 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Mar 17, 2026Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
Coarse-to-Real: Generative Rendering for Populated Dynamic Scenes
Jan 29, 2026Traditional rendering pipelines rely on complex assets, accurate materials and lighting, and substantial computational resources to produce realistic imagery, yet they still face challenges in scalability and realism for populated dynamic scenes. We present C2R (Coarse-to-Real), a generative rendering framework that synthesizes real-style urban crowd videos from coarse 3D simulations. Our approach uses coarse 3D renderings to explicitly control scene layout, camera motion, and human trajectories, while a learned neural renderer generates realistic appearance, lighting, and fine-scale dynamics guided by text prompts. To overcome the lack of paired training data between coarse simulations and real videos, we adopt a two-phase mixed CG-real training strategy that learns a strong generative prior from large-scale real footage and introduces controllability through shared implicit spatio-temporal features across domains. The resulting system supports coarse-to-fine control, generalizes across diverse CG and game inputs, and produces temporally consistent, controllable, and realistic urban scene videos from minimal 3D input. We will release the model and project webpage at https://gonzalognogales.github.io/coarse2real/.
Diffusion Transformer-to-Mamba Distillation for High-Resolution Image Generation
Jun 23, 2025
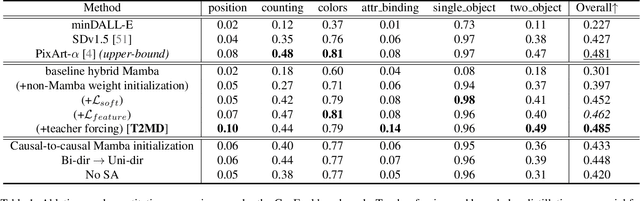
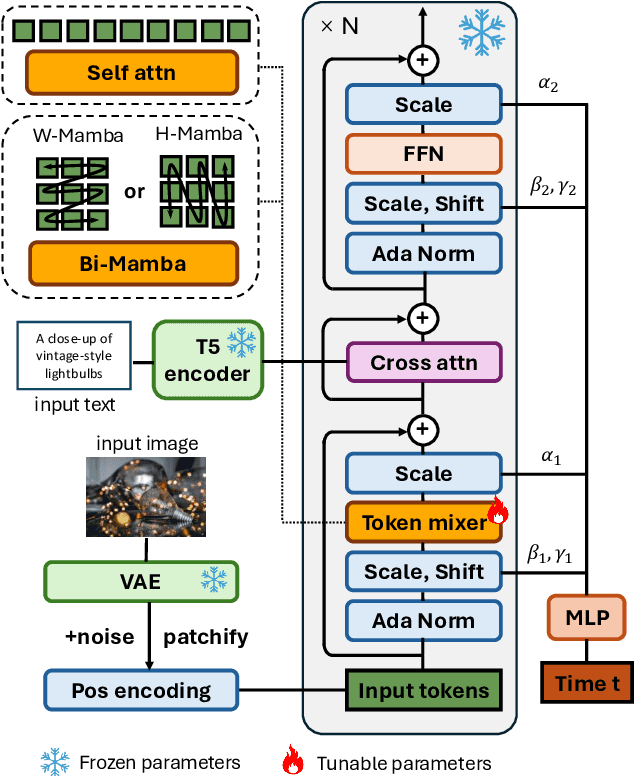
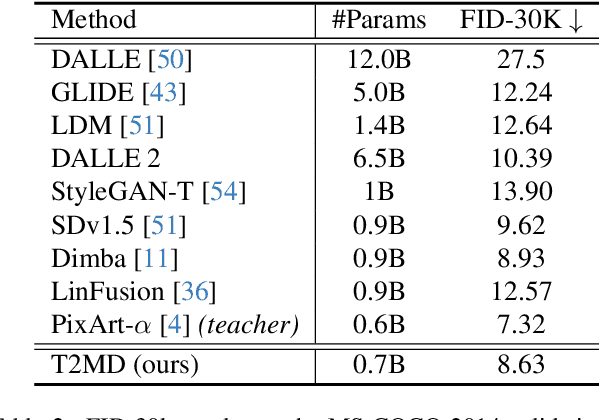
The quadratic computational complexity of self-attention in diffusion transformers (DiT) introduces substantial computational costs in high-resolution image generation. While the linear-complexity Mamba model emerges as a potential alternative, direct Mamba training remains empirically challenging. To address this issue, this paper introduces diffusion transformer-to-mamba distillation (T2MD), forming an efficient training pipeline that facilitates the transition from the self-attention-based transformer to the linear complexity state-space model Mamba. We establish a diffusion self-attention and Mamba hybrid model that simultaneously achieves efficiency and global dependencies. With the proposed layer-level teacher forcing and feature-based knowledge distillation, T2MD alleviates the training difficulty and high cost of a state space model from scratch. Starting from the distilled 512$\times$512 resolution base model, we push the generation towards 2048$\times$2048 images via lightweight adaptation and high-resolution fine-tuning. Experiments demonstrate that our training path leads to low overhead but high-quality text-to-image generation. Importantly, our results also justify the feasibility of using sequential and causal Mamba models for generating non-causal visual output, suggesting the potential for future exploration.
