 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeroGS: Hierarchical Guidance for Robust 3D Gaussian Splatting under Sparse Views
Mar 03, 20263D Gaussian Splatting (3DGS) has recently emerged as a promising approach in novel view synthesis, combining photorealistic rendering with real-time efficiency. However, its success heavily relies on dense camera coverage; under sparse-view conditions, insufficient supervision leads to irregular Gaussian distributions, characterized by globally sparse coverage, blurred background, and distorted high-frequency areas. To address this, we propose HeroGS, Hierarchical Guidance for Robust 3D Gaussian Splatting, a unified framework that establishes hierarchical guidance across the image, feature, and parameter levels. At the image level, sparse supervision is converted into pseudo-dense guidance, globally regularizing the Gaussian distributions and forming a consistent foundation for subsequent optimization. Building upon this, Feature-Adaptive Densification and Pruning (FADP) at the feature level leverages low-level features to refine high-frequency details and adaptively densifies Gaussians in background regions. The optimized distributions then support Co-Pruned Geometry Consistency (CPG) at parameter level, which guides geometric consistency through parameter freezing and co-pruning, effectively removing inconsistent splats. The hierarchical guidance strategy effectively constrains and optimizes the overall Gaussian distributions, thereby enhancing both structural fidelity and rendering quality. Extensive experiments demonstrate that HeroGS achieves high-fidelity reconstructions and consistently surpasses state-of-the-art baselines under sparse-view conditions.
SAPNet++: Evolving Point-Prompted Instance Segmentation with Semantic and Spatial Awareness
Feb 25, 2026Single-point annotation is increasingly prominent in visual tasks for labeling cost reduction. However, it challenges tasks requiring high precision, such as the point-prompted instance segmentation (PPIS) task, which aims to estimate precise masks using single-point prompts to train a segmentation network. Due to the constraints of point annotations, granularity ambiguity and boundary uncertainty arise the difficulty distinguishing between different levels of detail (eg. whole object vs. parts) and the challenge of precisely delineating object boundaries. Previous works have usually inherited the paradigm of mask generation along with proposal selection to achieve PPIS. However, proposal selection relies solely on category information, failing to resolve the ambiguity of different granularity. Furthermore, mask generators offer only finite discrete solutions that often deviate from actual masks, particularly at boundaries. To address these issues, we propose the Semantic-Aware Point-Prompted Instance Segmentation Network (SAPNet). It integrates Point Distance Guidance and Box Mining Strategy to tackle group and local issues caused by the point's granularity ambiguity. Additionally, we incorporate completeness scores within proposals to add spatial granularity awareness, enhancing multiple instance learning (MIL) in proposal selection termed S-MIL. The Multi-level Affinity Refinement conveys pixel and semantic clues, narrowing boundary uncertainty during mask refinement. These modules culminate in SAPNet++, mitigating point prompt's granularity ambiguity and boundary uncertainty and significantly improving segmentation performance. Extensive experiments on four challenging datasets validate the effectiveness of our methods, highlighting the potential to advance PPIS.
* 18 pages
VER-Bench: Evaluating MLLMs on Reasoning with Fine-Grained Visual Evidence
Aug 06, 2025With the rapid development of MLLMs, evaluating their visual capabilities has become increasingly crucial. Current benchmarks primarily fall into two main types: basic perception benchmarks, which focus on local details but lack deep reasoning (e.g., "what is in the image?"), and mainstream reasoning benchmarks, which concentrate on prominent image elements but may fail to assess subtle clues requiring intricate analysis. However, profound visual understanding and complex reasoning depend more on interpreting subtle, inconspicuous local details than on perceiving salient, macro-level objects. These details, though occupying minimal image area, often contain richer, more critical information for robust analysis. To bridge this gap, we introduce the VER-Bench, a novel framework to evaluate MLLMs' ability to: 1) identify fine-grained visual clues, often occupying on average just 0.25% of the image area; 2) integrate these clues with world knowledge for complex reasoning. Comprising 374 carefully designed questions across Geospatial, Temporal, Situational, Intent, System State, and Symbolic reasoning, each question in VER-Bench is accompanied by structured evidence: visual clues and question-related reasoning derived from them. VER-Bench reveals current models' limitations in extracting subtle visual evidence and constructing evidence-based arguments, highlighting the need to enhance models's capabilities in fine-grained visual evidence extraction, integration, and reasoning for genuine visual understanding and human-like analysis. Dataset and additional materials are available https://github.com/verbta/ACMMM-25-Materials.
