 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-Diff: Enhancing Contextual Coherence in Remote Sensing Image Synthesis
Dec 11, 2024Accurately depicting real-world landscapes in remote sensing (RS) images requires precise alignment between objects and their environment. However, most existing synthesis methods for natural images prioritize foreground control, often reducing the background to plain textures. This neglects the interaction between foreground and background, which can lead to incoherence in RS scenarios. In this paper, we introduce CC-Diff, a Diffusion Model-based approach for RS image generation with enhanced Context Coherence. To capture spatial interdependence, we propose a sequential pipeline where background generation is conditioned on synthesized foreground instances. Distinct learnable queries are also employed to model both the complex background texture and its semantic relation to the foreground. Extensive experiments demonstrate that CC-Diff outperforms state-of-the-art methods in visual fidelity, semantic accuracy, and positional precision, excelling in both RS and natural image domains. CC-Diff also shows strong trainability, improving detection accuracy by 2.04 mAP on DOTA and 2.25 mAP on the COCO benchmark.
Vision Calorimeter for Anti-neutron Reconstruction: A Baseline
Aug 20, 2024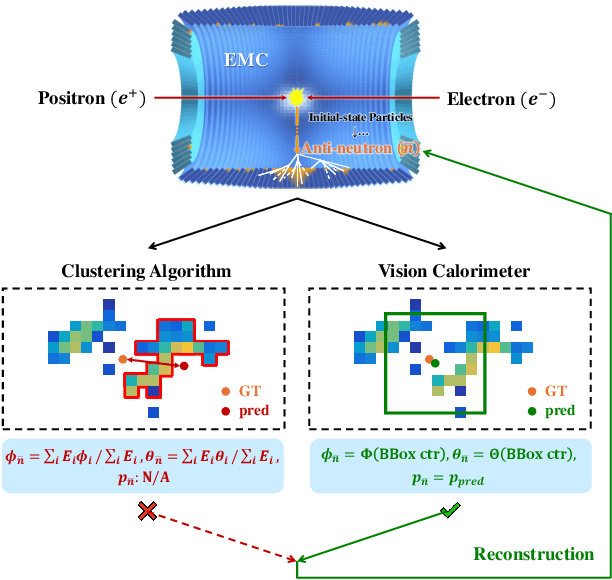



In high-energy physics, anti-neutrons ($\bar{n}$) are fundamental particles that frequently appear as final-state particles, and the reconstruction of their kinematic properties provides an important probe for understanding the governing principles. However, this confronts significant challenges instrumentally with the electromagnetic calorimeter (EMC), a typical experimental sensor but recovering the information of incident $\bar{n}$ insufficiently. In this study, we introduce Vision Calorimeter (ViC), a baseline method for anti-neutron reconstruction that leverages deep learning detectors to analyze the implicit relationships between EMC responses and incident $\bar{n}$ characteristics. Our motivation lies in that energy distributions of $\bar{n}$ samples deposited in the EMC cell arrays embody rich contextual information. Converted to 2-D images, such contextual energy distributions can be used to predict the status of $\bar{n}$ ($i.e.$, incident position and momentum) through a deep learning detector along with pseudo bounding boxes and a specified training objective. Experimental results demonstrate that ViC substantially outperforms the conventional reconstruction approach, reducing the prediction error of incident position by 42.81% (from 17.31$^{\circ}$ to 9.90$^{\circ}$). More importantly, this study for the first time realizes the measurement of incident $\bar{n}$ momentum, underscoring the potential of deep learning detectors for particle reconstruction. Code is available at https://github.com/yuhongtian17/ViC.
