 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenLight: Precise Lighting Control in Images using Attribute Tokens
Apr 16, 2026This paper presents a method for image relighting that enables precise and continuous control over multiple illumination attributes in a photograph. We formulate relighting as a conditional image generation task and introduce attribute tokens to encode distinct lighting factors such as intensity, color, ambient illumination, diffuse level, and 3D light positions. The model is trained on a large-scale synthetic dataset with ground-truth lighting annotations, supplemented by a small set of real captures to enhance realism and generalization. We validate our approach across a variety of relighting tasks, including controlling in-scene lighting fixtures and editing environment illumination using virtual light sources, on synthetic and real images. Our method achieves state-of-the-art quantitative and qualitative performance compared to prior work. Remarkably, without explicit inverse rendering supervision, the model exhibits an inherent understanding of how light interacts with scene geometry, occlusion, and materials, yielding convincing lighting effects even in traditionally challenging scenarios such as placing lights within objects or relighting transparent materials plausibly. Project page: vrroom.github.io/tokenlight/
LightMover: Generative Light Movement with Color and Intensity Controls
Mar 28, 2026We present LightMover, a framework for controllable light manipulation in single images that leverages video diffusion priors to produce physically plausible illumination changes without re-rendering the scene. We formulate light editing as a sequence-to-sequence prediction problem in visual token space: given an image and light-control tokens, the model adjusts light position, color, and intensity together with resulting reflections, shadows, and falloff from a single view. This unified treatment of spatial (movement) and appearance (color, intensity) controls improves both manipulation and illumination understanding. We further introduce an adaptive token-pruning mechanism that preserves spatially informative tokens while compactly encoding non-spatial attributes, reducing control sequence length by 41% while maintaining editing fidelity. To train our framework, we construct a scalable rendering pipeline that generates large numbers of image pairs across varied light positions, colors, and intensities while keeping the scene content consistent with the original image. LightMover enables precise, independent control over light position, color, and intensity, and achieves high PSNR and strong semantic consistency (DINO, CLIP) across different tasks.
FaceCam: Portrait Video Camera Control via Scale-Aware Conditioning
Mar 05, 2026We introduce FaceCam, a system that generates video under customizable camera trajectories for monocular human portrait video input. Recent camera control approaches based on large video-generation models have shown promising progress but often exhibit geometric distortions and visual artifacts on portrait videos due to scale-ambiguous camera representations or 3D reconstruction errors. To overcome these limitations, we propose a face-tailored scale-aware representation for camera transformations that provides deterministic conditioning without relying on 3D priors. We train a video generation model on both multi-view studio captures and in-the-wild monocular videos, and introduce two camera-control data generation strategies: synthetic camera motion and multi-shot stitching, to exploit stationary training cameras while generalizing to dynamic, continuous camera trajectories at inference time. Experiments on Ava-256 dataset and diverse in-the-wild videos demonstrate that FaceCam achieves superior performance in camera controllability, visual quality, identity and motion preservation.
GaSLight: Gaussian Splats for Spatially-Varying Lighting in HDR
Apr 15, 2025We present GaSLight, a method that generates spatially-varying lighting from regular images. Our method proposes using HDR Gaussian Splats as light source representation, marking the first time regular images can serve as light sources in a 3D renderer. Our two-stage process first enhances the dynamic range of images plausibly and accurately by leveraging the priors embedded in diffusion models. Next, we employ Gaussian Splats to model 3D lighting, achieving spatially variant lighting. Our approach yields state-of-the-art results on HDR estimations and their applications in illuminating virtual objects and scenes. To facilitate the benchmarking of images as light sources, we introduce a novel dataset of calibrated and unsaturated HDR to evaluate images as light sources. We assess our method using a combination of this novel dataset and an existing dataset from the literature. The code to reproduce our method will be available upon acceptance.
SynthLight: Portrait Relighting with Diffusion Model by Learning to Re-render Synthetic Faces
Jan 16, 2025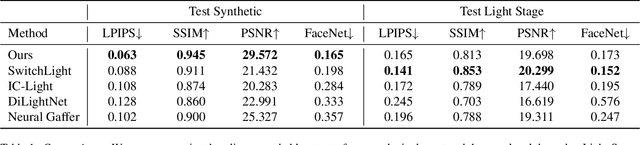

