 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Language: Grounding Referring Expressions with Hand Pointing in Egocentric Vision
Mar 27, 2026Traditional Visual Grounding (VG) predominantly relies on textual descriptions to localize objects, a paradigm that inherently struggles with linguistic ambiguity and often ignores non-verbal deictic cues prevalent in real-world interactions. In natural egocentric engagements, hand-pointing combined with speech forms the most intuitive referring mechanism. To bridge this gap, we introduce EgoPoint-Ground, the first large-scale multimodal dataset dedicated to egocentric deictic visual grounding. Comprising over \textbf{15k} interactive samples in complex scenes, the dataset provides rich, multi-grained annotations including hand-target bounding box pairs and dense semantic captions. We establish a comprehensive benchmark for hand-pointing referring expression resolution, evaluating a wide spectrum of mainstream Multimodal Large Language Models (MLLMs) and state-of-the-art VG architectures. Furthermore, we propose SV-CoT, a novel baseline framework that reformulates grounding as a structured inference process, synergizing gestural and linguistic cues through a Visual Chain-of-Thought paradigm. Extensive experiments demonstrate that SV-CoT achieves an $\textbf{11.7\%}$ absolute improvement over existing methods, effectively mitigating semantic ambiguity and advancing the capability of agents to comprehend multimodal physical intents. The dataset and code will be made publicly available.
Exploring Timeline Control for Facial Motion Generation
May 27, 2025This paper introduces a new control signal for facial motion generation: timeline control. Compared to audio and text signals, timelines provide more fine-grained control, such as generating specific facial motions with precise timing. Users can specify a multi-track timeline of facial actions arranged in temporal intervals, allowing precise control over the timing of each action. To model the timeline control capability, We first annotate the time intervals of facial actions in natural facial motion sequences at a frame-level granularity. This process is facilitated by Toeplitz Inverse Covariance-based Clustering to minimize human labor. Based on the annotations, we propose a diffusion-based generation model capable of generating facial motions that are natural and accurately aligned with input timelines. Our method supports text-guided motion generation by using ChatGPT to convert text into timelines. Experimental results show that our method can annotate facial action intervals with satisfactory accuracy, and produces natural facial motions accurately aligned with timelines.
PointOBB-v2: Towards Simpler, Faster, and Stronger Single Point Supervised Oriented Object Detection
Oct 10, 2024



Single point supervised oriented object detection has gained attention and made initial progress within the community. Diverse from those approaches relying on one-shot samples or powerful pretrained models (e.g. SAM), PointOBB has shown promise due to its prior-free feature. In this paper, we propose PointOBB-v2, a simpler, faster, and stronger method to generate pseudo rotated boxes from points without relying on any other prior. Specifically, we first generate a Class Probability Map (CPM) by training the network with non-uniform positive and negative sampling. We show that the CPM is able to learn the approximate object regions and their contours. Then, Principal Component Analysis (PCA) is applied to accurately estimate the orientation and the boundary of objects. By further incorporating a separation mechanism, we resolve the confusion caused by the overlapping on the CPM, enabling its operation in high-density scenarios. Extensive comparisons demonstrate that our method achieves a training speed 15.58x faster and an accuracy improvement of 11.60%/25.15%/21.19% on the DOTA-v1.0/v1.5/v2.0 datasets compared to the previous state-of-the-art, PointOBB. This significantly advances the cutting edge of single point supervised oriented detection in the modular track.
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Sep 14, 2024



Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Aug 30, 2024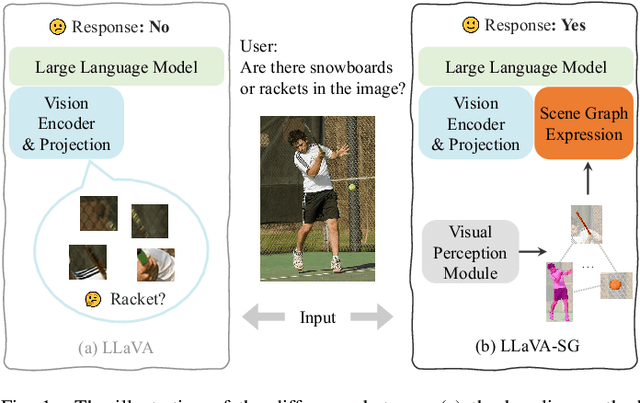
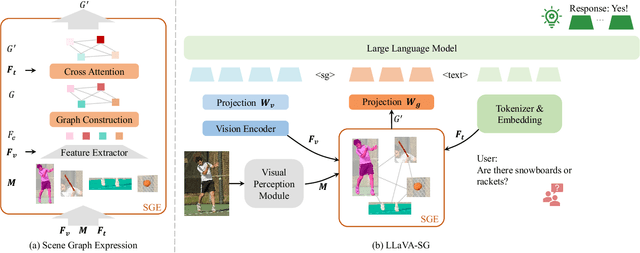

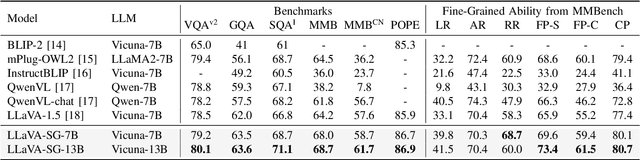
Recent advances in large vision-language models (VLMs) typically employ vision encoders based on the Vision Transformer (ViT) architecture. The division of the images into patches by ViT results in a fragmented perception, thereby hindering the visual understanding capabilities of VLMs. In this paper, we propose an innovative enhancement to address this limitation by introducing a Scene Graph Expression (SGE) module in VLMs. This module extracts and structurally expresses the complex semantic information within images, thereby improving the foundational perception and understanding abilities of VLMs. Extensive experiments demonstrate that integrating our SGE module significantly enhances the VLM's performance in vision-language tasks, indicating its effectiveness in preserving intricate semantic details and facilitating better visual understanding.
Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos
Aug 26, 2024Multi-modal large language models (MLLMs) have demonstrated considerable potential across various downstream tasks that require cross-domain knowledge. MLLMs capable of processing videos, known as Video-MLLMs, have attracted broad interest in video-language understanding. However, videos, especially long videos, contain more visual tokens than images, making them difficult for LLMs to process. Existing works either downsample visual features or extend the LLM context size, risking the loss of high-resolution information or slowing down inference speed. To address these limitations, we apply cross-attention layers in the intermediate projector between the visual encoder and the large language model (LLM). As the naive cross-attention mechanism is insensitive to temporal order, we further introduce causal cross-attention masks (CCAMs) within the cross-attention layers. This Video-MLLM, named Video-CCAM, is trained in a straightforward two-stage fashion: feature alignment and visual instruction tuning. We develop several Video-CCAM models based on LLMs of different sizes (4B, 9B, and 14B). Video-CCAM proves to be a robust Video-MLLM and shows outstanding performance from short videos to long ones. Among standard video benchmarks like MVBench and VideoChatGPT-QA, Video-CCAM shows outstanding performances (1st/2nd/3rd in MVBench and TGIF-QA, 2nd/3rd/4th in MSVD-QA, MSRVTT-QA, and ActivityNet-QA). In benchmarks encompassing long videos, Video-CCAM models can be directly adapted to long video understanding and still achieve exceptional scores despite being trained solely with images and 16-frame videos. Using 96 frames (6$\times$ the training number of frames), Video-CCAM models rank 1st/2nd/3rd in VideoVista and 1st/2nd/4th in MLVU among all open-source Video-MLLMs, respectively. The code is publicly available in \url{https://github.com/QQ-MM/Video-CCAM}.
Unifying 3D Vision-Language Understanding via Promptable Queries
May 19, 2024



