 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
Progressive Autoregressive Video Diffusion Models
Oct 10, 2024Current frontier video diffusion models have demonstrated remarkable results at generating high-quality videos. However, they can only generate short video clips, normally around 10 seconds or 240 frames, due to computation limitations during training. In this work, we show that existing models can be naturally extended to autoregressive video diffusion models without changing the architectures. Our key idea is to assign the latent frames with progressively increasing noise levels rather than a single noise level, which allows for fine-grained condition among the latents and large overlaps between the attention windows. Such progressive video denoising allows our models to autoregressively generate video frames without quality degradation or abrupt scene changes. We present state-of-the-art results on long video generation at 1 minute (1440 frames at 24 FPS). Videos from this paper are available at https://desaixie.github.io/pa-vdm/.
LRM-Zero: Training Large Reconstruction Models with Synthesized Data
Jun 13, 2024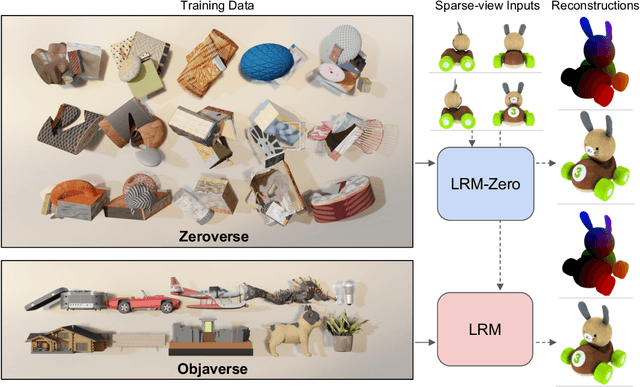
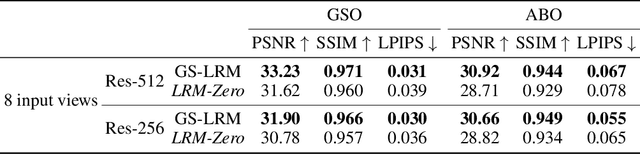
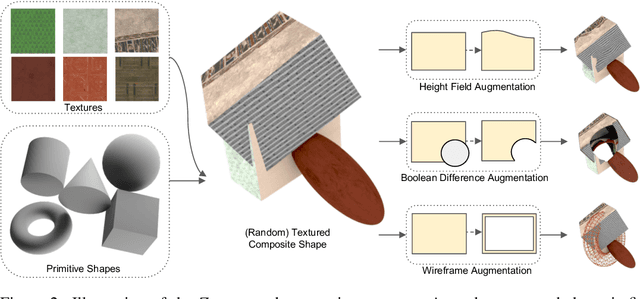
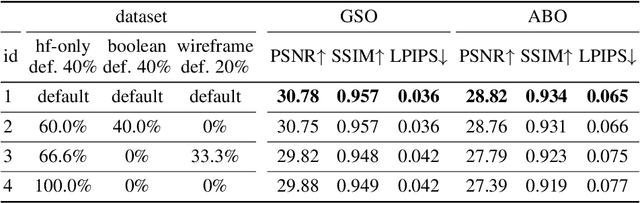
We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.
Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning
Dec 21, 2023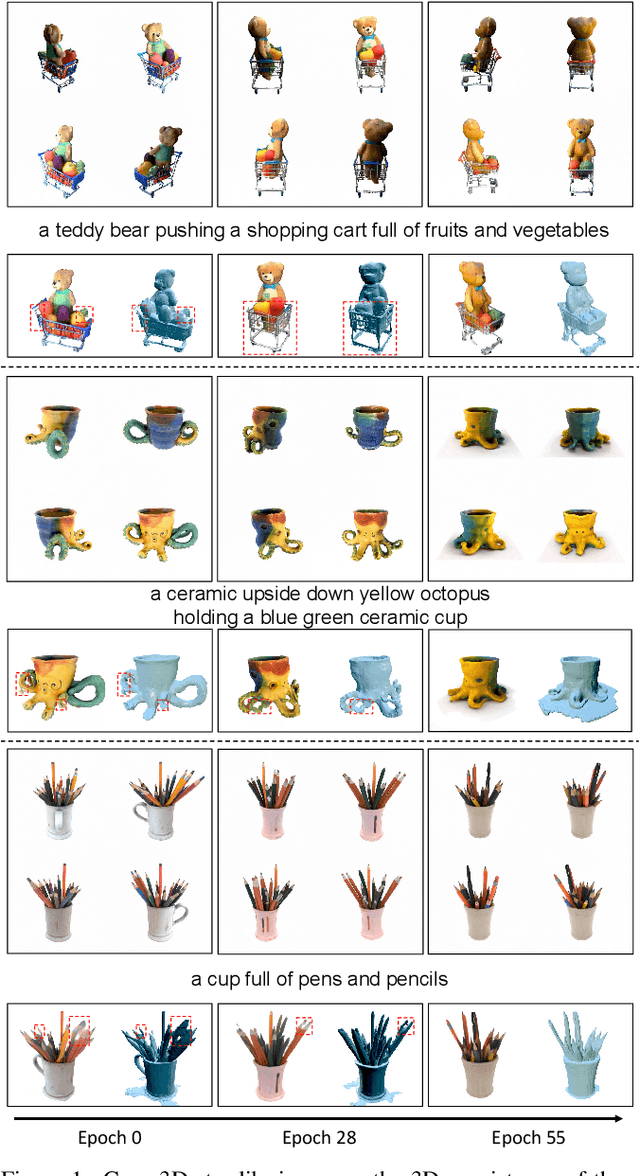
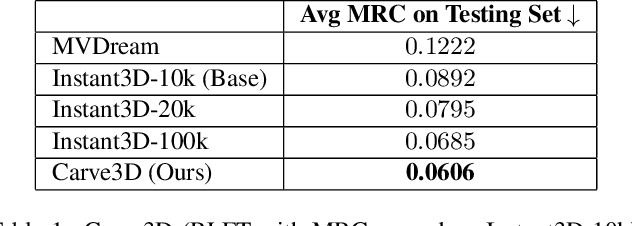
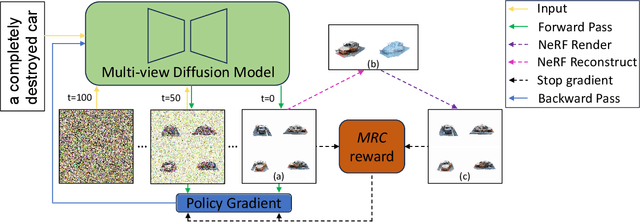

Recent advancements in the text-to-3D task leverage finetuned text-to-image diffusion models to generate multi-view images, followed by NeRF reconstruction. Yet, existing supervised finetuned (SFT) diffusion models still suffer from multi-view inconsistency and the resulting NeRF artifacts. Although training longer with SFT improves consistency, it also causes distribution shift, which reduces diversity and realistic details. We argue that the SFT of multi-view diffusion models resembles the instruction finetuning stage of the LLM alignment pipeline and can benefit from RL finetuning (RLFT) methods. Essentially, RLFT methods optimize models beyond their SFT data distribution by using their own outputs, effectively mitigating distribution shift. To this end, we introduce Carve3D, a RLFT method coupled with the Multi-view Reconstruction Consistency (MRC) metric, to improve the consistency of multi-view diffusion models. To compute MRC on a set of multi-view images, we compare them with their corresponding renderings of the reconstructed NeRF at the same viewpoints. We validate the robustness of MRC with extensive experiments conducted under controlled inconsistency levels. We enhance the base RLFT algorithm to stabilize the training process, reduce distribution shift, and identify scaling laws. Through qualitative and quantitative experiments, along with a user study, we demonstrate Carve3D's improved multi-view consistency, the resulting superior NeRF reconstruction quality, and minimal distribution shift compared to longer SFT. Project webpage: https://desaixie.github.io/carve-3d.