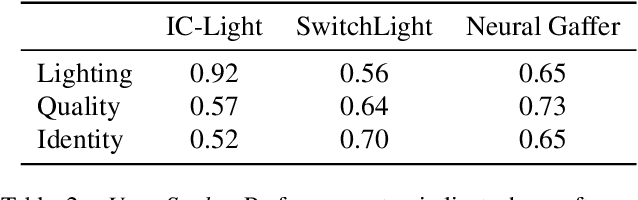
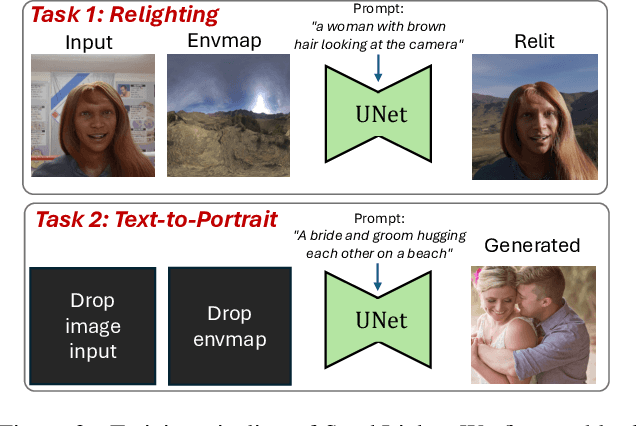
We introduce SynthLight, a diffusion model for portrait relighting. Our approach frames image relighting as a re-rendering problem, where pixels are transformed in response to changes in environmental lighting conditions. Using a physically-based rendering engine, we synthesize a dataset to simulate this lighting-conditioned transformation with 3D head assets under varying lighting. We propose two training and inference strategies to bridge the gap between the synthetic and real image domains: (1) multi-task training that takes advantage of real human portraits without lighting labels; (2) an inference time diffusion sampling procedure based on classifier-free guidance that leverages the input portrait to better preserve details. Our method generalizes to diverse real photographs and produces realistic illumination effects, including specular highlights and cast shadows, while preserving the subject's identity. Our quantitative experiments on Light Stage data demonstrate results comparable to state-of-the-art relighting methods. Our qualitative results on in-the-wild images showcase rich and unprecedented illumination effects. Project Page: \url{https://vrroom.github.io/synthlight/}
FaceLift: Single Image to 3D Head with View Generation and GS-LRM
Dec 23, 2024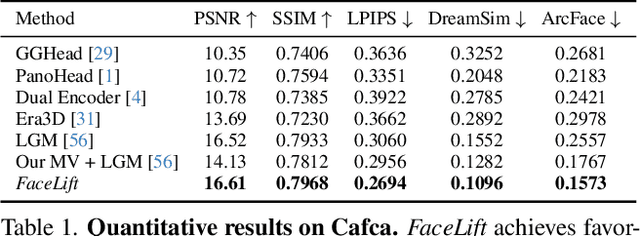

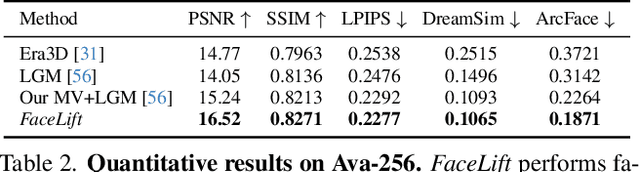
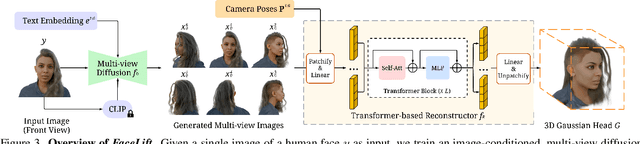
We present FaceLift, a feed-forward approach for rapid, high-quality, 360-degree head reconstruction from a single image. Our pipeline begins by employing a multi-view latent diffusion model that generates consistent side and back views of the head from a single facial input. These generated views then serve as input to a GS-LRM reconstructor, which produces a comprehensive 3D representation using Gaussian splats. To train our system, we develop a dataset of multi-view renderings using synthetic 3D human head as-sets. The diffusion-based multi-view generator is trained exclusively on synthetic head images, while the GS-LRM reconstructor undergoes initial training on Objaverse followed by fine-tuning on synthetic head data. FaceLift excels at preserving identity and maintaining view consistency across views. Despite being trained solely on synthetic data, FaceLift demonstrates remarkable generalization to real-world images. Through extensive qualitative and quantitative evaluations, we show that FaceLift outperforms state-of-the-art methods in 3D head reconstruction, highlighting its practical applicability and robust performance on real-world images. In addition to single image reconstruction, FaceLift supports video inputs for 4D novel view synthesis and seamlessly integrates with 2D reanimation techniques to enable 3D facial animation. Project page: https://weijielyu.github.io/FaceLift.
Free-viewpoint Human Animation with Pose-correlated Reference Selection
Dec 23, 2024