A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning. This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view images) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training. Tested across ten diverse 3D-VL datasets, PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state-of-the-art on ScanNet200 by 1.8% (AP), ScanRefer by 5.4% (acc@0.5), Multi3DRefer by 11.7% (F1@0.5), and Scan2Cap by 13.4% (CIDEr@0.5). Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024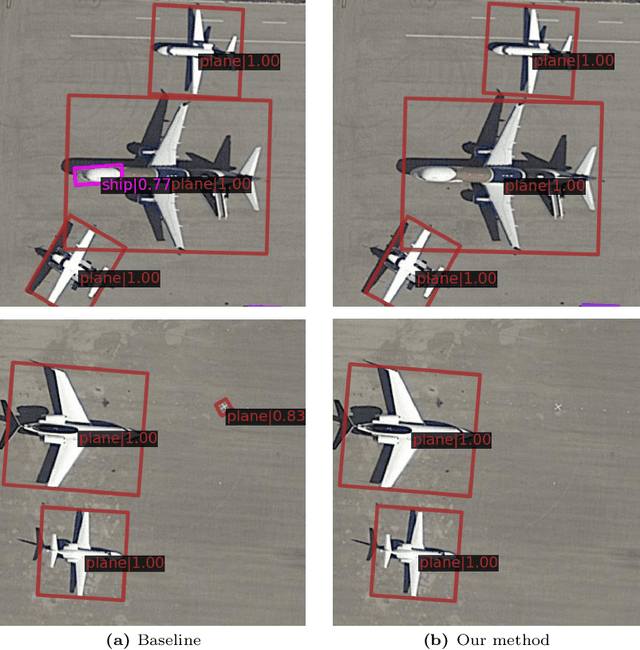

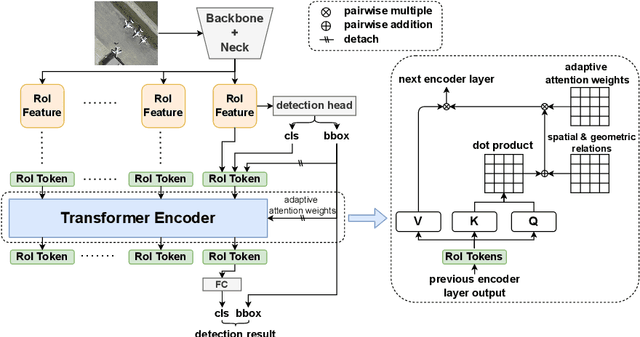

In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models
Dec 15, 2023Diffusion models have shown remarkable success in a variety of downstream generative tasks, yet remain under-explored in the important and challenging expressive talking head generation. In this work, we propose a DreamTalk framework to fulfill this gap, which employs meticulous design to unlock the potential of diffusion models in generating expressive talking heads. Specifically, DreamTalk consists of three crucial components: a denoising network, a style-aware lip expert, and a style predictor. The diffusion-based denoising network is able to consistently synthesize high-quality audio-driven face motions across diverse expressions. To enhance the expressiveness and accuracy of lip motions, we introduce a style-aware lip expert that can guide lip-sync while being mindful of the speaking styles. To eliminate the need for expression reference video or text, an extra diffusion-based style predictor is utilized to predict the target expression directly from the audio. By this means, DreamTalk can harness powerful diffusion models to generate expressive faces effectively and reduce the reliance on expensive style references. Experimental results demonstrate that DreamTalk is capable of generating photo-realistic talking faces with diverse speaking styles and achieving accurate lip motions, surpassing existing state-of-the-art counterparts.
Feedback RoI Features Improve Aerial Object Detection
Nov 28, 2023



Neuroscience studies have shown that the human visual system utilizes high-level feedback information to guide lower-level perception, enabling adaptation to signals of different characteristics. In light of this, we propose Feedback multi-Level feature Extractor (Flex) to incorporate a similar mechanism for object detection. Flex refines feature selection based on image-wise and instance-level feedback information in response to image quality variation and classification uncertainty. Experimental results show that Flex offers consistent improvement to a range of existing SOTA methods on the challenging aerial object detection datasets including DOTA-v1.0, DOTA-v1.5, and HRSC2016. Although the design originates in aerial image detection, further experiments on MS COCO also reveal our module's efficacy in general detection models. Quantitative and qualitative analyses indicate that the improvements are closely related to image qualities, which match our motivation.