 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Imitation to Intuition: Intrinsic Reasoning for Open-Instance Video Classification
Mar 11, 2026Conventional video classification models, acting as effective imitators, excel in scenarios with homogeneous data distributions. However, real-world applications often present an open-instance challenge, where intra-class variations are vast and complex, beyond existing benchmarks. While traditional video encoder models struggle to fit these diverse distributions, vision-language models (VLMs) offer superior generalization but have not fully leveraged their reasoning capabilities (intuition) for such tasks. In this paper, we bridge this gap with an intrinsic reasoning framework that evolves open-instance video classification from imitation to intuition. Our approach, namely DeepIntuit, begins with a cold-start supervised alignment to initialize reasoning capability, followed by refinement using Group Relative Policy Optimization (GRPO) to enhance reasoning coherence through reinforcement learning. Crucially, to translate this reasoning into accurate classification, DeepIntuit then introduces an intuitive calibration stage. In this stage, a classifier is trained on this intrinsic reasoning traces generated by the refined VLM, ensuring stable knowledge transfer without distribution mismatch. Extensive experiments demonstrate that for open-instance video classification, DeepIntuit benefits significantly from transcending simple feature imitation and evolving toward intrinsic reasoning. Our project is available at https://bwgzk-keke.github.io/DeepIntuit/.
AutoEdit: Automatic Hyperparameter Tuning for Image Editing
Sep 18, 2025Recent advances in diffusion models have revolutionized text-guided image editing, yet existing editing methods face critical challenges in hyperparameter identification. To get the reasonable editing performance, these methods often require the user to brute-force tune multiple interdependent hyperparameters, such as inversion timesteps and attention modification, \textit{etc.} This process incurs high computational costs due to the huge hyperparameter search space. We consider searching optimal editing's hyperparameters as a sequential decision-making task within the diffusion denoising process. Specifically, we propose a reinforcement learning framework, which establishes a Markov Decision Process that dynamically adjusts hyperparameters across denoising steps, integrating editing objectives into a reward function. The method achieves time efficiency through proximal policy optimization while maintaining optimal hyperparameter configurations. Experiments demonstrate significant reduction in search time and computational overhead compared to existing brute-force approaches, advancing the practical deployment of a diffusion-based image editing framework in the real world.
Adaptive Keyframe Sampling for Long Video Understanding
Feb 28, 2025



Multimodal large language models (MLLMs) have enabled open-world visual understanding by injecting visual input as extra tokens into large language models (LLMs) as contexts. However, when the visual input changes from a single image to a long video, the above paradigm encounters difficulty because the vast amount of video tokens has significantly exceeded the maximal capacity of MLLMs. Therefore, existing video-based MLLMs are mostly established upon sampling a small portion of tokens from input data, which can cause key information to be lost and thus produce incorrect answers. This paper presents a simple yet effective algorithm named Adaptive Keyframe Sampling (AKS). It inserts a plug-and-play module known as keyframe selection, which aims to maximize the useful information with a fixed number of video tokens. We formulate keyframe selection as an optimization involving (1) the relevance between the keyframes and the prompt, and (2) the coverage of the keyframes over the video, and present an adaptive algorithm to approximate the best solution. Experiments on two long video understanding benchmarks validate that Adaptive Keyframe Sampling improves video QA accuracy (beyond strong baselines) upon selecting informative keyframes. Our study reveals the importance of information pre-filtering in video-based MLLMs. Code is available at https://github.com/ncTimTang/AKS.
YOLOv12: Attention-Centric Real-Time Object Detectors
Feb 18, 2025Enhancing the network architecture of the YOLO framework has been crucial for a long time, but has focused on CNN-based improvements despite the proven superiority of attention mechanisms in modeling capabilities. This is because attention-based models cannot match the speed of CNN-based models. This paper proposes an attention-centric YOLO framework, namely YOLOv12, that matches the speed of previous CNN-based ones while harnessing the performance benefits of attention mechanisms. YOLOv12 surpasses all popular real-time object detectors in accuracy with competitive speed. For example, YOLOv12-N achieves 40.6% mAP with an inference latency of 1.64 ms on a T4 GPU, outperforming advanced YOLOv10-N / YOLOv11-N by 2.1%/1.2% mAP with a comparable speed. This advantage extends to other model scales. YOLOv12 also surpasses end-to-end real-time detectors that improve DETR, such as RT-DETR / RT-DETRv2: YOLOv12-S beats RT-DETR-R18 / RT-DETRv2-R18 while running 42% faster, using only 36% of the computation and 45% of the parameters. More comparisons are shown in Figure 1.