vHeat: Building Vision Models upon Heat Conduction
May 26, 2024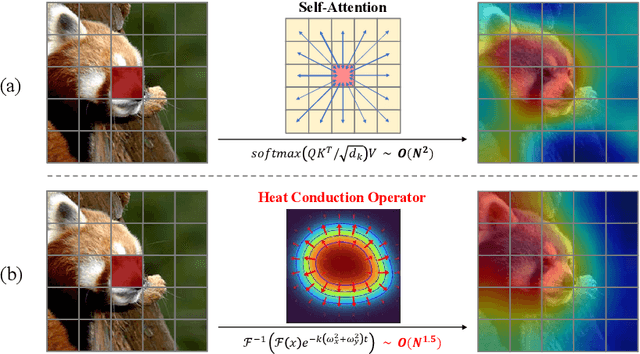

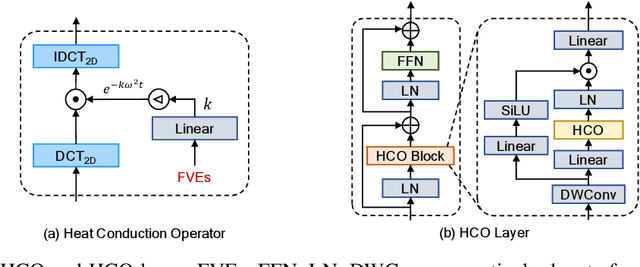

A fundamental problem in learning robust and expressive visual representations lies in efficiently estimating the spatial relationships of visual semantics throughout the entire image. In this study, we propose vHeat, a novel vision backbone model that simultaneously achieves both high computational efficiency and global receptive field. The essential idea, inspired by the physical principle of heat conduction, is to conceptualize image patches as heat sources and model the calculation of their correlations as the diffusion of thermal energy. This mechanism is incorporated into deep models through the newly proposed module, the Heat Conduction Operator (HCO), which is physically plausible and can be efficiently implemented using DCT and IDCT operations with a complexity of $\mathcal{O}(N^{1.5})$. Extensive experiments demonstrate that vHeat surpasses Vision Transformers (ViTs) across various vision tasks, while also providing higher inference speeds, reduced FLOPs, and lower GPU memory usage for high-resolution images. The code will be released at https://github.com/MzeroMiko/vHeat.
VMamba: Visual State Space Model
Jan 18, 2024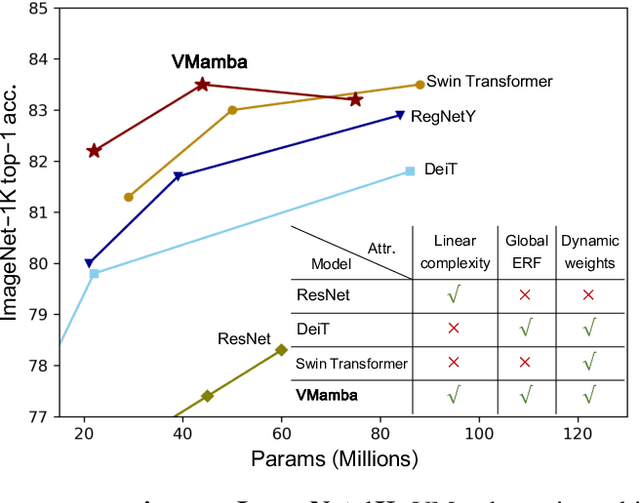
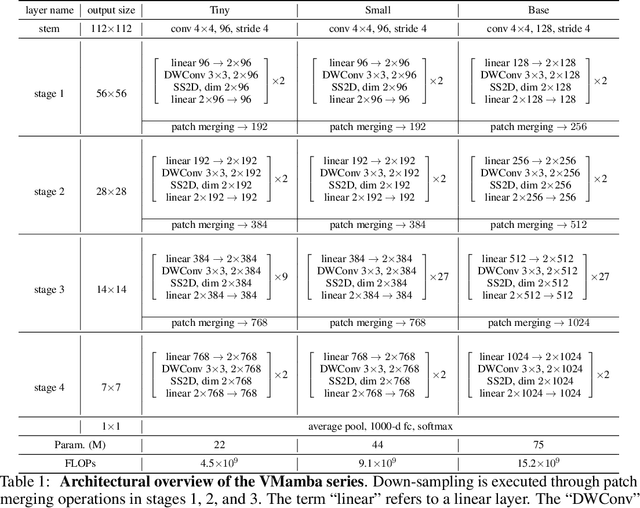
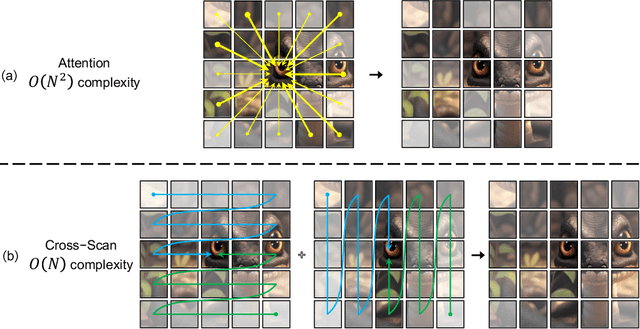
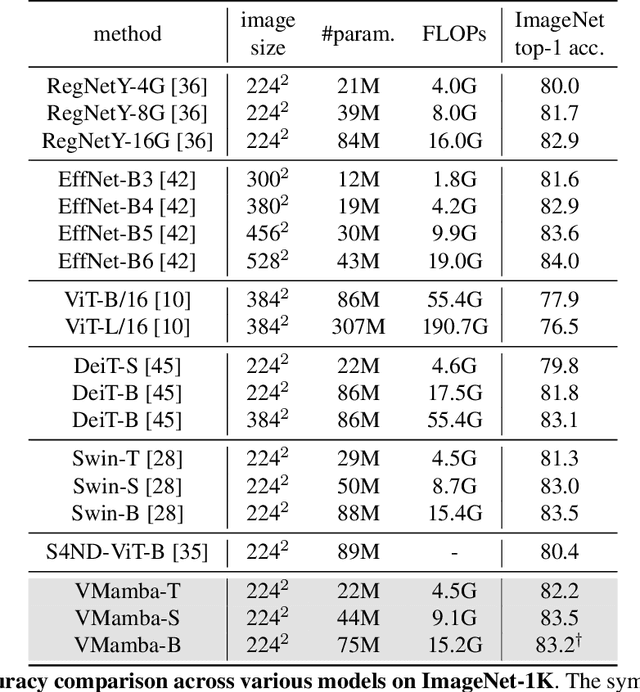
Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) stand as the two most popular foundation models for visual representation learning. While CNNs exhibit remarkable scalability with linear complexity w.r.t. image resolution, ViTs surpass them in fitting capabilities despite contending with quadratic complexity. A closer inspection reveals that ViTs achieve superior visual modeling performance through the incorporation of global receptive fields and dynamic weights. This observation motivates us to propose a novel architecture that inherits these components while