 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Latent Diffusion Models via Disentangled Representation Alignment
Jan 09, 2026Latent Diffusion Models (LDMs) generate high-quality images by operating in a compressed latent space, typically obtained through image tokenizers such as Variational Autoencoders (VAEs). In pursuit of a generation-friendly VAE, recent studies have explored leveraging Vision Foundation Models (VFMs) as representation alignment targets for VAEs, mirroring the approach commonly adopted for LDMs. Although this yields certain performance gains, using the same alignment target for both VAEs and LDMs overlooks their fundamentally different representational requirements. We advocate that while LDMs benefit from latents retaining high-level semantic concepts, VAEs should excel in semantic disentanglement, enabling encoding of attribute-level information in a structured way. To address this, we propose the Semantic disentangled VAE (Send-VAE), explicitly optimized for disentangled representation learning through aligning its latent space with the semantic hierarchy of pre-trained VFMs. Our approach employs a non-linear mapper network to transform VAE latents, aligning them with VFMs to bridge the gap between attribute-level disentanglement and high-level semantics, facilitating effective guidance for VAE learning. We evaluate semantic disentanglement via linear probing on attribute prediction tasks, showing strong correlation with improved generation performance. Finally, using Send-VAE, we train flow-based transformers SiTs; experiments show Send-VAE significantly speeds up training and achieves a state-of-the-art FID of 1.21 and 1.75 with and without classifier-free guidance on ImageNet 256x256.
Mod-Adapter: Tuning-Free and Versatile Multi-concept Personalization via Modulation Adapter
May 24, 2025Personalized text-to-image generation aims to synthesize images of user-provided concepts in diverse contexts. Despite recent progress in multi-concept personalization, most are limited to object concepts and struggle to customize abstract concepts (e.g., pose, lighting). Some methods have begun exploring multi-concept personalization supporting abstract concepts, but they require test-time fine-tuning for each new concept, which is time-consuming and prone to overfitting on limited training images. In this work, we propose a novel tuning-free method for multi-concept personalization that can effectively customize both object and abstract concepts without test-time fine-tuning. Our method builds upon the modulation mechanism in pretrained Diffusion Transformers (DiTs) model, leveraging the localized and semantically meaningful properties of the modulation space. Specifically, we propose a novel module, Mod-Adapter, to predict concept-specific modulation direction for the modulation process of concept-related text tokens. It incorporates vision-language cross-attention for extracting concept visual features, and Mixture-of-Experts (MoE) layers that adaptively map the concept features into the modulation space. Furthermore, to mitigate the training difficulty caused by the large gap between the concept image space and the modulation space, we introduce a VLM-guided pretraining strategy that leverages the strong image understanding capabilities of vision-language models to provide semantic supervision signals. For a comprehensive comparison, we extend a standard benchmark by incorporating abstract concepts. Our method achieves state-of-the-art performance in multi-concept personalization, supported by quantitative, qualitative, and human evaluations.