Personalized Large Vision-Language Models
Dec 23, 2024



The personalization model has gained significant attention in image generation yet remains underexplored for large vision-language models (LVLMs). Beyond generic ones, with personalization, LVLMs handle interactive dialogues using referential concepts (e.g., ``Mike and Susan are talking.'') instead of the generic form (e.g., ``a boy and a girl are talking.''), making the conversation more customizable and referentially friendly. In addition, PLVM is equipped to continuously add new concepts during a dialogue without incurring additional costs, which significantly enhances the practicality. PLVM proposes Aligner, a pre-trained visual encoder to align referential concepts with the queried images. During the dialogues, it extracts features of reference images with these corresponding concepts and recognizes them in the queried image, enabling personalization. We note that the computational cost and parameter count of the Aligner are negligible within the entire framework. With comprehensive qualitative and quantitative analyses, we reveal the effectiveness and superiority of PLVM.
ClawMachine: Fetching Visual Tokens as An Entity for Referring and Grounding
Jun 17, 2024An essential topic for multimodal large language models (MLLMs) is aligning vision and language concepts at a finer level. In particular, we devote efforts to encoding visual referential information for tasks such as referring and grounding. Existing methods, including proxy encoding and geometry encoding, incorporate additional syntax to encode the object's location, bringing extra burdens in training MLLMs to communicate between language and vision. This study presents ClawMachine, offering a new methodology that notates an entity directly using the visual tokens. It allows us to unify the prompt and answer of visual referential tasks without additional syntax. Upon a joint vision-language vocabulary, ClawMachine unifies visual referring and grounding into an auto-regressive format and learns with a decoder-only architecture. Experiments validate that our model achieves competitive performance across visual referring and grounding tasks with a reduced demand for training data. Additionally, ClawMachine demonstrates a native ability to integrate multi-source information for complex visual reasoning, which prior MLLMs can hardly perform without specific adaptions.
Artemis: Towards Referential Understanding in Complex Videos
Jun 01, 2024



Videos carry rich visual information including object description, action, interaction, etc., but the existing multimodal large language models (MLLMs) fell short in referential understanding scenarios such as video-based referring. In this paper, we present Artemis, an MLLM that pushes video-based referential understanding to a finer level. Given a video, Artemis receives a natural-language question with a bounding box in any video frame and describes the referred target in the entire video. The key to achieving this goal lies in extracting compact, target-specific video features, where we set a solid baseline by tracking and selecting spatiotemporal features from the video. We train Artemis on the newly established VideoRef45K dataset with 45K video-QA pairs and design a computationally efficient, three-stage training procedure. Results are promising both quantitatively and qualitatively. Additionally, we show that \model can be integrated with video grounding and text summarization tools to understand more complex scenarios. Code and data are available at https://github.com/qiujihao19/Artemis.