Test-Time Training Done Right
May 29, 2025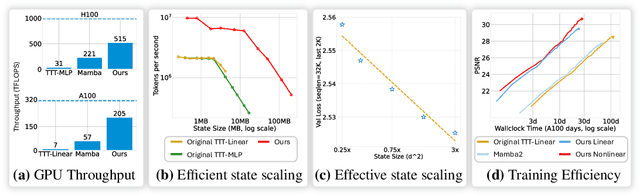

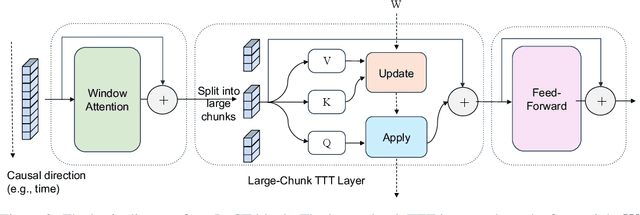
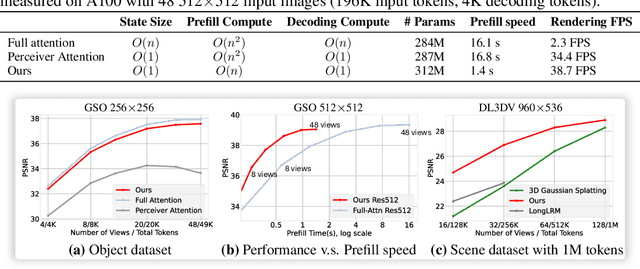
Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, language models, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Mar 19, 2025Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
REGEN: Learning Compact Video Embedding with (Re-)Generative Decoder
Mar 11, 2025
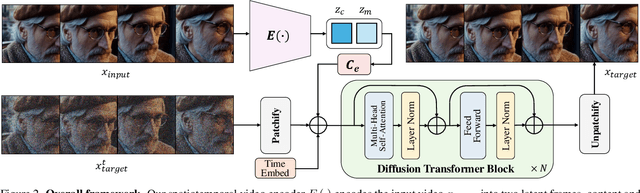

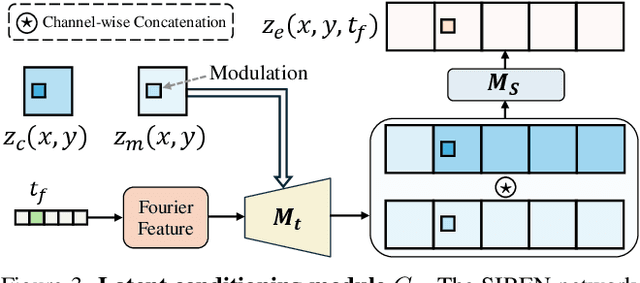
We present a novel perspective on learning video embedders for generative modeling: rather than requiring an exact reproduction of an input video, an effective embedder should focus on synthesizing visually plausible reconstructions. This relaxed criterion enables substantial improvements in compression ratios without compromising the quality of downstream generative models. Specifically, we propose replacing the conventional encoder-decoder video embedder with an encoder-generator framework that employs a diffusion transformer (DiT) to synthesize missing details from a compact latent space. Therein, we develop a dedicated latent conditioning module to condition the DiT decoder on the encoded video latent embedding. Our experiments demonstrate that our approach enables superior encoding-decoding performance compared to state-of-the-art methods, particularly as the compression ratio increases. To demonstrate the efficacy of our approach, we report results from our video embedders achieving a temporal compression ratio of up to 32x (8x higher than leading video embedders) and validate the robustness of this ultra-compact latent space for text-to-video generation, providing a significant efficiency boost in latent diffusion model training and inference.
Pushing the Boundaries of State Space Models for Image and Video Generation
Feb 03, 2025



While Transformers have become the dominant architecture for visual generation, linear attention models, such as the state-space models (SSM), are increasingly recognized for their efficiency in processing long visual sequences. However, the essential efficiency of these models comes from formulating a limited recurrent state, enforcing causality among tokens that are prone to inconsistent modeling of N-dimensional visual data, leaving questions on their capacity to generate long non-causal sequences. In this paper, we explore the boundary of SSM on image and video generation by building the largest-scale diffusion SSM-Transformer hybrid model to date (5B parameters) based on the sub-quadratic bi-directional Hydra and self-attention, and generate up to 2K images and 360p 8 seconds (16 FPS) videos. Our results demonstrate that the model can produce faithful results aligned with complex text prompts and temporal consistent videos with high dynamics, suggesting the great potential of using SSMs for visual generation tasks.
