 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting Unlabeled Internet-level Data for 3D Scene Understanding
Apr 02, 2026Annotated 3D scene data is scarce and expensive to acquire, while abundant unlabeled videos are readily available on the internet. In this paper, we demonstrate that carefully designed data engines can leverage web-curated, unlabeled videos to automatically generate training data, to facilitate end-to-end models in 3D scene understanding alongside human-annotated datasets. We identify and analyze bottlenecks in automated data generation, revealing critical factors that determine the efficiency and effectiveness of learning from unlabeled data. To validate our approach across different perception granularities, we evaluate on three tasks spanning low-level perception, i.e., 3D object detection and instance segmentation, to high-evel reasoning, i.e., 3D spatial Visual Question Answering (VQA) and Vision-Lanugage Navigation (VLN). Models trained on our generated data demonstrate strong zero-shot performance and show further improvement after finetuning. This demonstrates the viability of leveraging readily available web data as a path toward more capable scene understanding systems.
MetaScenes: Towards Automated Replica Creation for Real-world 3D Scans
May 05, 2025Embodied AI (EAI) research requires high-quality, diverse 3D scenes to effectively support skill acquisition, sim-to-real transfer, and generalization. Achieving these quality standards, however, necessitates the precise replication of real-world object diversity. Existing datasets demonstrate that this process heavily relies on artist-driven designs, which demand substantial human effort and present significant scalability challenges. To scalably produce realistic and interactive 3D scenes, we first present MetaScenes, a large-scale, simulatable 3D scene dataset constructed from real-world scans, which includes 15366 objects spanning 831 fine-grained categories. Then, we introduce Scan2Sim, a robust multi-modal alignment model, which enables the automated, high-quality replacement of assets, thereby eliminating the reliance on artist-driven designs for scaling 3D scenes. We further propose two benchmarks to evaluate MetaScenes: a detailed scene synthesis task focused on small item layouts for robotic manipulation and a domain transfer task in vision-and-language navigation (VLN) to validate cross-domain transfer. Results confirm MetaScene's potential to enhance EAI by supporting more generalizable agent learning and sim-to-real applications, introducing new possibilities for EAI research. Project website: https://meta-scenes.github.io/.
SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding
Jan 17, 20243D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges: (i) the inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships; (ii) the scarcity of paired 3D vision-language data to support grounded learning; and (iii) the absence of a unified learning framework to distill knowledge from grounded 3D data. In this work, we aim to address these three major challenges in 3D vision-language by examining the potential of systematically upscaling 3D vision-language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach. We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in the challenging 3D vision-language tasks. Project website: https://scene-verse.github.io .
What I See Is What You See: Joint Attention Learning for First and Third Person Video Co-analysis
Apr 16, 2019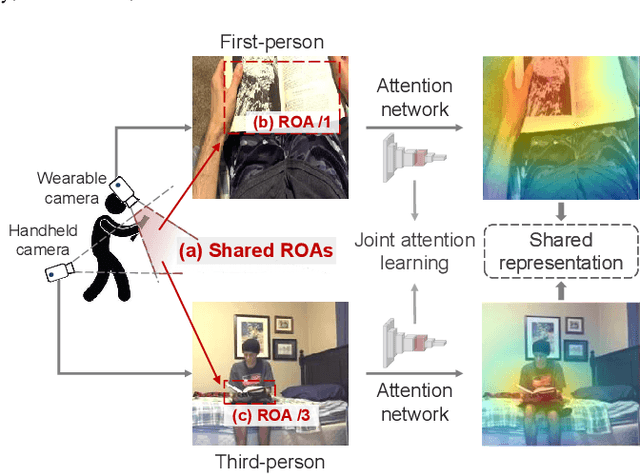
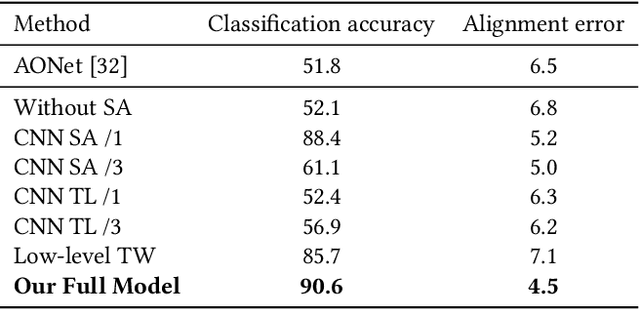

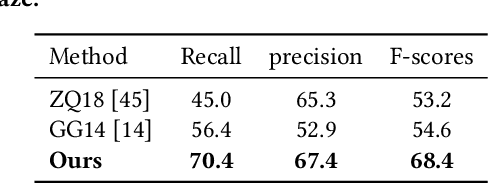
In recent years, more and more videos are captured from the first-person viewpoint by wearable cameras. Such first-person video provides additional information besides the traditional third-person video, and thus has a wide range of applications. However, techniques for analyzing the first-person video can be fundamentally different from those for the third-person video, and it is even more difficult to explore the shared information from both viewpoints. In this paper, we propose a novel method for first- and third-person video co-analysis. At the core of our method is the notion of "joint attention", indicating the learnable representation that corresponds to the shared attention regions in different viewpoints and thus links the two viewpoints. To this end, we develop a multi-branch deep network with a triplet loss to extract the joint attention from the first- and third-person videos via self-supervised learning. We evaluate our method on the public dataset with cross-viewpoint video matching tasks. Our method outperforms the state-of-the-art both qualitatively and quantitatively. We also demonstrate how the learned joint attention can benefit various applications through a set of additional experiments.