 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey-Gram: Extensible World Knowledge for Embodied Manipulation
May 18, 2026Embodied control increasingly requires models to follow compositional language instructions while reasoning over dynamic visual states. However, current vision-language-action policies and world-action models often couple linguistic knowledge with visual computation in a shared backbone or conditioning pathway, leading to modality competition and making knowledge extension dependent on backbone updates. In this paper, we introduce Key-Gram, a conditional-memory framework that separates language-derived world knowledge from visual-state reasoning for embodied control. At its core is a memory module that decomposes an instruction into task-specific key-grams, retrieves static linguistic priors through deterministic hashed lookup, and injects the retrieved entries into selected hidden layers through context-aware gating and lightweight convolutional fusion. This design allows the backbone to devote its main capacity to visual reasoning and action inference, while reusable instruction knowledge is stored in an extensible external memory. The logical memory table can be conveniently partitioned during training and, due to its $O(1)$ lookup pattern, efficiently placed on host memory during inference. Across RoboTwin2.0, LIBERO/LIBERO-Plus, and real-world dual-arm manipulation, Key-Gram consistently improves both $π_{0}$ and $π_{0.5}$ backbones, with average relative gains of $29.5\%/9.9\%$ on RoboTwin2.0, $35.8\%/4.5\%$ on LIBERO-Plus transfer without target-domain fine-tuning, and $15.4\%/8.1\%$ on real-world long-horizon tasks. These results demonstrate that externalized linguistic memory provides an effective and extensible mechanism for improving compositional grounding, transfer, and real-world manipulation.
AstraNav-Memory: Contexts Compression for Long Memory
Dec 25, 2025Lifelong embodied navigation requires agents to accumulate, retain, and exploit spatial-semantic experience across tasks, enabling efficient exploration in novel environments and rapid goal reaching in familiar ones. While object-centric memory is interpretable, it depends on detection and reconstruction pipelines that limit robustness and scalability. We propose an image-centric memory framework that achieves long-term implicit memory via an efficient visual context compression module end-to-end coupled with a Qwen2.5-VL-based navigation policy. Built atop a ViT backbone with frozen DINOv3 features and lightweight PixelUnshuffle+Conv blocks, our visual tokenizer supports configurable compression rates; for example, under a representative 16$\times$ compression setting, each image is encoded with about 30 tokens, expanding the effective context capacity from tens to hundreds of images. Experimental results on GOAT-Bench and HM3D-OVON show that our method achieves state-of-the-art navigation performance, improving exploration in unfamiliar environments and shortening paths in familiar ones. Ablation studies further reveal that moderate compression provides the best balance between efficiency and accuracy. These findings position compressed image-centric memory as a practical and scalable interface for lifelong embodied agents, enabling them to reason over long visual histories and navigate with human-like efficiency.
AstraNav-World: World Model for Foresight Control and Consistency
Dec 25, 2025Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.
Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances
Feb 07, 2025



With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning OOD from point annotations has gained great attention. In this paper, we rethink this challenging task setting with the layout among instances and present Point2RBox-v2. At the core are three principles: 1) Gaussian overlap loss. It learns an upper bound for each instance by treating objects as 2D Gaussian distributions and minimizing their overlap. 2) Voronoi watershed loss. It learns a lower bound for each instance through watershed on Voronoi tessellation. 3) Consistency loss. It learns the size/rotation variation between two output sets with respect to an input image and its augmented view. Supplemented by a few devised techniques, e.g. edge loss and copy-paste, the detector is further enhanced. To our best knowledge, Point2RBox-v2 is the first approach to explore the spatial layout among instances for learning point-supervised OOD. Our solution is elegant and lightweight, yet it is expected to give a competitive performance especially in densely packed scenes: 62.61%/86.15%/34.71% on DOTA/HRSC/FAIR1M. Code is available at https://github.com/VisionXLab/point2rbox-v2.
ArtFormer: Controllable Generation of Diverse 3D Articulated Objects
Dec 10, 2024This paper presents a novel framework for modeling and conditional generation of 3D articulated objects. Troubled by flexibility-quality tradeoffs, existing methods are often limited to using predefined structures or retrieving shapes from static datasets. To address these challenges, we parameterize an articulated object as a tree of tokens and employ a transformer to generate both the object's high-level geometry code and its kinematic relations. Subsequently, each sub-part's geometry is further decoded using a signed-distance-function (SDF) shape prior, facilitating the synthesis of high-quality 3D shapes. Our approach enables the generation of diverse objects with high-quality geometry and varying number of parts. Comprehensive experiments on conditional generation from text descriptions demonstrate the effectiveness and flexibility of our method.
PointOBB-v2: Towards Simpler, Faster, and Stronger Single Point Supervised Oriented Object Detection
Oct 10, 2024



