 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitAvatar: One-shot Head Avatar with Autoregressive Gaussian Splitting
May 25, 20263D Gaussian Splatting (3DGS) provides an efficient method for high-quality scene reconstruction using anisotropic Gaussians. Recently, 3DGS-based methods have significantly improved the rendering quality of human avatars while enabling real-time performance. However, existing methods suffer from a magnitude mismatch in the number of Gaussians generated by image-based and 3DMM-based approaches. This discrepancy results in reconstructed expressions that lack fine-grained detail. In this paper, we introduce a novel method for reconstructing an animatable head avatar from a single image. We propose a Graph splitting network to progressively generate Gaussians from coarse to fine using an autoregressive architecture. To address the graph inconsistency caused by split Gaussians, we employ a mesh topology extension method to align the GNN's connectivity with the increased Gaussian count. Furthermore, we introduce a novel density control method that includes a gating mechanism that generates soft masks for Gaussians, preventing over-densification after the splitting operation. This allows for dynamic control over Gaussian density across different facial regions. For smooth and rapid training, we employ a delayed filtering strategy to avoid re-computing the graph topology during training. Experimental results demonstrate that our autoregressive structure effectively improves expression representation ability by progressively splitting Gaussians. This process, enabled by the GNN-guided splitting, synthesizes more precise facial details and achieves higher reconstruction quality.
AtomicMotion: Learning Human Motion From Different Human Parts
May 21, 2026Accurately reconstructing full-body poses from sparse head and hand trajectories is a foundational challenge for immersive AR/VR telepresence. Current methods often struggle with error accumulation and unnatural joint coordination, primarily because they treat the human body as a monolithic entity, thereby failing to capture the fine-grained ``atomic intents'' embedded in subtle signal variations and overlooking the inherent structural topology. To bridge this gap, we present AtomicMotion, a framework designed to decouple and re-integrate body dynamics through three core innovations. First, we introduce a logical body partitioning scheme that decomposes the skeleton into five distinct clusters based on functional intent; this ensures that each partition preserves internal joint synergies while isolating local motion primitives. Second, to robustly map sparse inputs to high-dimensional poses, we employ a masked full-body pre-conditioning strategy during training, forcing the model to internalize global skeletal topology and latent kinematic constraints. Finally, addressing the limitations of vanilla spatial attention, which often ignores fixed physiological connectivity, we propose Kinematic Attention. By embedding the classical kinematic tree structure into the attention mechanism, we ensure biological plausibility in the synthesized motions. Extensive evaluations on the AMASS dataset demonstrate that AtomicMotion significantly outperforms existing baselines, yielding higher reconstruction fidelity and superior biomechanical realism.
Instruct2See: Learning to Remove Any Obstructions Across Distributions
May 23, 2025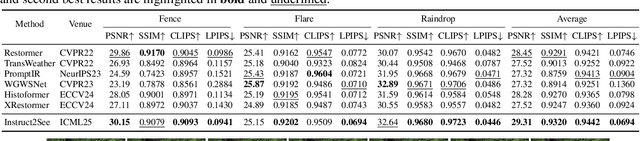
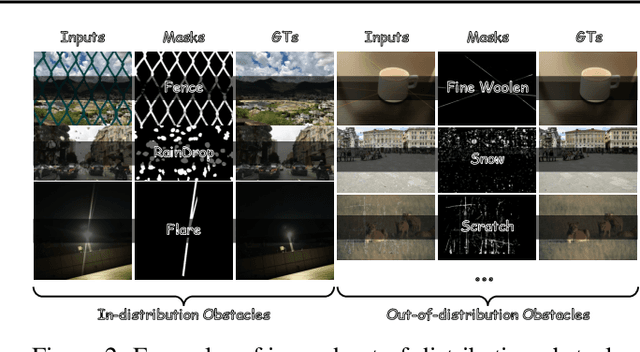
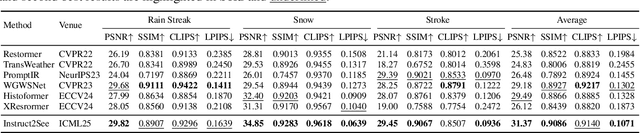
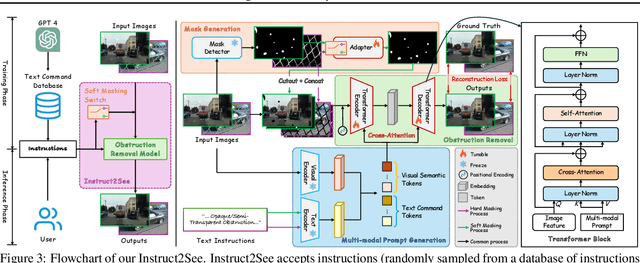
