 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWholly-WOOD: Wholly Leveraging Diversified-quality Labels for Weakly-supervised Oriented Object Detection
Feb 13, 2025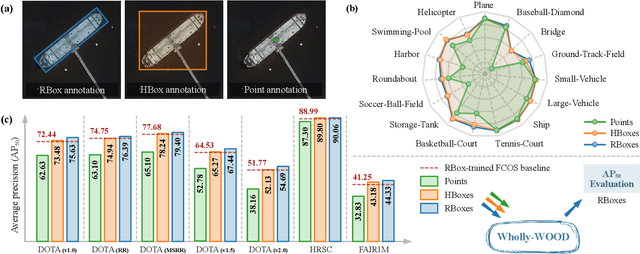
Accurately estimating the orientation of visual objects with compact rotated bounding boxes (RBoxes) has become a prominent demand, which challenges existing object detection paradigms that only use horizontal bounding boxes (HBoxes). To equip the detectors with orientation awareness, supervised regression/classification modules have been introduced at the high cost of rotation annotation. Meanwhile, some existing datasets with oriented objects are already annotated with horizontal boxes or even single points. It becomes attractive yet remains open for effectively utilizing weaker single point and horizontal annotations to train an oriented object detector (OOD). We develop Wholly-WOOD, a weakly-supervised OOD framework, capable of wholly leveraging various labeling forms (Points, HBoxes, RBoxes, and their combination) in a unified fashion. By only using HBox for training, our Wholly-WOOD achieves performance very close to that of the RBox-trained counterpart on remote sensing and other areas, significantly reducing the tedious efforts on labor-intensive annotation for oriented objects. The source codes are available at https://github.com/VisionXLab/whollywood (PyTorch-based) and https://github.com/VisionXLab/whollywood-jittor (Jittor-based).
Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances
Feb 07, 2025



With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning OOD from point annotations has gained great attention. In this paper, we rethink this challenging task setting with the layout among instances and present Point2RBox-v2. At the core are three principles: 1) Gaussian overlap loss. It learns an upper bound for each instance by treating objects as 2D Gaussian distributions and minimizing their overlap. 2) Voronoi watershed loss. It learns a lower bound for each instance through watershed on Voronoi tessellation. 3) Consistency loss. It learns the size/rotation variation between two output sets with respect to an input image and its augmented view. Supplemented by a few devised techniques, e.g. edge loss and copy-paste, the detector is further enhanced. To our best knowledge, Point2RBox-v2 is the first approach to explore the spatial layout among instances for learning point-supervised OOD. Our solution is elegant and lightweight, yet it is expected to give a competitive performance especially in densely packed scenes: 62.61%/86.15%/34.71% on DOTA/HRSC/FAIR1M. Code is available at https://github.com/VisionXLab/point2rbox-v2.
Parallax-Tolerant Image Stitching with Epipolar Displacement Field
Nov 28, 2023Large parallax image stitching is a challenging task. Existing methods often struggle to maintain both the local and global structures of the image while reducing alignment artifacts and warping distortions. In this paper, we propose a novel approach that utilizes epipolar geometry to establish a warping technique based on the epipolar displacement field. Initially, the warping rule for pixels in the epipolar geometry is established through the infinite homography. Subsequently, Subsequently, the epipolar displacement field, which represents the sliding distance of the warped pixel along the epipolar line, is formulated by thin plate splines based on the principle of local elastic deformation. The stitching result can be generated by inversely warping the pixels according to the epipolar displacement field. This method incorporates the epipolar constraints in the warping rule, which ensures high-quality alignment and maintains the projectivity of the panorama. Qualitative and quantitative comparative experiments demonstrate the competitiveness of the proposed method in stitching images large parallax.