Beyond Overfitting: Doubly Adaptive Dropout for Generalizable AU Detection
Mar 12, 2025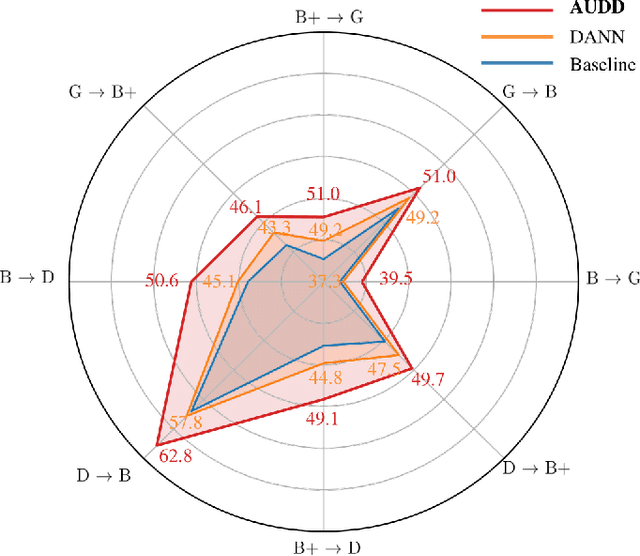
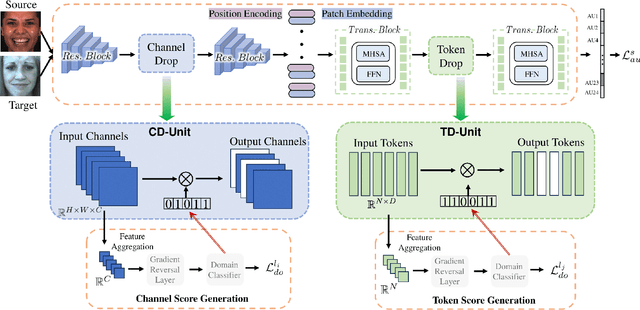
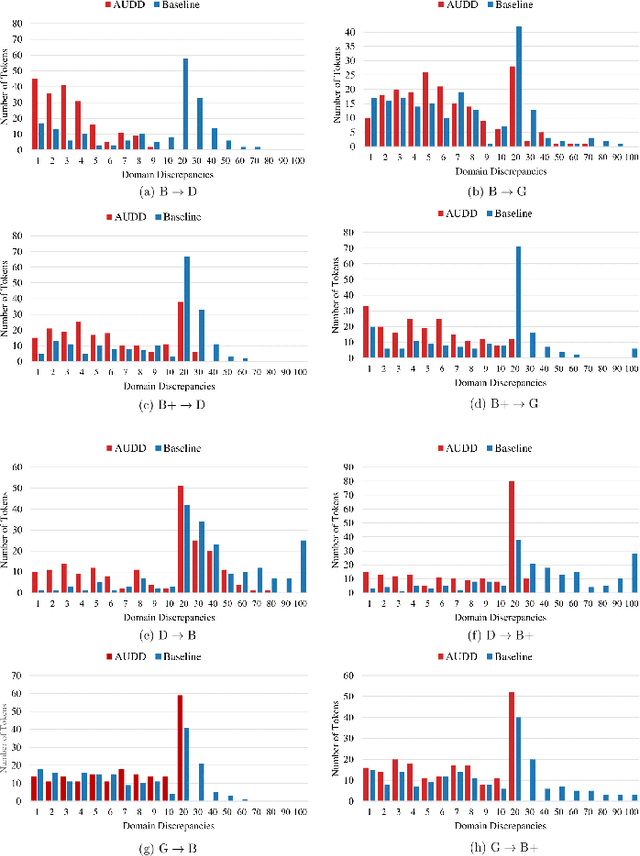
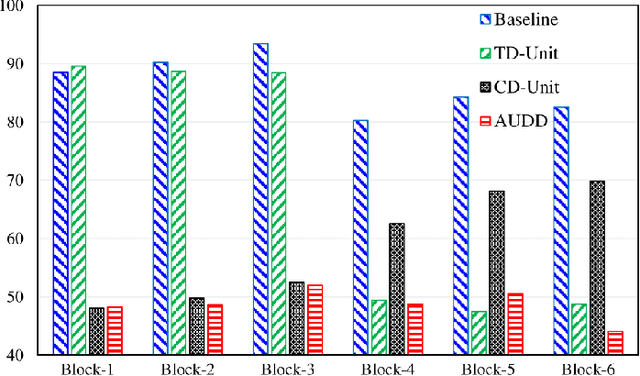
Facial Action Units (AUs) are essential for conveying psychological states and emotional expressions. While automatic AU detection systems leveraging deep learning have progressed, they often overfit to specific datasets and individual features, limiting their cross-domain applicability. To overcome these limitations, we propose a doubly adaptive dropout approach for cross-domain AU detection, which enhances the robustness of convolutional feature maps and spatial tokens against domain shifts. This approach includes a Channel Drop Unit (CD-Unit) and a Token Drop Unit (TD-Unit), which work together to reduce domain-specific noise at both the channel and token levels. The CD-Unit preserves domain-agnostic local patterns in feature maps, while the TD-Unit helps the model identify AU relationships generalizable across domains. An auxiliary domain classifier, integrated at each layer, guides the selective omission of domain-sensitive features. To prevent excessive feature dropout, a progressive training strategy is used, allowing for selective exclusion of sensitive features at any model layer. Our method consistently outperforms existing techniques in cross-domain AU detection, as demonstrated by extensive experimental evaluations. Visualizations of attention maps also highlight clear and meaningful patterns related to both individual and combined AUs, further validating the approach's effectiveness.
