 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Preserving Video Dubbing Using Motion Warping
Jan 08, 2025



Video dubbing aims to synthesize realistic, lip-synced videos from a reference video and a driving audio signal. Although existing methods can accurately generate mouth shapes driven by audio, they often fail to preserve identity-specific features, largely because they do not effectively capture the nuanced interplay between audio cues and the visual attributes of reference identity . As a result, the generated outputs frequently lack fidelity in reproducing the unique textural and structural details of the reference identity. To address these limitations, we propose IPTalker, a novel and robust framework for video dubbing that achieves seamless alignment between driving audio and reference identity while ensuring both lip-sync accuracy and high-fidelity identity preservation. At the core of IPTalker is a transformer-based alignment mechanism designed to dynamically capture and model the correspondence between audio features and reference images, thereby enabling precise, identity-aware audio-visual integration. Building on this alignment, a motion warping strategy further refines the results by spatially deforming reference images to match the target audio-driven configuration. A dedicated refinement process then mitigates occlusion artifacts and enhances the preservation of fine-grained textures, such as mouth details and skin features. Extensive qualitative and quantitative evaluations demonstrate that IPTalker consistently outperforms existing approaches in terms of realism, lip synchronization, and identity retention, establishing a new state of the art for high-quality, identity-consistent video dubbing.
Free-viewpoint Human Animation with Pose-correlated Reference Selection
Dec 23, 2024



Diffusion-based human animation aims to animate a human character based on a source human image as well as driving signals such as a sequence of poses. Leveraging the generative capacity of diffusion model, existing approaches are able to generate high-fidelity poses, but struggle with significant viewpoint changes, especially in zoom-in/zoom-out scenarios where camera-character distance varies. This limits the applications such as cinematic shot type plan or camera control. We propose a pose-correlated reference selection diffusion network, supporting substantial viewpoint variations in human animation. Our key idea is to enable the network to utilize multiple reference images as input, since significant viewpoint changes often lead to missing appearance details on the human body. To eliminate the computational cost, we first introduce a novel pose correlation module to compute similarities between non-aligned target and source poses, and then propose an adaptive reference selection strategy, utilizing the attention map to identify key regions for animation generation. To train our model, we curated a large dataset from public TED talks featuring varied shots of the same character, helping the model learn synthesis for different perspectives. Our experimental results show that with the same number of reference images, our model performs favorably compared to the current SOTA methods under large viewpoint change. We further show that the adaptive reference selection is able to choose the most relevant reference regions to generate humans under free viewpoints.
Switch Trajectory Transformer with Distributional Value Approximation for Multi-Task Reinforcement Learning
Mar 14, 2022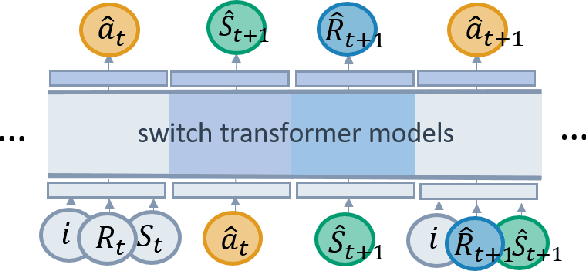
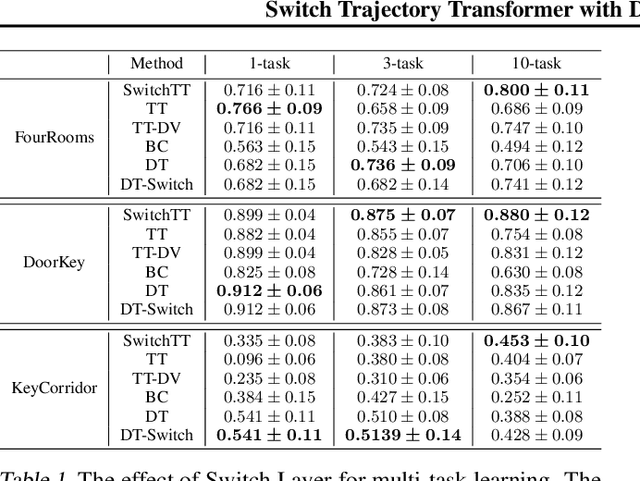

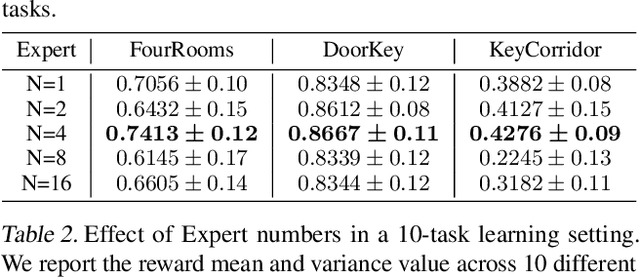
We propose SwitchTT, a multi-task extension to Trajectory Transformer but enhanced with two striking features: (i) exploiting a sparsely activated model to reduce computation cost in multi-task offline model learning and (ii) adopting a distributional trajectory value estimator that improves policy performance, especially in sparse reward settings. These two enhancements make SwitchTT suitable for solving multi-task offline reinforcement learning problems, where model capacity is critical for absorbing the vast quantities of knowledge available in the multi-task dataset. More specifically, SwitchTT exploits switch transformer model architecture for multi-task policy learning, allowing us to improve model capacity without proportional computation cost. Also, SwitchTT approximates the distribution rather than the expectation of trajectory value, mitigating the effects of the Monte-Carlo Value estimator suffering from poor sample complexity, especially in the sparse-reward setting. We evaluate our method using the suite of ten sparse-reward tasks from the gym-mini-grid environment.We show an improvement of 10% over Trajectory Transformer across 10-task learning and obtain up to 90% increase in offline model training speed. Our results also demonstrate the advantage of the switch transformer model for absorbing expert knowledge and the importance of value distribution in evaluating the trajectory.