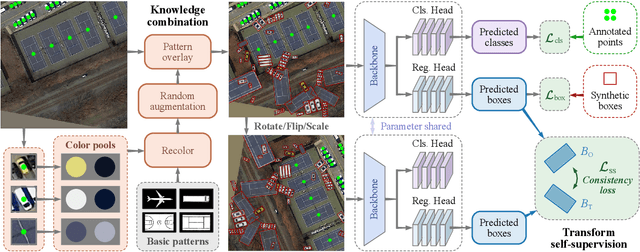
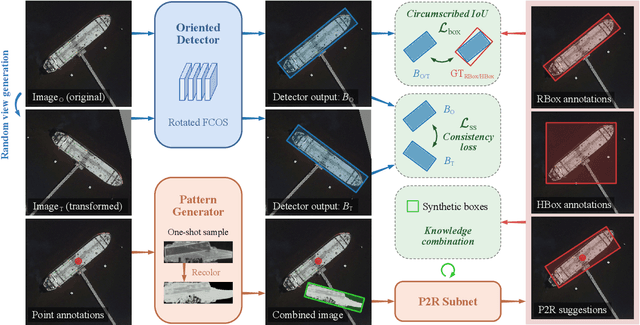
Point2RBox: Combine Knowledge from Synthetic Visual Patterns for End-to-end Oriented Object Detection with Single Point Supervision
Nov 23, 2023With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning rotated box (RBox) from the horizontal box (HBox) has attracted more and more attention. In this paper, we explore a more challenging yet label-efficient setting, namely single point-supervised OOD, and present our approach called Point2RBox. Specifically, we propose to leverage two principles: 1) Synthetic pattern knowledge combination: By sampling around each labelled point on the image, we transfer the object feature to synthetic visual patterns with the known bounding box to provide the knowledge for box regression. 2) Transform self-supervision: With a transformed input image (e.g. scaled/rotated), the output RBoxes are trained to follow the same transformation so that the network can perceive the relative size/rotation between objects. The detector is further enhanced by a few devised techniques to cope with peripheral issues, e.g. the anchor/layer assignment as the size of the object is not available in our point supervision setting. To our best knowledge, Point2RBox is the first end-to-end solution for point-supervised OOD. In particular, our method uses a lightweight paradigm, yet it achieves a competitive performance among point-supervised alternatives, 41.05%/27.62%/80.01% on DOTA/DIOR/HRSC datasets.
MLP-AMDC: An MLP Architecture for Adaptive-Mask-based Dual-Camera snapshot hyperspectral imaging
Oct 12, 2023



Coded Aperture Snapshot Spectral Imaging (CASSI) system has great advantages over traditional methods in dynamically acquiring Hyper-Spectral Image (HSI), but there are the following problems. 1) Traditional mask relies on random patterns or analytical design, both of which limit the performance improvement of CASSI. 2) Existing high-quality reconstruction algorithms are slow in reconstruction and can only reconstruct scene information offline. To address the above two problems, this paper designs the AMDC-CASSI system, introducing RGB camera with CASSI based on Adaptive-Mask as multimodal input to improve the reconstruction quality. The existing SOTA reconstruction schemes are based on transformer, but the operation of self-attention pulls down the operation efficiency of the network. In order to improve the inference speed of the reconstruction network, this paper proposes An MLP Architecture for Adaptive-Mask-based Dual-Camera (MLP-AMDC) to replace the transformer structure of the network. Numerous experiments have shown that MLP performs no less well than transformer-based structures for HSI reconstruction, while MLP greatly improves the network inference speed and has less number of parameters and operations, our method has a 8 db improvement over SOTA and at least a 5-fold improvement in reconstruction speed. (https://github.com/caizeyu1992/MLP-AMDC.)
DMDC: Dynamic-mask-based dual camera design for snapshot Hyperspectral Imaging
Aug 03, 2023Deep learning methods are developing rapidly in coded aperture snapshot spectral imaging (CASSI). The number of parameters and FLOPs of existing state-of-the-art methods (SOTA) continues to increase, but the reconstruction accuracy improves slowly. Current methods still face two problems: 1) The performance of the spatial light modulator (SLM) is not fully developed due to the limitation of fixed Mask coding. 2) The single input limits the network performance. In this paper we present a dynamic-mask-based dual camera system, which consists of an RGB camera and a CASSI system running in parallel. First, the system learns the spatial feature distribution of the scene based on the RGB images, then instructs the SLM to encode each scene, and finally sends both RGB and CASSI images to the network for reconstruction. We further designed the DMDC-net, which consists of two separate networks, a small-scale CNN-based dynamic mask network for dynamic adjustment of the mask and a multimodal reconstruction network for reconstruction using RGB and CASSI measurements. Extensive experiments on multiple datasets show that our method achieves more than 9 dB improvement in PSNR over the SOTA. (https://github.com/caizeyu1992/DMDC)
Dual-Side Feature Fusion 3D Pose Transfer
May 24, 20233D pose transfer solves the problem of additional input and correspondence of traditional deformation transfer, only the source and target meshes need to be input, and the pose of the source mesh can be transferred to the target mesh. Some lightweight methods proposed in recent years consume less memory but cause spikes and distortions for some unseen poses, while others are costly in training due to the inclusion of large matrix multiplication and adversarial networks. In addition, the meshes with different numbers of vertices also increase the difficulty of pose transfer. In this work, we propose a Dual-Side Feature Fusion Pose Transfer Network to improve the pose transfer accuracy of the lightweight method. Our method takes the pose features as one of the side inputs to the decoding network and fuses them into the target mesh layer by layer at multiple scales. Our proposed Feature Fusion Adaptive Instance Normalization has the characteristic of having two side input channels that fuse pose features and identity features as denormalization parameters, thus enhancing the pose transfer capability of the network. Extensive experimental results show that our proposed method has stronger pose transfer capability than state-of-the-art methods while maintaining a lightweight network structure, and can converge faster.
