 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Decodes Historical Chinese Archives to Reveal Lost Climate History
Jan 30, 2026Historical archives contain qualitative descriptions of climate events, yet converting these into quantitative records has remained a fundamental challenge. Here we introduce a paradigm shift: a generative AI framework that inverts the logic of historical chroniclers by inferring the quantitative climate patterns associated with documented events. Applied to historical Chinese archives, it produces the sub-annual precipitation reconstruction for southeastern China over the period 1368-1911 AD. Our reconstruction not only quantifies iconic extremes like the Ming Dynasty's Great Drought but also, crucially, maps the full spatial and seasonal structure of El Ni$ñ$o influence on precipitation in this region over five centuries, revealing dynamics inaccessible in shorter modern records. Our methodology and high-resolution climate dataset are directly applicable to climate science and have broader implications for the historical and social sciences.
Bridging the Gap Between Bayesian Deep Learning and Ensemble Weather Forecasts
Nov 18, 2025Weather forecasting is fundamentally challenged by the chaotic nature of the atmosphere, necessitating probabilistic approaches to quantify uncertainty. While traditional ensemble prediction (EPS) addresses this through computationally intensive simulations, recent advances in Bayesian Deep Learning (BDL) offer a promising but often disconnected alternative. We bridge these paradigms through a unified hybrid Bayesian Deep Learning framework for ensemble weather forecasting that explicitly decomposes predictive uncertainty into epistemic and aleatoric components, learned via variational inference and a physics-informed stochastic perturbation scheme modeling flow-dependent atmospheric dynamics, respectively. We further establish a unified theoretical framework that rigorously connects BDL and EPS, providing formal theorems that decompose total predictive uncertainty into epistemic and aleatoric components under the hybrid BDL framework. We validate our framework on the large-scale 40-year ERA5 reanalysis dataset (1979-2019) with 0.25° spatial resolution. Experimental results show that our method not only improves forecast accuracy and yields better-calibrated uncertainty quantification but also achieves superior computational efficiency compared to state-of-the-art probabilistic diffusion models. We commit to making our code open-source upon acceptance of this paper.
WorldGrow: Generating Infinite 3D World
Oct 24, 2025



We tackle the challenge of generating the infinitely extendable 3D world -- large, continuous environments with coherent geometry and realistic appearance. Existing methods face key challenges: 2D-lifting approaches suffer from geometric and appearance inconsistencies across views, 3D implicit representations are hard to scale up, and current 3D foundation models are mostly object-centric, limiting their applicability to scene-level generation. Our key insight is leveraging strong generation priors from pre-trained 3D models for structured scene block generation. To this end, we propose WorldGrow, a hierarchical framework for unbounded 3D scene synthesis. Our method features three core components: (1) a data curation pipeline that extracts high-quality scene blocks for training, making the 3D structured latent representations suitable for scene generation; (2) a 3D block inpainting mechanism that enables context-aware scene extension; and (3) a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity. Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction, while uniquely supporting infinite scene generation with photorealistic and structurally consistent outputs. These results highlight its capability for constructing large-scale virtual environments and potential for building future world models.
Few-step Flow for 3D Generation via Marginal-Data Transport Distillation
Sep 04, 2025Flow-based 3D generation models typically require dozens of sampling steps during inference. Though few-step distillation methods, particularly Consistency Models (CMs), have achieved substantial advancements in accelerating 2D diffusion models, they remain under-explored for more complex 3D generation tasks. In this study, we propose a novel framework, MDT-dist, for few-step 3D flow distillation. Our approach is built upon a primary objective: distilling the pretrained model to learn the Marginal-Data Transport. Directly learning this objective needs to integrate the velocity fields, while this integral is intractable to be implemented. Therefore, we propose two optimizable objectives, Velocity Matching (VM) and Velocity Distillation (VD), to equivalently convert the optimization target from the transport level to the velocity and the distribution level respectively. Velocity Matching (VM) learns to stably match the velocity fields between the student and the teacher, but inevitably provides biased gradient estimates. Velocity Distillation (VD) further enhances the optimization process by leveraging the learned velocity fields to perform probability density distillation. When evaluated on the pioneer 3D generation framework TRELLIS, our method reduces sampling steps of each flow transformer from 25 to 1 or 2, achieving 0.68s (1 step x 2) and 0.94s (2 steps x 2) latency with 9.0x and 6.5x speedup on A800, while preserving high visual and geometric fidelity. Extensive experiments demonstrate that our method significantly outperforms existing CM distillation methods, and enables TRELLIS to achieve superior performance in few-step 3D generation.
Mixpert: Mitigating Multimodal Learning Conflicts with Efficient Mixture-of-Vision-Experts
May 30, 2025Multimodal large language models (MLLMs) require a nuanced interpretation of complex image information, typically leveraging a vision encoder to perceive various visual scenarios. However, relying solely on a single vision encoder to handle diverse task domains proves difficult and inevitably leads to conflicts. Recent work enhances data perception by directly integrating multiple domain-specific vision encoders, yet this structure adds complexity and limits the potential for joint optimization. In this paper, we introduce Mixpert, an efficient mixture-of-vision-experts architecture that inherits the joint learning advantages from a single vision encoder while being restructured into a multi-expert paradigm for task-specific fine-tuning across different visual tasks. Additionally, we design a dynamic routing mechanism that allocates input images to the most suitable visual expert. Mixpert effectively alleviates domain conflicts encountered by a single vision encoder in multi-task learning with minimal additional computational cost, making it more efficient than multiple encoders. Furthermore, Mixpert integrates seamlessly into any MLLM, with experimental results demonstrating substantial performance gains across various tasks.
Tackling View-Dependent Semantics in 3D Language Gaussian Splatting
May 30, 2025Recent advancements in 3D Gaussian Splatting (3D-GS) enable high-quality 3D scene reconstruction from RGB images. Many studies extend this paradigm for language-driven open-vocabulary scene understanding. However, most of them simply project 2D semantic features onto 3D Gaussians and overlook a fundamental gap between 2D and 3D understanding: a 3D object may exhibit various semantics from different viewpoints--a phenomenon we term view-dependent semantics. To address this challenge, we propose LaGa (Language Gaussians), which establishes cross-view semantic connections by decomposing the 3D scene into objects. Then, it constructs view-aggregated semantic representations by clustering semantic descriptors and reweighting them based on multi-view semantics. Extensive experiments demonstrate that LaGa effectively captures key information from view-dependent semantics, enabling a more comprehensive understanding of 3D scenes. Notably, under the same settings, LaGa achieves a significant improvement of +18.7% mIoU over the previous SOTA on the LERF-OVS dataset. Our code is available at: https://github.com/SJTU-DeepVisionLab/LaGa.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
Adaptive Keyframe Sampling for Long Video Understanding
Feb 28, 2025