vHeat: Building Vision Models upon Heat Conduction
May 26, 2024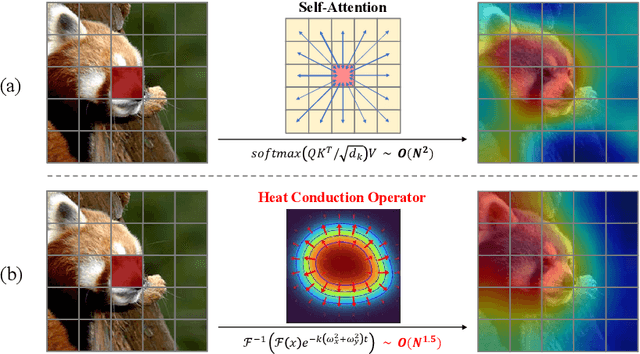

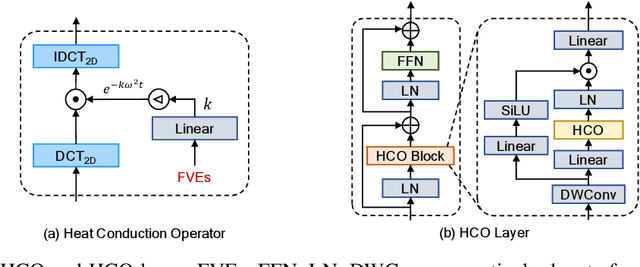

A fundamental problem in learning robust and expressive visual representations lies in efficiently estimating the spatial relationships of visual semantics throughout the entire image. In this study, we propose vHeat, a novel vision backbone model that simultaneously achieves both high computational efficiency and global receptive field. The essential idea, inspired by the physical principle of heat conduction, is to conceptualize image patches as heat sources and model the calculation of their correlations as the diffusion of thermal energy. This mechanism is incorporated into deep models through the newly proposed module, the Heat Conduction Operator (HCO), which is physically plausible and can be efficiently implemented using DCT and IDCT operations with a complexity of $\mathcal{O}(N^{1.5})$. Extensive experiments demonstrate that vHeat surpasses Vision Transformers (ViTs) across various vision tasks, while also providing higher inference speeds, reduced FLOPs, and lower GPU memory usage for high-resolution images. The code will be released at https://github.com/MzeroMiko/vHeat.
ChatterBox: Multi-round Multimodal Referring and Grounding
Jan 24, 2024In this study, we establish a baseline for a new task named multimodal multi-round referring and grounding (MRG), opening up a promising direction for instance-level multimodal dialogues. We present a new benchmark and an efficient vision-language model for this purpose. The new benchmark, named CB-300K, spans challenges including multi-round dialogue, complex spatial relationships among multiple instances, and consistent reasoning, which are beyond those shown in existing benchmarks. The proposed model, named ChatterBox, utilizes a two-branch architecture to collaboratively handle vision and language tasks. By tokenizing instance regions, the language branch acquires the ability to perceive referential information. Meanwhile, ChatterBox feeds a query