SST-ReversibleNet: Reversible-prior-based Spectral-Spatial Transformer for Efficient Hyperspectral Image Reconstruction
May 06, 2023



Spectral image reconstruction is an important task in snapshot compressed imaging. This paper aims to propose a new end-to-end framework with iterative capabilities similar to a deep unfolding network to improve reconstruction accuracy, independent of optimization conditions, and to reduce the number of parameters. A novel framework called the reversible-prior-based method is proposed. Inspired by the reversibility of the optical path, the reversible-prior-based framework projects the reconstructions back into the measurement space, and then the residuals between the projected data and the real measurements are fed into the network for iteration. The reconstruction subnet in the network then learns the mapping of the residuals to the true values to improve reconstruction accuracy. In addition, a novel spectral-spatial transformer is proposed to account for the global correlation of spectral data in both spatial and spectral dimensions while balancing network depth and computational complexity, in response to the shortcomings of existing transformer-based denoising modules that ignore spatial texture features or learn local spatial features at the expense of global spatial features. Extensive experiments show that our SST-ReversibleNet significantly outperforms state-of-the-art methods on simulated and real HSI datasets, while requiring lower computational and storage costs. https://github.com/caizeyu1992/SST
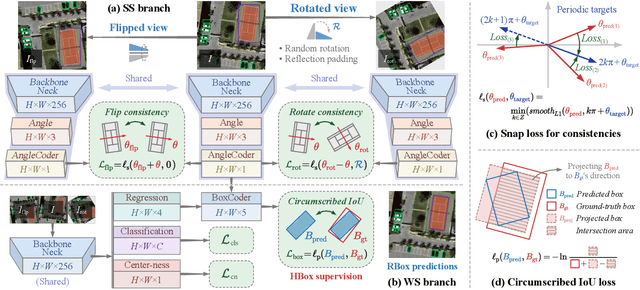
H2RBox-v2: Boosting HBox-supervised Oriented Object Detection via Symmetric Learning
Apr 11, 2023With the increasing demand for oriented object detection e.g. in autonomous driving and remote sensing, the oriented annotation has become a labor-intensive work. To make full use of existing horizontally annotated datasets and reduce the annotation cost, a weakly-supervised detector H2RBox for learning the rotated box (RBox) from the horizontal box (HBox) has been proposed and received great attention. This paper presents a new version, H2RBox-v2, to further bridge the gap between HBox-supervised and RBox-supervised oriented object detection. While exploiting axisymmetry via flipping and rotating consistencies is available through our theoretical analysis, H2RBox-v2, using a weakly-supervised branch similar to H2RBox, is embedded with a novel self-supervised branch that learns orientations from the symmetry inherent in the image of objects. Complemented by modules to cope with peripheral issues, e.g. angular periodicity, a stable and effective solution is achieved. To our knowledge, H2RBox-v2 is the first symmetry-supervised paradigm for oriented object detection. Compared to H2RBox, our method is less susceptible to low annotation quality and insufficient training data, which in such cases is expected to give a competitive performance much closer to fully-supervised oriented object detectors. Specifically, the performance comparison between H2RBox-v2 and Rotated FCOS on DOTA-v1.0/1.5/2.0 is 72.31%/64.76%/50.33% vs. 72.44%/64.53%/51.77%, 89.66% vs. 88.99% on HRSC, and 42.27% vs. 41.25% on FAIR1M.
Phase-Shifting Coder: Predicting Accurate Orientation in Oriented Object Detection
Nov 11, 2022



With the vigorous development of computer vision, oriented object detection has gradually been featured. In this paper, a novel differentiable angle coder named phase-shifting coder (PSC) is proposed to accurately predict the orientation of objects, along with a dual-frequency version PSCD. By mapping rotational periodicity of different cycles into phase of different frequencies, we provide a unified framework for various periodic fuzzy problems in oriented object detection. Upon such framework, common problems in oriented object detection such as boundary discontinuity and square-like problems are elegantly solved in a unified form. Visual analysis and experiments on three datasets prove the effectiveness and the potentiality of our approach. When facing scenarios requiring high-quality bounding boxes, the proposed methods are expected to give a competitive performance. The codes are publicly available at https://github.com/open-mmlab/mmrotate.