* Accetped by IEEE Transactions on Affective Computing 2025. A novel method for cross-domain facial action unit detection
Multi-modal Situated Reasoning in 3D Scenes
Sep 04, 2024



Situation awareness is essential for understanding and reasoning about 3D scenes in embodied AI agents. However, existing datasets and benchmarks for situated understanding are limited in data modality, diversity, scale, and task scope. To address these limitations, we propose Multi-modal Situated Question Answering (MSQA), a large-scale multi-modal situated reasoning dataset, scalably collected leveraging 3D scene graphs and vision-language models (VLMs) across a diverse range of real-world 3D scenes. MSQA includes 251K situated question-answering pairs across 9 distinct question categories, covering complex scenarios within 3D scenes. We introduce a novel interleaved multi-modal input setting in our benchmark to provide text, image, and point cloud for situation and question description, resolving ambiguity in previous single-modality convention (e.g., text). Additionally, we devise the Multi-modal Situated Next-step Navigation (MSNN) benchmark to evaluate models' situated reasoning for navigation. Comprehensive evaluations on MSQA and MSNN highlight the limitations of existing vision-language models and underscore the importance of handling multi-modal interleaved inputs and situation modeling. Experiments on data scaling and cross-domain transfer further demonstrate the efficacy of leveraging MSQA as a pre-training dataset for developing more powerful situated reasoning models.
F-HOI: Toward Fine-grained Semantic-Aligned 3D Human-Object Interactions
Jul 17, 2024



Existing 3D human object interaction (HOI) datasets and models simply align global descriptions with the long HOI sequence, while lacking a detailed understanding of intermediate states and the transitions between states. In this paper, we argue that fine-grained semantic alignment, which utilizes state-level descriptions, offers a promising paradigm for learning semantically rich HOI representations. To achieve this, we introduce Semantic-HOI, a new dataset comprising over 20K paired HOI states with fine-grained descriptions for each HOI state and the body movements that happen between two consecutive states. Leveraging the proposed dataset, we design three state-level HOI tasks to accomplish fine-grained semantic alignment within the HOI sequence. Additionally, we propose a unified model called F-HOI, designed to leverage multimodal instructions and empower the Multi-modal Large Language Model to efficiently handle diverse HOI tasks. F-HOI offers multiple advantages: (1) It employs a unified task formulation that supports the use of versatile multimodal inputs. (2) It maintains consistency in HOI across 2D, 3D, and linguistic spaces. (3) It utilizes fine-grained textual supervision for direct optimization, avoiding intricate modeling of HOI states. Extensive experiments reveal that F-HOI effectively aligns HOI states with fine-grained semantic descriptions, adeptly tackling understanding, reasoning, generation, and reconstruction tasks.
Unifying 3D Vision-Language Understanding via Promptable Queries
May 19, 2024



A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning. This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view images) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training. Tested across ten diverse 3D-VL datasets, PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state-of-the-art on ScanNet200 by 1.8% (AP), ScanRefer by 5.4% (acc@0.5), Multi3DRefer by 11.7% (F1@0.5), and Scan2Cap by 13.4% (CIDEr@0.5). Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input.
