 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevHeat: Building Vision Models upon Heat Conduction
Paper and Code
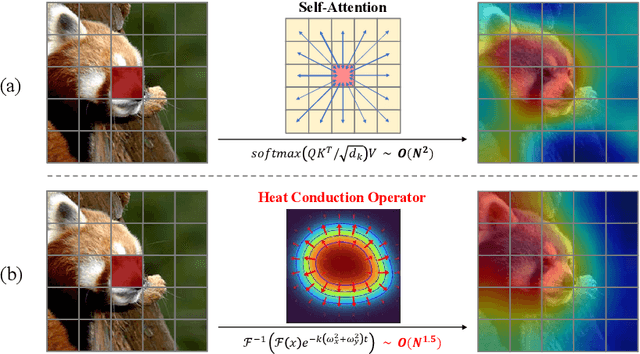

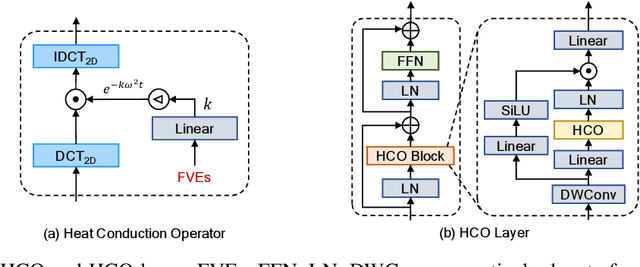

A fundamental problem in learning robust and expressive visual representations lies in efficiently estimating the spatial relationships of visual semantics throughout the entire image. In this study, we propose vHeat, a novel vision backbone model that simultaneously achieves both high computational efficiency and global receptive field. The essential idea, inspired by the physical principle of heat conduction, is to conceptualize image patches as heat sources and model the calculation of their correlations as the diffusion of thermal energy. This mechanism is incorporated into deep models through the newly proposed module, the Heat Conduction Operator (HCO), which is physically plausible and can be efficiently implemented using DCT and IDCT operations with a complexity of $\mathcal{O}(N^{1.5})$. Extensive experiments demonstrate that vHeat surpasses Vision Transformers (ViTs) across various vision tasks, while also providing higher inference speeds, reduced FLOPs, and lower GPU memory usage for high-resolution images. The code will be released at https://github.com/MzeroMiko/vHeat.