enhancing computational efficiency. To this end, we draw inspiration from the recently introduced state space model and propose the Visual State Space Model (VMamba), which achieves linear complexity without sacrificing global receptive fields. To address the encountered direction-sensitive issue, we introduce the Cross-Scan Module (CSM) to traverse the spatial domain and convert any non-causal visual image into order patch sequences. Extensive experimental results substantiate that VMamba not only demonstrates promising capabilities across various visual perception tasks, but also exhibits more pronounced advantages over established benchmarks as the image resolution increases. Source code has been available at https://github.com/MzeroMiko/VMamba.
Spatial Transform Decoupling for Oriented Object Detection
Aug 21, 2023



Vision Transformers (ViTs) have achieved remarkable success in computer vision tasks. However, their potential in rotation-sensitive scenarios has not been fully explored, and this limitation may be inherently attributed to the lack of spatial invariance in the data-forwarding process. In this study, we present a novel approach, termed Spatial Transform Decoupling (STD), providing a simple-yet-effective solution for oriented object detection with ViTs. Built upon stacked ViT blocks, STD utilizes separate network branches to predict the position, size, and angle of bounding boxes, effectively harnessing the spatial transform potential of ViTs in a divide-and-conquer fashion. Moreover, by aggregating cascaded activation masks (CAMs) computed upon the regressed parameters, STD gradually enhances features within regions of interest (RoIs), which complements the self-attention mechanism. Without bells and whistles, STD achieves state-of-the-art performance on the benchmark datasets including DOTA-v1.0 (82.24% mAP) and HRSC2016 (98.55% mAP), which demonstrates the effectiveness of the proposed method. Source code is available at https://github.com/yuhongtian17/Spatial-Transform-Decoupling.