 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREE-Edit: Using Editing-aware Injection in Rectified Flow Models for Zero-shot Image-Driven Video Editing
Mar 01, 2026Image-driven video editing aims to propagate edit contents from the modified first frame to the rest frames. The existing methods usually invert the source video to noise using a pre-trained image-to-video (I2V) model and then guide the sampling process using the edited first frame. Generally, a popular choice for maintaining motion and layout from the source video is intervening in the denoising process by injecting attention during reconstruction. However, such injection often leads to unsatisfactory results, where excessive injection leads to conflicting semantics from the source video while insufficient injection brings limited source representation. Recognizing this, we propose an Editing-awaRE (REE) injection method to modulate injection intensity of each token. Specifically, we first compute the pixel difference between the source and edited first frame to form a corresponding editing mask. Next, we track the editing area throughout the entire video by using optical flow to warp the first-frame mask. Then, editing-aware feature injection intensity for each token is generated accordingly, where injection is not conducted on editing areas. Building upon REE injection, we further propose a zero-shot image-driven video editing framework with recent-emerging rectified-Flow models, dubbed FREE-Edit. Without fine-tuning or training, our FREE-Edit demonstrates effectiveness in various image-driven video editing scenarios, showing its capability to produce higher-quality outputs compared with existing techniques. Project page: https://free-edit.github.io/page/.
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Jan 30, 2026Reconstructing detailed 3D human meshes from a single in-the-wild image remains a fundamental challenge in computer vision. Existing SMPLX-based methods often suffer from slow inference, produce only coarse body poses, and exhibit misalignments or unnatural artifacts in fine-grained regions such as the face and hands. These issues make current approaches difficult to apply to downstream tasks. To address these challenges, we propose PEAR-a fast and robust framework for pixel-aligned expressive human mesh recovery. PEAR explicitly tackles three major limitations of existing methods: slow inference, inaccurate localization of fine-grained human pose details, and insufficient facial expression capture. Specifically, to enable real-time SMPLX parameter inference, we depart from prior designs that rely on high resolution inputs or multi-branch architectures. Instead, we adopt a clean and unified ViT-based model capable of recovering coarse 3D human geometry. To compensate for the loss of fine-grained details caused by this simplified architecture, we introduce pixel-level supervision to optimize the geometry, significantly improving the reconstruction accuracy of fine-grained human details. To make this approach practical, we further propose a modular data annotation strategy that enriches the training data and enhances the robustness of the model. Overall, PEAR is a preprocessing-free framework that can simultaneously infer EHM-s (SMPLX and scaled-FLAME) parameters at over 100 FPS. Extensive experiments on multiple benchmark datasets demonstrate that our method achieves substantial improvements in pose estimation accuracy compared to previous SMPLX-based approaches. Project page: https://wujh2001.github.io/PEAR
LLM4Fluid: Large Language Models as Generalizable Neural Solvers for Fluid Dynamics
Jan 29, 2026Deep learning has emerged as a promising paradigm for spatio-temporal modeling of fluid dynamics. However, existing approaches often suffer from limited generalization to unseen flow conditions and typically require retraining when applied to new scenarios. In this paper, we present LLM4Fluid, a spatio-temporal prediction framework that leverages Large Language Models (LLMs) as generalizable neural solvers for fluid dynamics. The framework first compresses high-dimensional flow fields into a compact latent space via reduced-order modeling enhanced with a physics-informed disentanglement mechanism, effectively mitigating spatial feature entanglement while preserving essential flow structures. A pretrained LLM then serves as a temporal processor, autoregressively predicting the dynamics of physical sequences with time series prompts. To bridge the modality gap between prompts and physical sequences, which can otherwise degrade prediction accuracy, we propose a dedicated modality alignment strategy that resolves representational mismatch and stabilizes long-term prediction. Extensive experiments across diverse flow scenarios demonstrate that LLM4Fluid functions as a robust and generalizable neural solver without retraining, achieving state-of-the-art accuracy while exhibiting powerful zero-shot and in-context learning capabilities. Code and datasets are publicly available at https://github.com/qisongxiao/LLM4Fluid.
MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted Enhancement
Jan 05, 2026Current audio-driven 3D head generation methods mainly focus on single-speaker scenarios, lacking natural, bidirectional listen-and-speak interaction. Achieving seamless conversational behavior, where speaking and listening states transition fluidly remains a key challenge. Existing 3D conversational avatar approaches rely on error-prone pseudo-3D labels that fail to capture fine-grained facial dynamics. To address these limitations, we introduce a novel two-stage framework MANGO, which leveraging pure image-level supervision by alternately training to mitigate the noise introduced by pseudo-3D labels, thereby achieving better alignment with real-world conversational behaviors. Specifically, in the first stage, a diffusion-based transformer with a dual-audio interaction module models natural 3D motion from multi-speaker audio. In the second stage, we use a fast 3D Gaussian Renderer to generate high-fidelity images and provide 2D-level photometric supervision for the 3D motions through alternate training. Additionally, we introduce MANGO-Dialog, a high-quality dataset with over 50 hours of aligned 2D-3D conversational data across 500+ identities. Extensive experiments demonstrate that our method achieves exceptional accuracy and realism in modeling two-person 3D dialogue motion, significantly advancing the fidelity and controllability of audio-driven talking heads.
LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models
Jan 04, 2026We present the LEMAS-Dataset, which, to our knowledge, is currently the largest open-source multilingual speech corpus with word-level timestamps. Covering over 150,000 hours across 10 major languages, LEMAS-Dataset is constructed via a efficient data processing pipeline that ensures high-quality data and annotations. To validate the effectiveness of LEMAS-Dataset across diverse generative paradigms, we train two benchmark models with distinct architectures and task specializations on this dataset. LEMAS-TTS, built upon a non-autoregressive flow-matching framework, leverages the dataset's massive scale and linguistic diversity to achieve robust zero-shot multilingual synthesis. Our proposed accent-adversarial training and CTC loss mitigate cross-lingual accent issues, enhancing synthesis stability. Complementarily, LEMAS-Edit employs an autoregressive decoder-only architecture that formulates speech editing as a masked token infilling task. By exploiting precise word-level alignments to construct training masks and adopting adaptive decoding strategies, it achieves seamless, smooth-boundary speech editing with natural transitions. Experimental results demonstrate that models trained on LEMAS-Dataset deliver high-quality synthesis and editing performance, confirming the dataset's quality. We envision that this richly timestamp-annotated, fine-grained multilingual corpus will drive future advances in prompt-based speech generation systems.
MelCap: A Unified Single-Codebook Neural Codec for High-Fidelity Audio Compression
Oct 02, 2025Neural audio codecs have recently emerged as powerful tools for high-quality and low-bitrate audio compression, leveraging deep generative models to learn latent representations of audio signals. However, existing approaches either rely on a single quantizer that only processes speech domain, or on multiple quantizers that are not well suited for downstream tasks. To address this issue, we propose MelCap, a unified "one-codebook-for-all" neural codec that effectively handles speech, music, and general sound. By decomposing audio reconstruction into two stages, our method preserves more acoustic details than previous single-codebook approaches, while achieving performance comparable to mainstream multi-codebook methods. In the first stage, audio is transformed into mel-spectrograms, which are compressed and quantized into compact single tokens using a 2D tokenizer. A perceptual loss is further applied to mitigate the over-smoothing artifacts observed in spectrogram reconstruction. In the second stage, a Vocoder recovers waveforms from the mel discrete tokens in a single forward pass, enabling real-time decoding. Both objective and subjective evaluations demonstrate that MelCap achieves quality on comparable to state-of-the-art multi-codebook codecs, while retaining the computational simplicity of a single-codebook design, thereby providing an effective representation for downstream tasks.