Single point supervised oriented object detection has gained attention and made initial progress within the community. Diverse from those approaches relying on one-shot samples or powerful pretrained models (e.g. SAM), PointOBB has shown promise due to its prior-free feature. In this paper, we propose PointOBB-v2, a simpler, faster, and stronger method to generate pseudo rotated boxes from points without relying on any other prior. Specifically, we first generate a Class Probability Map (CPM) by training the network with non-uniform positive and negative sampling. We show that the CPM is able to learn the approximate object regions and their contours. Then, Principal Component Analysis (PCA) is applied to accurately estimate the orientation and the boundary of objects. By further incorporating a separation mechanism, we resolve the confusion caused by the overlapping on the CPM, enabling its operation in high-density scenarios. Extensive comparisons demonstrate that our method achieves a training speed 15.58x faster and an accuracy improvement of 11.60%/25.15%/21.19% on the DOTA-v1.0/v1.5/v2.0 datasets compared to the previous state-of-the-art, PointOBB. This significantly advances the cutting edge of single point supervised oriented detection in the modular track.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024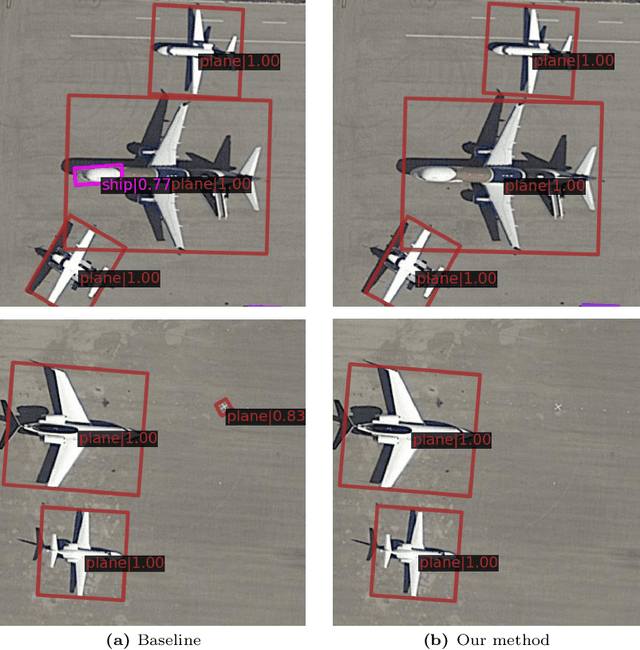

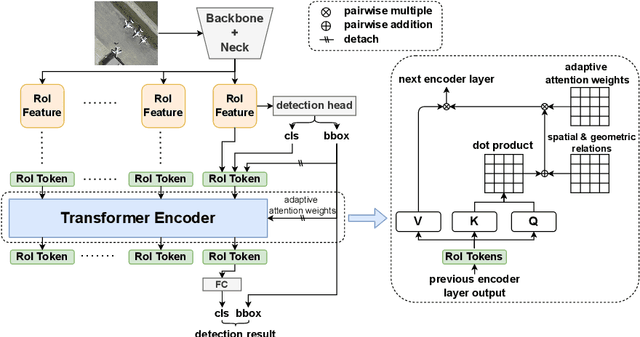

In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
Feedback RoI Features Improve Aerial Object Detection
Nov 28, 2023