Images are often obstructed by various obstacles due to capture limitations, hindering the observation of objects of interest. Most existing methods address occlusions from specific elements like fences or raindrops, but are constrained by the wide range of real-world obstructions, making comprehensive data collection impractical. To overcome these challenges, we propose Instruct2See, a novel zero-shot framework capable of handling both seen and unseen obstacles. The core idea of our approach is to unify obstruction removal by treating it as a soft-hard mask restoration problem, where any obstruction can be represented using multi-modal prompts, such as visual semantics and textual instructions, processed through a cross-attention unit to enhance contextual understanding and improve mode control. Additionally, a tunable mask adapter allows for dynamic soft masking, enabling real-time adjustment of inaccurate masks. Extensive experiments on both in-distribution and out-of-distribution obstacles show that Instruct2See consistently achieves strong performance and generalization in obstruction removal, regardless of whether the obstacles were present during the training phase. Code and dataset are available at https://jhscut.github.io/Instruct2See.
Identity-Preserving Video Dubbing Using Motion Warping
Jan 08, 2025



Video dubbing aims to synthesize realistic, lip-synced videos from a reference video and a driving audio signal. Although existing methods can accurately generate mouth shapes driven by audio, they often fail to preserve identity-specific features, largely because they do not effectively capture the nuanced interplay between audio cues and the visual attributes of reference identity . As a result, the generated outputs frequently lack fidelity in reproducing the unique textural and structural details of the reference identity. To address these limitations, we propose IPTalker, a novel and robust framework for video dubbing that achieves seamless alignment between driving audio and reference identity while ensuring both lip-sync accuracy and high-fidelity identity preservation. At the core of IPTalker is a transformer-based alignment mechanism designed to dynamically capture and model the correspondence between audio features and reference images, thereby enabling precise, identity-aware audio-visual integration. Building on this alignment, a motion warping strategy further refines the results by spatially deforming reference images to match the target audio-driven configuration. A dedicated refinement process then mitigates occlusion artifacts and enhances the preservation of fine-grained textures, such as mouth details and skin features. Extensive qualitative and quantitative evaluations demonstrate that IPTalker consistently outperforms existing approaches in terms of realism, lip synchronization, and identity retention, establishing a new state of the art for high-quality, identity-consistent video dubbing.
Accelerate Neural Subspace-Based Reduced-Order Solver of Deformable Simulation by Lipschitz Optimization
Sep 05, 2024



Reduced-order simulation is an emerging method for accelerating physical simulations with high DOFs, and recently developed neural-network-based methods with nonlinear subspaces have been proven effective in diverse applications as more concise subspaces can be detected. However, the complexity and landscape of simulation objectives within the subspace have not been optimized, which leaves room for enhancement of the convergence speed. This work focuses on this point by proposing a general method for finding optimized subspace mappings, enabling further acceleration of neural reduced-order simulations while capturing comprehensive representations of the configuration manifolds. We achieve this by optimizing the Lipschitz energy of the elasticity term in the simulation objective, and incorporating the cubature approximation into the training process to manage the high memory and time demands associated with optimizing the newly introduced energy. Our method is versatile and applicable to both supervised and unsupervised settings for optimizing the parameterizations of the configuration manifolds. We demonstrate the effectiveness of our approach through general cases in both quasi-static and dynamics simulations. Our method achieves acceleration factors of up to 6.83 while consistently preserving comparable simulation accuracy in various cases, including large twisting, bending, and rotational deformations with collision handling. This novel approach offers significant potential for accelerating physical simulations, and can be a good add-on to existing neural-network-based solutions in modeling complex deformable objects.