GPT as Psychologist? Preliminary Evaluations for GPT-4V on Visual Affective Computing
Mar 09, 2024



Multimodal language models (MLMs) are designed to process and integrate information from multiple sources, such as text, speech, images, and videos. Despite its success in language understanding, it is critical to evaluate the performance of downstream tasks for better human-centric applications. This paper assesses the application of MLMs with 5 crucial abilities for affective computing, spanning from visual affective tasks and reasoning tasks. The results show that GPT4 has high accuracy in facial action unit recognition and micro-expression detection while its general facial expression recognition performance is not accurate. We also highlight the challenges of achieving fine-grained micro-expression recognition and the potential for further study and demonstrate the versatility and potential of GPT4 for handling advanced tasks in emotion recognition and related fields by integrating with task-related agents for more complex tasks, such as heart rate estimation through signal processing. In conclusion, this paper provides valuable insights into the potential applications and challenges of MLMs in human-centric computing. The interesting samples are available at \url{https://github.com/LuPaoPao/GPT4Affectivity}.
SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding
Jan 17, 20243D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges: (i) the inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships; (ii) the scarcity of paired 3D vision-language data to support grounded learning; and (iii) the absence of a unified learning framework to distill knowledge from grounded 3D data. In this work, we aim to address these three major challenges in 3D vision-language by examining the potential of systematically upscaling 3D vision-language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach. We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in the challenging 3D vision-language tasks. Project website: https://scene-verse.github.io .
Multi-scale Promoted Self-adjusting Correlation Learning for Facial Action Unit Detection
Aug 15, 2023Facial Action Unit (AU) detection is a crucial task in affective computing and social robotics as it helps to identify emotions expressed through facial expressions. Anatomically, there are innumerable correlations between AUs, which contain rich information and are vital for AU detection. Previous methods used fixed AU correlations based on expert experience or statistical rules on specific benchmarks, but it is challenging to comprehensively reflect complex correlations between AUs via hand-crafted settings. There are alternative methods that employ a fully connected graph to learn these dependencies exhaustively. However, these approaches can result in a computational explosion and high dependency with a large dataset. To address these challenges, this paper proposes a novel self-adjusting AU-correlation learning (SACL) method with less computation for AU detection. This method adaptively learns and updates AU correlation graphs by efficiently leveraging the characteristics of different levels of AU motion and emotion representation information extracted in different stages of the network. Moreover, this paper explores the role of multi-scale learning in correlation information extraction, and design a simple yet effective multi-scale feature learning (MSFL) method to promote better performance in AU detection. By integrating AU correlation information with multi-scale features, the proposed method obtains a more robust feature representation for the final AU detection. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on widely used AU detection benchmark datasets, with only 28.7\% and 12.0\% of the parameters and FLOPs of the best method, respectively. The code for this method is available at \url{https://github.com/linuxsino/Self-adjusting-AU}.
Neuron Structure Modeling for Generalizable Remote Physiological Measurement
Mar 10, 2023Remote photoplethysmography (rPPG) technology has drawn increasing attention in recent years. It can extract Blood Volume Pulse (BVP) from facial videos, making many applications like health monitoring and emotional analysis more accessible. However, as the BVP signal is easily affected by environmental changes, existing methods struggle to generalize well for unseen domains. In this paper, we systematically address the domain shift problem in the rPPG measurement task. We show that most domain generalization methods do not work well in this problem, as domain labels are ambiguous in complicated environmental changes. In light of this, we propose a domain-label-free approach called NEuron STructure modeling (NEST). NEST improves the generalization capacity by maximizing the coverage of feature space during training, which reduces the chance for under-optimized feature activation during inference. Besides, NEST can also enrich and enhance domain invariant features across multi-domain. We create and benchmark a large-scale domain generalization protocol for the rPPG measurement task. Extensive experiments show that our approach outperforms the state-of-the-art methods on both cross-dataset and intra-dataset settings.