embedding in the vision branch to a token receiver for visual grounding. A two-stage optimization strategy is devised, making use of both CB-300K and auxiliary external data to improve the model's stability and capacity for instance-level understanding. Experiments show that ChatterBox outperforms existing models in MRG both quantitatively and qualitatively, paving a new path towards multimodal dialogue scenarios with complicated and precise interactions. Code, data, and model are available at: https://github.com/sunsmarterjie/ChatterBox.
VMamba: Visual State Space Model
Jan 18, 2024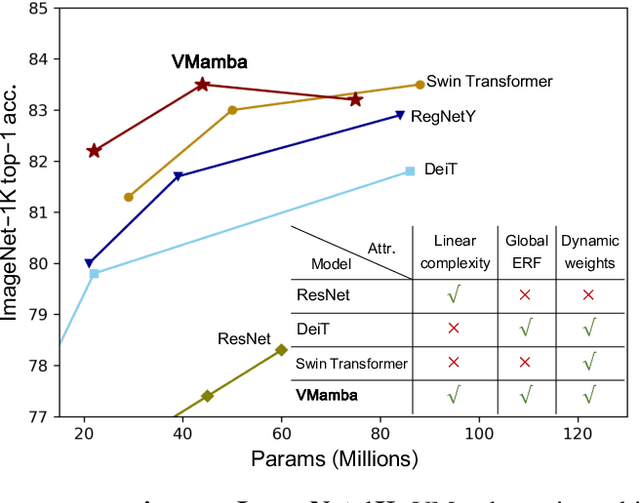
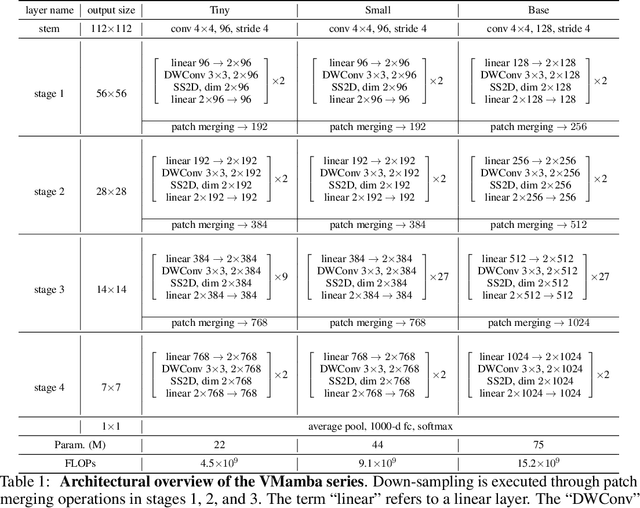
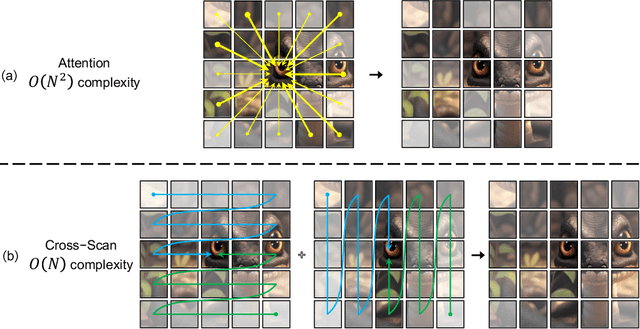
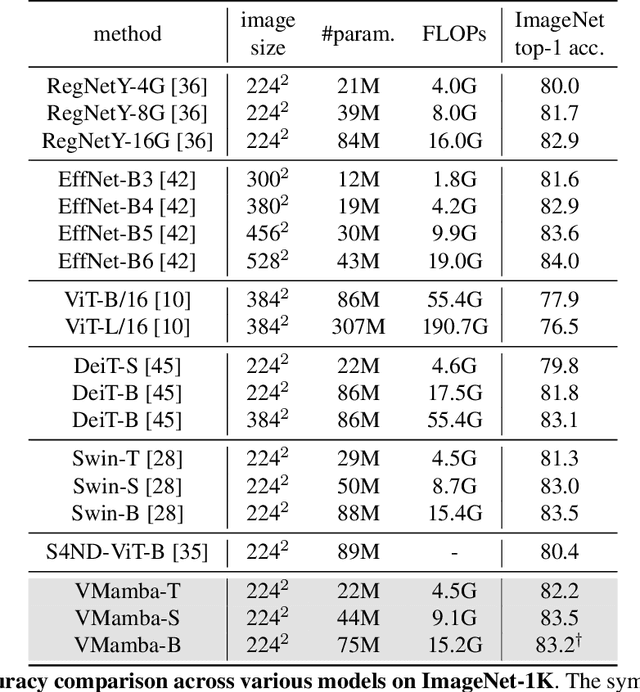
Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) stand as the two most popular foundation models for visual representation learning. While CNNs exhibit remarkable scalability with linear complexity w.r.t. image resolution, ViTs surpass them in fitting capabilities despite contending with quadratic complexity. A closer inspection reveals that ViTs achieve superior visual modeling performance through the incorporation of global receptive fields and dynamic weights. This observation motivates us to propose a novel architecture that inherits these components while enhancing computational efficiency. To this end, we draw inspiration from the recently introduced state space model and propose the Visual State Space Model (VMamba), which achieves linear complexity without sacrificing global receptive fields. To address the encountered direction-sensitive issue, we introduce the Cross-Scan Module (CSM) to traverse the spatial domain and convert any non-causal visual image into order patch sequences. Extensive experimental results substantiate that VMamba not only demonstrates promising capabilities across various visual perception tasks, but also exhibits more pronounced advantages over established benchmarks as the image resolution increases. Source code has been available at https://github.com/MzeroMiko/VMamba.