Consistent Depth Prediction under Various Illuminations using Dilated Cross Attention
Dec 15, 2021

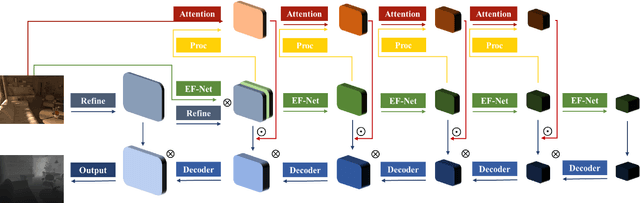
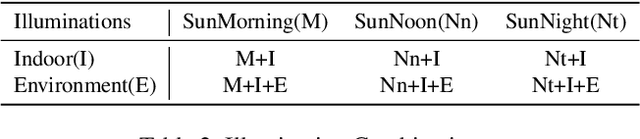
In this paper, we aim to solve the problem of consistent depth prediction in complex scenes under various illumination conditions. The existing indoor datasets based on RGB-D sensors or virtual rendering have two critical limitations - sparse depth maps (NYU Depth V2) and non-realistic illumination (SUN CG, SceneNet RGB-D). We propose to use internet 3D indoor scenes and manually tune their illuminations to render photo-realistic RGB photos and their corresponding depth and BRDF maps, obtaining a new indoor depth dataset called Vari dataset. We propose a simple convolutional block named DCA by applying depthwise separable dilated convolution on encoded features to process global information and reduce parameters. We perform cross attention on these dilated features to retain the consistency of depth prediction under different illuminations. Our method is evaluated by comparing it with current state-of-the-art methods on Vari dataset and a significant improvement is observed in our experiments. We also conduct the ablation study, finetune our model on NYU Depth V2 and also evaluate on real-world data to further validate the effectiveness of our DCA block. The code, pre-trained weights and Vari dataset are open-sourced.
Multi-Scale Progressive Fusion Learning for Depth Map Super-Resolution
Nov 24, 2020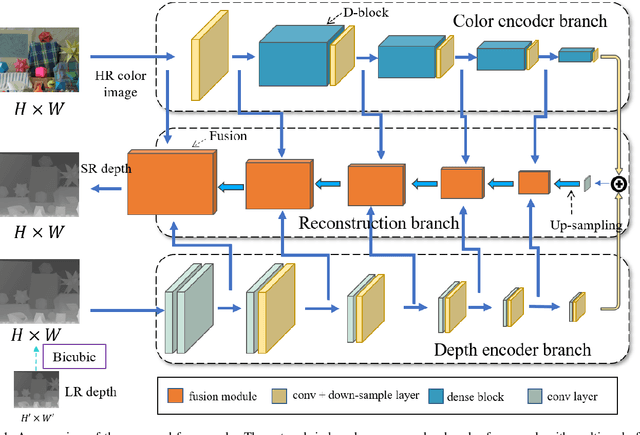
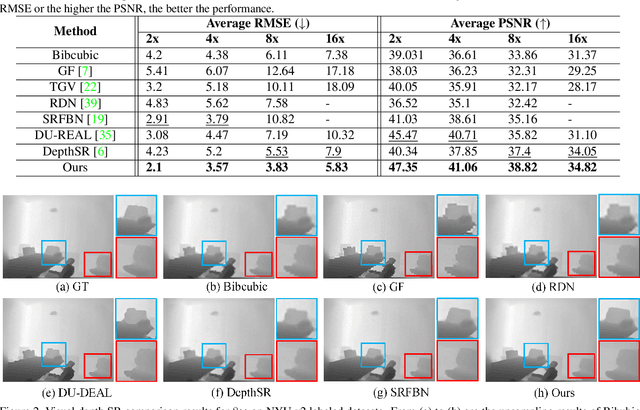


Limited by the cost and technology, the resolution of depth map collected by depth camera is often lower than that of its associated RGB camera. Although there have been many researches on RGB image super-resolution (SR), a major problem with depth map super-resolution is that there will be obvious jagged edges and excessive loss of details. To tackle these difficulties, in this work, we propose a multi-scale progressive fusion network for depth map SR, which possess an asymptotic structure to integrate hierarchical features in different domains. Given a low-resolution (LR) depth map and its associated high-resolution (HR) color image, We utilize two different branches to achieve multi-scale feature learning. Next, we propose a step-wise fusion strategy to restore the HR depth map. Finally, a multi-dimensional loss is introduced to constrain clear boundaries and details. Extensive experiments show that our proposed method produces improved results against state-of-the-art methods both qualitatively and quantitatively.