Multimodal large language models (MLLMs) have enabled open-world visual understanding by injecting visual input as extra tokens into large language models (LLMs) as contexts. However, when the visual input changes from a single image to a long video, the above paradigm encounters difficulty because the vast amount of video tokens has significantly exceeded the maximal capacity of MLLMs. Therefore, existing video-based MLLMs are mostly established upon sampling a small portion of tokens from input data, which can cause key information to be lost and thus produce incorrect answers. This paper presents a simple yet effective algorithm named Adaptive Keyframe Sampling (AKS). It inserts a plug-and-play module known as keyframe selection, which aims to maximize the useful information with a fixed number of video tokens. We formulate keyframe selection as an optimization involving (1) the relevance between the keyframes and the prompt, and (2) the coverage of the keyframes over the video, and present an adaptive algorithm to approximate the best solution. Experiments on two long video understanding benchmarks validate that Adaptive Keyframe Sampling improves video QA accuracy (beyond strong baselines) upon selecting informative keyframes. Our study reveals the importance of information pre-filtering in video-based MLLMs. Code is available at https://github.com/ncTimTang/AKS.
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Dec 12, 2024Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs' generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.
SAM-CP: Marrying SAM with Composable Prompts for Versatile Segmentation
Jul 23, 2024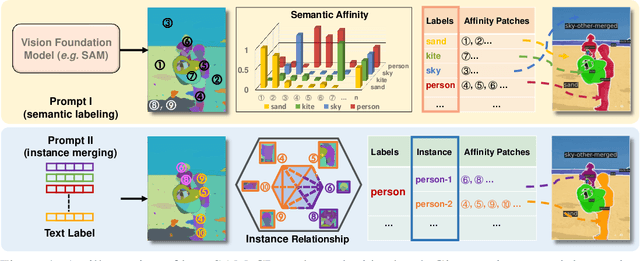
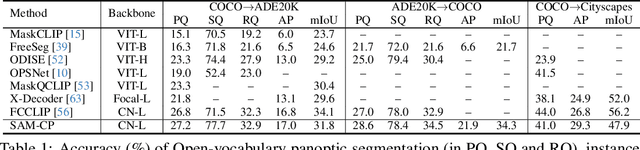

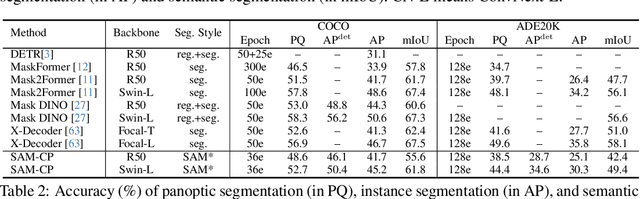
The Segment Anything model (SAM) has shown a generalized ability to group image pixels into patches, but applying it to semantic-aware segmentation still faces major challenges. This paper presents SAM-CP, a simple approach that establishes two types of composable prompts beyond SAM and composes them for versatile segmentation. Specifically, given a set of classes (in texts) and a set of SAM patches, the Type-I prompt judges whether a SAM patch aligns with a text label, and the Type-II prompt judges whether two SAM patches with the same text label also belong to the same instance. To decrease the complexity in dealing with a large number of semantic classes and patches, we establish a unified framework that calculates the affinity between (semantic and instance) queries and SAM patches and merges patches with high affinity to the query. Experiments show that SAM-CP achieves semantic, instance, and panoptic segmentation in both open and closed domains. In particular, it achieves state-of-the-art performance in open-vocabulary segmentation. Our research offers a novel and generalized methodology for equipping vision foundation models like SAM with multi-grained semantic perception abilities.