Diffusion-based human animation aims to animate a human character based on a source human image as well as driving signals such as a sequence of poses. Leveraging the generative capacity of diffusion model, existing approaches are able to generate high-fidelity poses, but struggle with significant viewpoint changes, especially in zoom-in/zoom-out scenarios where camera-character distance varies. This limits the applications such as cinematic shot type plan or camera control. We propose a pose-correlated reference selection diffusion network, supporting substantial viewpoint variations in human animation. Our key idea is to enable the network to utilize multiple reference images as input, since significant viewpoint changes often lead to missing appearance details on the human body. To eliminate the computational cost, we first introduce a novel pose correlation module to compute similarities between non-aligned target and source poses, and then propose an adaptive reference selection strategy, utilizing the attention map to identify key regions for animation generation. To train our model, we curated a large dataset from public TED talks featuring varied shots of the same character, helping the model learn synthesis for different perspectives. Our experimental results show that with the same number of reference images, our model performs favorably compared to the current SOTA methods under large viewpoint change. We further show that the adaptive reference selection is able to choose the most relevant reference regions to generate humans under free viewpoints.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
Generative Portrait Shadow Removal
Oct 07, 2024



We introduce a high-fidelity portrait shadow removal model that can effectively enhance the image of a portrait by predicting its appearance under disturbing shadows and highlights. Portrait shadow removal is a highly ill-posed problem where multiple plausible solutions can be found based on a single image. While existing works have solved this problem by predicting the appearance residuals that can propagate local shadow distribution, such methods are often incomplete and lead to unnatural predictions, especially for portraits with hard shadows. We overcome the limitations of existing local propagation methods by formulating the removal problem as a generation task where a diffusion model learns to globally rebuild the human appearance from scratch as a condition of an input portrait image. For robust and natural shadow removal, we propose to train the diffusion model with a compositional repurposing framework: a pre-trained text-guided image generation model is first fine-tuned to harmonize the lighting and color of the foreground with a background scene by using a background harmonization dataset; and then the model is further fine-tuned to generate a shadow-free portrait image via a shadow-paired dataset. To overcome the limitation of losing fine details in the latent diffusion model, we propose a guided-upsampling network to restore the original high-frequency details (wrinkles and dots) from the input image. To enable our compositional training framework, we construct a high-fidelity and large-scale dataset using a lightstage capturing system and synthetic graphics simulation. Our generative framework effectively removes shadows caused by both self and external occlusions while maintaining original lighting distribution and high-frequency details. Our method also demonstrates robustness to diverse subjects captured in real environments.
Learning Frame-Wise Emotion Intensity for Audio-Driven Talking-Head Generation
Sep 29, 2024



Human emotional expression is inherently dynamic, complex, and fluid, characterized by smooth transitions in intensity throughout verbal communication. However, the modeling of such intensity fluctuations has been largely overlooked by previous audio-driven talking-head generation methods, which often results in static emotional outputs. In this paper, we explore how emotion intensity fluctuates during speech, proposing a method for capturing and generating these subtle shifts for talking-head generation. Specifically, we develop a talking-head framework that is capable of generating a variety of emotions with precise control over intensity levels. This is achieved by learning a continuous emotion latent space, where emotion types are encoded within latent orientations and emotion intensity is reflected in latent norms. In addition, to capture the dynamic intensity fluctuations, we adopt an audio-to-intensity predictor by considering the speaking tone that reflects the intensity. The training signals for this predictor are obtained through our emotion-agnostic intensity pseudo-labeling method without the need of frame-wise intensity labeling. Extensive experiments and analyses validate the effectiveness of our proposed method in accurately capturing and reproducing emotion intensity fluctuations in talking-head generation, thereby significantly enhancing the expressiveness and realism of the generated outputs.