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025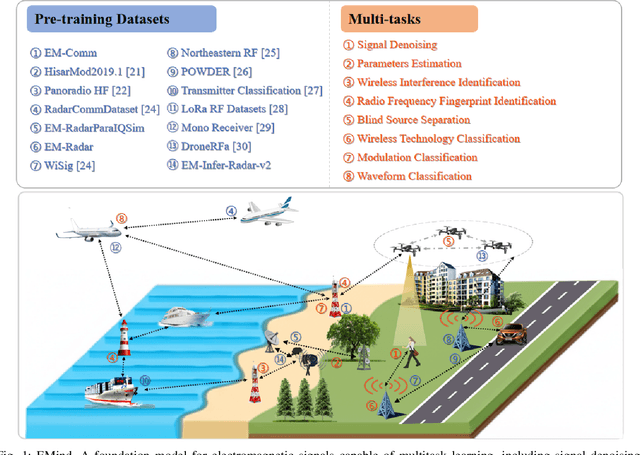
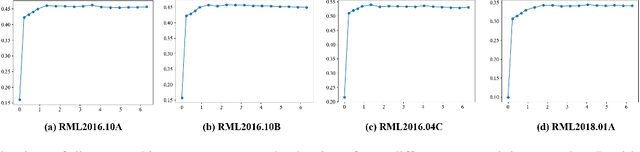
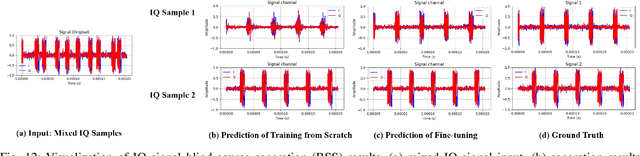
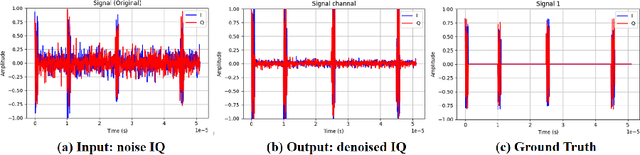
Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
Bidding-Aware Retrieval for Multi-Stage Consistency in Online Advertising
Aug 07, 2025Online advertising systems typically use a cascaded architecture to manage massive requests and candidate volumes, where the ranking stages allocate traffic based on eCPM (predicted CTR $\times$ Bid). With the increasing popularity of auto-bidding strategies, the inconsistency between the computationally sensitive retrieval stage and the ranking stages becomes more pronounced, as the former cannot access precise, real-time bids for the vast ad corpus. This discrepancy leads to sub-optimal platform revenue and advertiser outcomes. To tackle this problem, we propose Bidding-Aware Retrieval (BAR), a model-based retrieval framework that addresses multi-stage inconsistency by incorporating ad bid value into the retrieval scoring function. The core innovation is Bidding-Aware Modeling, incorporating bid signals through monotonicity-constrained learning and multi-task distillation to ensure economically coherent representations, while Asynchronous Near-Line Inference enables real-time updates to the embedding for market responsiveness. Furthermore, the Task-Attentive Refinement module selectively enhances feature interactions to disentangle user interest and commercial value signals. Extensive offline experiments and full-scale deployment across Alibaba's display advertising platform validated BAR's efficacy: 4.32% platform revenue increase with 22.2% impression lift for positively-operated advertisements.
RIS-MAE: A Self-Supervised Modulation Classification Method Based on Raw IQ Signals and Masked Autoencoder
Aug 01, 2025Automatic modulation classification (AMC) is a basic technology in intelligent wireless communication systems. It is important for tasks such as spectrum monitoring, cognitive radio, and secure communications. In recent years, deep learning methods have made great progress in AMC. However, mainstream methods still face two key problems. First, they often use time-frequency images instead of raw signals. This causes loss of key modulation features and reduces adaptability to different communication conditions. Second, most methods rely on supervised learning. This needs a large amount of labeled data, which is hard to get in real-world environments. To solve these problems, we propose a self-supervised learning framework called RIS-MAE. RIS-MAE uses masked autoencoders to learn signal features from unlabeled data. It takes raw IQ sequences as input. By applying random masking and reconstruction, it captures important time-domain features such as amplitude, phase, etc. This helps the model learn useful and transferable representations. RIS-MAE is tested on four datasets. The results show that it performs better than existing methods in few-shot and cross-domain tasks. Notably, it achieves high classification accuracy on previously unseen datasets with only a small number of fine-tuning samples, confirming its generalization ability and potential for real-world deployment.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.