of interests (ROIs). Inspired from this human-centric workflow, we introduce Anatomy-VLM, a fine-grained, vision-language model that incorporates multi-scale information. First, we design a model encoder to localize key anatomical features from entire medical images. Second, these regions are enriched with structured knowledge for contextually-aware interpretation. Finally, the model encoder aligns multi-scale medical information to generate clinically-interpretable disease prediction. Anatomy-VLM achieves outstanding performance on both in- and out-of-distribution datasets. We also validate the performance of Anatomy-VLM on downstream image segmentation tasks, suggesting that its fine-grained alignment captures anatomical and pathology-related knowledge. Furthermore, the Anatomy-VLM's encoder facilitates zero-shot anatomy-wise interpretation, providing its strong expert-level clinical interpretation capabilities.
AutoEdit: Automatic Hyperparameter Tuning for Image Editing
Sep 18, 2025Recent advances in diffusion models have revolutionized text-guided image editing, yet existing editing methods face critical challenges in hyperparameter identification. To get the reasonable editing performance, these methods often require the user to brute-force tune multiple interdependent hyperparameters, such as inversion timesteps and attention modification, \textit{etc.} This process incurs high computational costs due to the huge hyperparameter search space. We consider searching optimal editing's hyperparameters as a sequential decision-making task within the diffusion denoising process. Specifically, we propose a reinforcement learning framework, which establishes a Markov Decision Process that dynamically adjusts hyperparameters across denoising steps, integrating editing objectives into a reward function. The method achieves time efficiency through proximal policy optimization while maintaining optimal hyperparameter configurations. Experiments demonstrate significant reduction in search time and computational overhead compared to existing brute-force approaches, advancing the practical deployment of a diffusion-based image editing framework in the real world.
Token-Level Uncertainty Estimation for Large Language Model Reasoning
May 16, 2025While Large Language Models (LLMs) have demonstrated impressive capabilities, their output quality remains inconsistent across various application scenarios, making it difficult to identify trustworthy responses, especially in complex tasks requiring multi-step reasoning. In this paper, we propose a token-level uncertainty estimation framework to enable LLMs to self-assess and self-improve their generation quality in mathematical reasoning. Specifically, we introduce low-rank random weight perturbation to LLM decoding, generating predictive distributions that we use to estimate token-level uncertainties. We then aggregate these uncertainties to reflect semantic uncertainty of the generated sequences. Experiments on mathematical reasoning datasets of varying difficulty demonstrate that our token-level uncertainty metrics strongly correlate with answer correctness and model robustness. Additionally, we explore using uncertainty to directly enhance the model's reasoning performance through multiple generations and the particle filtering algorithm. Our approach consistently outperforms existing uncertainty estimation methods, establishing effective uncertainty estimation as a valuable tool for both evaluating and improving reasoning generation in LLMs.
MedForge: Building Medical Foundation Models Like Open Source Software Development
Feb 22, 2025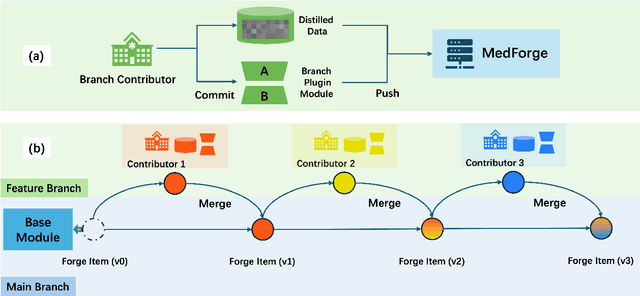
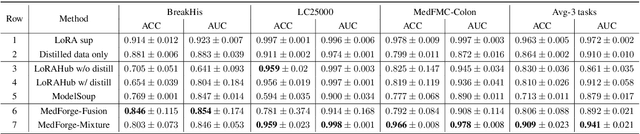
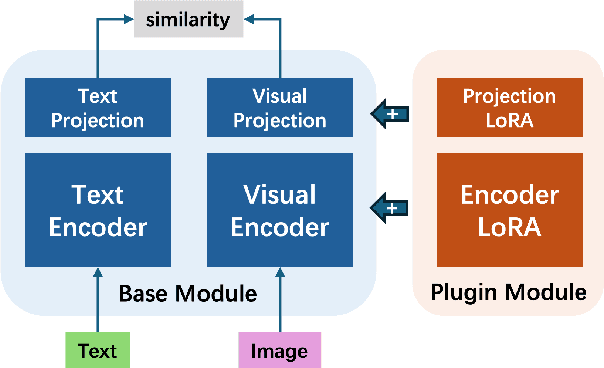
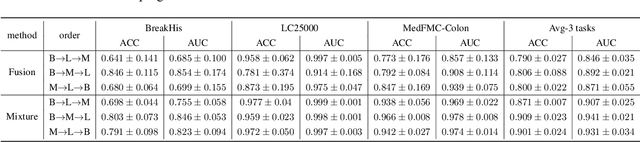
Foundational models (FMs) have made significant strides in the healthcare domain. Yet the data silo challenge and privacy concern remain in healthcare systems, hindering safe medical data sharing and collaborative model development among institutions. The collection and curation of scalable clinical datasets increasingly become the bottleneck for training strong FMs. In this study, we propose Medical Foundation Models Merging (MedForge), a cooperative framework enabling a community-driven medical foundation model development, meanwhile preventing the information leakage of raw patient data and mitigating synchronization model development issues across clinical institutions. MedForge offers a bottom-up model construction mechanism by flexibly merging task-specific Low-Rank Adaptation (LoRA) modules, which can adapt to downstream tasks while retaining original model parameters. Through an asynchronous LoRA module integration scheme, the resulting composite model can progressively enhance its comprehensive performance on various clinical tasks. MedForge shows strong performance on multiple clinical datasets (e.g., breast cancer, lung cancer, and colon cancer) collected from different institutions. Our major findings highlight the value of collaborative foundation models in advancing multi-center clinical collaboration effectively and cohesively. Our code is publicly available at https://github.com/TanZheling/MedForge.
Improved Training Technique for Latent Consistency Models
Feb 03, 2025



Consistency models are a new family of generative models capable of producing high-quality samples in either a single step or multiple steps. Recently, consistency models have demonstrated impressive performance, achieving results on par with diffusion models in the pixel space. However, the success of scaling consistency training to large-scale datasets, particularly for text-to-image and video generation tasks, is determined by performance in the latent space. In this work, we analyze the statistical differences between pixel and latent spaces, discovering that latent data often contains highly impulsive outliers, which significantly degrade the performance of iCT in the latent space. To address this, we replace Pseudo-Huber losses with Cauchy losses, effectively mitigating the impact of outliers. Additionally, we introduce a diffusion loss at early timesteps and employ optimal transport (OT) coupling to further enhance performance. Lastly, we introduce the adaptive scaling-$c$ scheduler to manage the robust training process and adopt Non-scaling LayerNorm in the architecture to better capture the statistics of the features and reduce outlier impact. With these strategies, we successfully train latent consistency models capable of high-quality sampling with one or two steps, significantly narrowing the performance gap between latent consistency and diffusion models. The implementation is released here: https://github.com/quandao10/sLCT/