AD^2-Bench: A Hierarchical CoT Benchmark for MLLM in Autonomous Driving under Adverse Conditions
Jun 11, 2025



Chain-of-Thought (CoT) reasoning has emerged as a powerful approach to enhance the structured, multi-step decision-making capabilities of Multi-Modal Large Models (MLLMs), is particularly crucial for autonomous driving with adverse weather conditions and complex traffic environments. However, existing benchmarks have largely overlooked the need for rigorous evaluation of CoT processes in these specific and challenging scenarios. To address this critical gap, we introduce AD^2-Bench, the first Chain-of-Thought benchmark specifically designed for autonomous driving with adverse weather and complex scenes. AD^2-Bench is meticulously constructed to fulfill three key criteria: comprehensive data coverage across diverse adverse environments, fine-grained annotations that support multi-step reasoning, and a dedicated evaluation framework tailored for assessing CoT performance. The core contribution of AD^2-Bench is its extensive collection of over 5.4k high-quality, manually annotated CoT instances. Each intermediate reasoning step in these annotations is treated as an atomic unit with explicit ground truth, enabling unprecedented fine-grained analysis of MLLMs' inferential processes under text-level, point-level, and region-level visual prompts. Our comprehensive evaluation of state-of-the-art MLLMs on AD^2-Bench reveals accuracy below 60%, highlighting the benchmark's difficulty and the need to advance robust, interpretable end-to-end autonomous driving systems. AD^2-Bench thus provides a standardized evaluation platform, driving research forward by improving MLLMs' reasoning in autonomous driving, making it an invaluable resource.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
Wholly-WOOD: Wholly Leveraging Diversified-quality Labels for Weakly-supervised Oriented Object Detection
Feb 13, 2025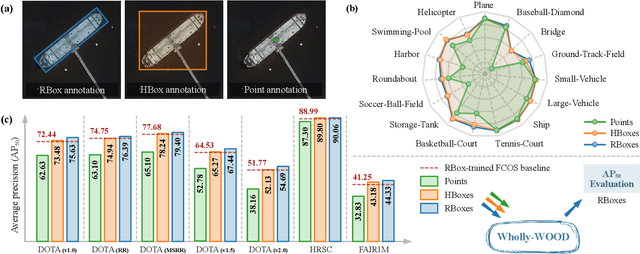
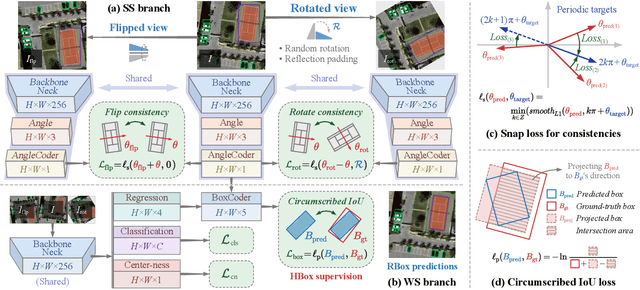
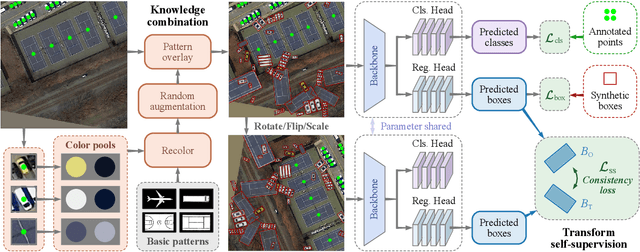
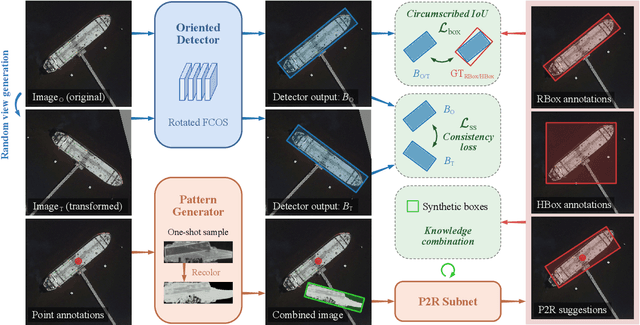
Accurately estimating the orientation of visual objects with compact rotated bounding boxes (RBoxes) has become a prominent demand, which challenges existing object detection paradigms that only use horizontal bounding boxes (HBoxes). To equip the detectors with orientation awareness, supervised regression/classification modules have been introduced at the high cost of rotation annotation. Meanwhile, some existing datasets with oriented objects are already annotated with horizontal boxes or even single points. It becomes attractive yet remains open for effectively utilizing weaker single point and horizontal annotations to train an oriented object detector (OOD). We develop Wholly-WOOD, a weakly-supervised OOD framework, capable of wholly leveraging various labeling forms (Points, HBoxes, RBoxes, and their combination) in a unified fashion. By only using HBox for training, our Wholly-WOOD achieves performance very close to that of the RBox-trained counterpart on remote sensing and other areas, significantly reducing the tedious efforts on labor-intensive annotation for oriented objects. The source codes are available at https://github.com/VisionXLab/whollywood (PyTorch-based) and https://github.com/VisionXLab/whollywood-jittor (Jittor-based).
