 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Detection in Aerial Images by Capturing Inter-Object Relationships
Paper and Code
Apr 05, 2024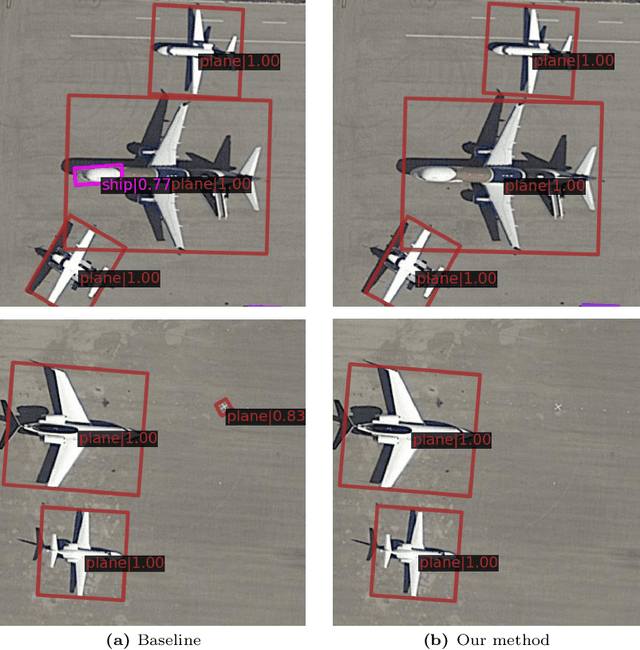

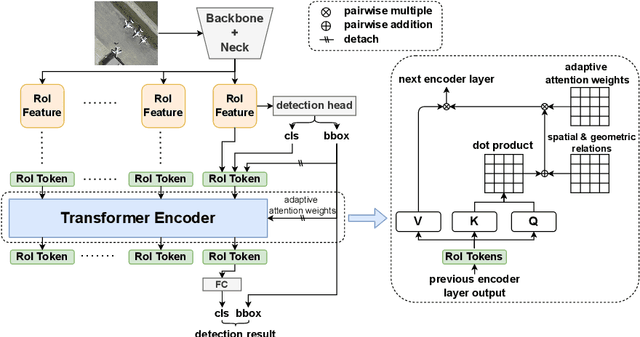

In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.