Neuroscience studies have shown that the human visual system utilizes high-level feedback information to guide lower-level perception, enabling adaptation to signals of different characteristics. In light of this, we propose Feedback multi-Level feature Extractor (Flex) to incorporate a similar mechanism for object detection. Flex refines feature selection based on image-wise and instance-level feedback information in response to image quality variation and classification uncertainty. Experimental results show that Flex offers consistent improvement to a range of existing SOTA methods on the challenging aerial object detection datasets including DOTA-v1.0, DOTA-v1.5, and HRSC2016. Although the design originates in aerial image detection, further experiments on MS COCO also reveal our module's efficacy in general detection models. Quantitative and qualitative analyses indicate that the improvements are closely related to image qualities, which match our motivation.
Improving Scene Graph Generation with Superpixel-Based Interaction Learning
Aug 04, 2023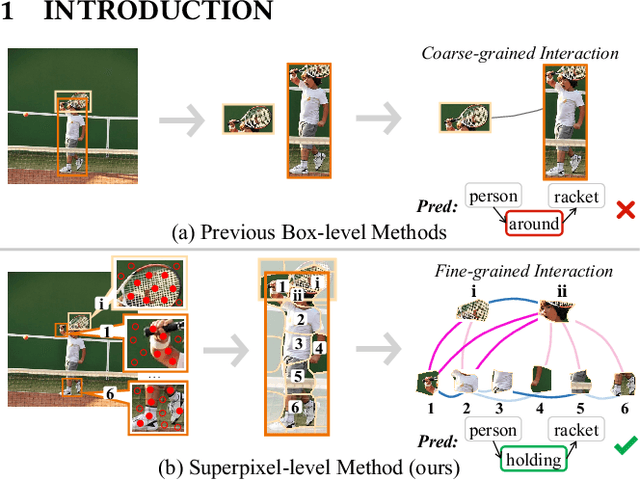
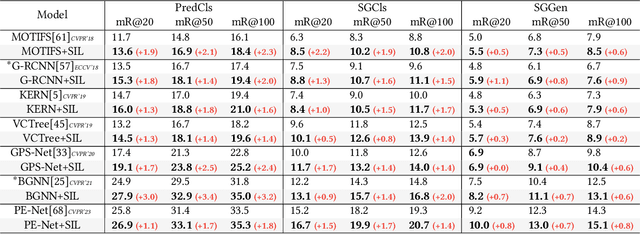

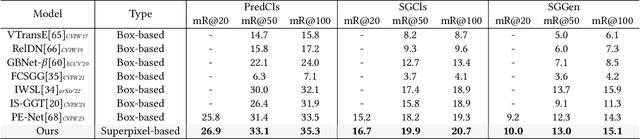
Recent advances in Scene Graph Generation (SGG) typically model the relationships among entities utilizing box-level features from pre-defined detectors. We argue that an overlooked problem in SGG is the coarse-grained interactions between boxes, which inadequately capture contextual semantics for relationship modeling, practically limiting the development of the field. In this paper, we take the initiative to explore and propose a generic paradigm termed Superpixel-based Interaction Learning (SIL) to remedy coarse-grained interactions at the box level. It allows us to model fine-grained interactions at the superpixel level in SGG. Specifically, (i) we treat a scene as a set of points and cluster them into superpixels representing sub-regions of the scene. (ii) We explore intra-entity and cross-entity interactions among the superpixels to enrich fine-grained interactions between entities at an earlier stage. Extensive experiments on two challenging benchmarks (Visual Genome and Open Image V6) prove that our SIL enables fine-grained interaction at the superpixel level above previous box-level methods, and significantly outperforms previous state-of-the-art methods across all metrics. More encouragingly, the proposed method can be applied to boost the performance of existing box-level approaches in a plug-and-play fashion. In particular, SIL brings an average improvement of 2.0% mR (even up to 3.4%) of baselines for the PredCls task on Visual Genome, which facilitates its integration into any existing box-level method.