GaGA: Towards Interactive Global Geolocation Assistant
Dec 12, 2024



Global geolocation, which seeks to predict the geographical location of images captured anywhere in the world, is one of the most challenging tasks in the field of computer vision. In this paper, we introduce an innovative interactive global geolocation assistant named GaGA, built upon the flourishing large vision-language models (LVLMs). GaGA uncovers geographical clues within images and combines them with the extensive world knowledge embedded in LVLMs to determine the geolocations while also providing justifications and explanations for the prediction results. We further designed a novel interactive geolocation method that surpasses traditional static inference approaches. It allows users to intervene, correct, or provide clues for the predictions, making the model more flexible and practical. The development of GaGA relies on the newly proposed Multi-modal Global Geolocation (MG-Geo) dataset, a comprehensive collection of 5 million high-quality image-text pairs. GaGA achieves state-of-the-art performance on the GWS15k dataset, improving accuracy by 4.57% at the country level and 2.92% at the city level, setting a new benchmark. These advancements represent a significant leap forward in developing highly accurate, interactive geolocation systems with global applicability.
ClickTrack: Towards Real-time Interactive Single Object Tracking
Nov 24, 2024



Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
Click; Single Object Tracking; Video Object Segmentation; Real-time Interaction
Nov 20, 2024Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
ViMoE: An Empirical Study of Designing Vision Mixture-of-Experts
Oct 21, 2024



Mixture-of-Experts (MoE) models embody the divide-and-conquer concept and are a promising approach for increasing model capacity, demonstrating excellent scalability across multiple domains. In this paper, we integrate the MoE structure into the classic Vision Transformer (ViT), naming it ViMoE, and explore the potential of applying MoE to vision through a comprehensive study on image classification. However, we observe that the performance is sensitive to the configuration of MoE layers, making it challenging to obtain optimal results without careful design. The underlying cause is that inappropriate MoE layers lead to unreliable routing and hinder experts from effectively acquiring helpful knowledge. To address this, we introduce a shared expert to learn and capture common information, serving as an effective way to construct stable ViMoE. Furthermore, we demonstrate how to analyze expert routing behavior, revealing which MoE layers are capable of specializing in handling specific information and which are not. This provides guidance for retaining the critical layers while removing redundancies, thereby advancing ViMoE to be more efficient without sacrificing accuracy. We aspire for this work to offer new insights into the design of vision MoE models and provide valuable empirical guidance for future research.