Fast Generation of High Fidelity RGB-D Images by Deep-Learning with Adaptive Convolution
Feb 12, 2020
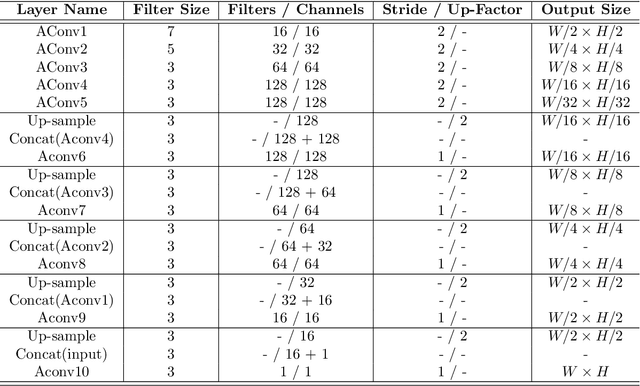
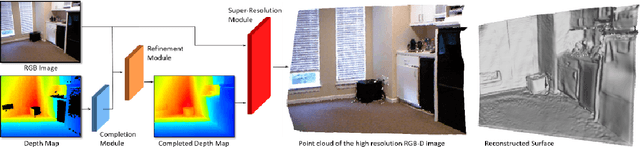
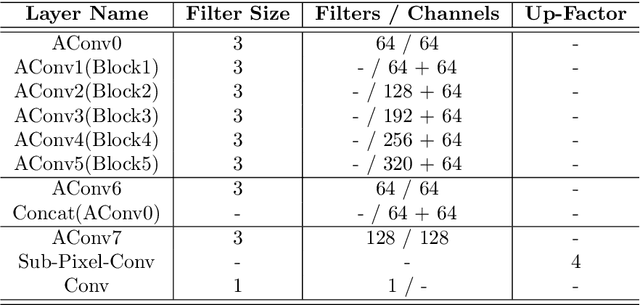
Using the raw data from consumer-level RGB-D cameras as input, we propose a deep-learning based approach to efficiently generate RGB-D images with completed information in high resolution. To process the input images in low resolution with missing regions, new operators for adaptive convolution are introduced in our deep-learning network that consists of three cascaded modules -- the completion module, the refinement module and the super-resolution module. The completion module is based on an architecture of encoder-decoder, where the features of input raw RGB-D will be automatically extracted by the encoding layers of a deep neural-network. The decoding layers are applied to reconstruct the completed depth map, which is followed by a refinement module to sharpen the boundary of different regions. For the super-resolution module, we generate RGB-D images in high resolution by multiple layers for feature extraction and a layer for up-sampling. Benefited from the adaptive convolution operators newly proposed in this paper, our results outperform the existing deep-learning based approaches for RGB-D image complete and super-resolution. As an end-to-end approach, high fidelity RGB-D images can be generated efficiently at the rate of around 21 frames per second.