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Dec 11, 2024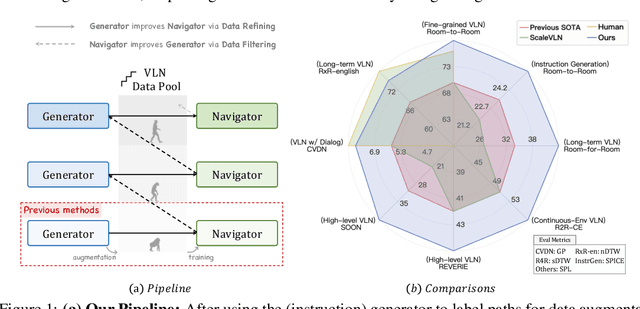
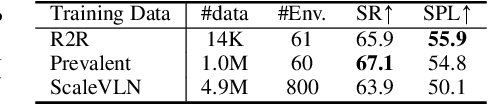
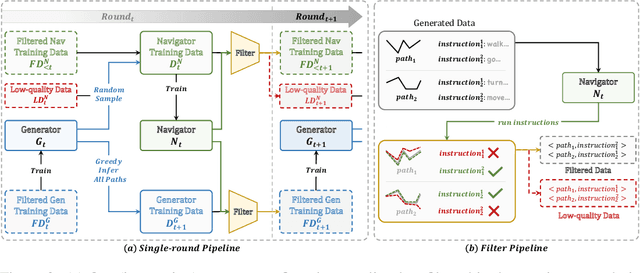
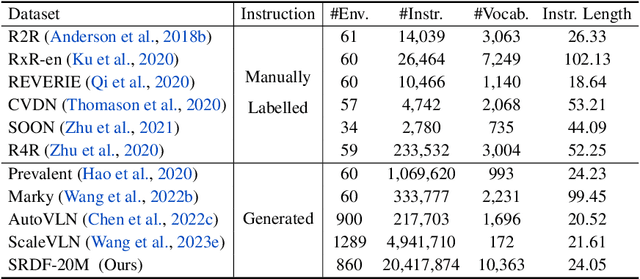
Creating high-quality data for training robust language-instructed agents is a long-lasting challenge in embodied AI. In this paper, we introduce a Self-Refining Data Flywheel (SRDF) that generates high-quality and large-scale navigational instruction-trajectory pairs by iteratively refining the data pool through the collaboration between two models, the instruction generator and the navigator, without any human-in-the-loop annotation. Specifically, SRDF starts with using a base generator to create an initial data pool for training a base navigator, followed by applying the trained navigator to filter the data pool. This leads to higher-fidelity data to train a better generator, which can, in turn, produce higher-quality data for training the next-round navigator. Such a flywheel establishes a data self-refining process, yielding a continuously improved and highly effective dataset for large-scale language-guided navigation learning. Our experiments demonstrate that after several flywheel rounds, the navigator elevates the performance boundary from 70% to 78% SPL on the classic R2R test set, surpassing human performance (76%) for the first time. Meanwhile, this process results in a superior generator, evidenced by a SPICE increase from 23.5 to 26.2, better than all previous VLN instruction generation methods. Finally, we demonstrate the scalability of our method through increasing environment and instruction diversity, and the generalization ability of our pre-trained navigator across various downstream navigation tasks, surpassing state-of-the-art methods by a large margin in all cases.
SAME: Learning Generic Language-Guided Visual Navigation with State-Adaptive Mixture of Experts
Dec 07, 2024The academic field of learning instruction-guided visual navigation can be generally categorized into high-level category-specific search and low-level language-guided navigation, depending on the granularity of language instruction, in which the former emphasizes the exploration process, while the latter concentrates on following detailed textual commands. Despite the differing focuses of these tasks, the underlying requirements of interpreting instructions, comprehending the surroundings, and inferring action decisions remain consistent. This paper consolidates diverse navigation tasks into a unified and generic framework -- we investigate the core difficulties of sharing general knowledge and exploiting task-specific capabilities in learning navigation and propose a novel State-Adaptive Mixture of Experts (SAME) model that effectively enables an agent to infer decisions based on different-granularity language and dynamic observations. Powered by SAME, we present a versatile agent capable of addressing seven navigation tasks simultaneously that outperforms or achieves highly comparable performance to task-specific agents.
Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats
Oct 16, 2024



We propose Long-LRM, a generalizable 3D Gaussian reconstruction model that is capable of reconstructing a large scene from a long sequence of input images. Specifically, our model can process 32 source images at 960x540 resolution within only 1.3 seconds on a single A100 80G GPU. Our architecture features a mixture of the recent Mamba2 blocks and the classical transformer blocks which allowed many more tokens to be processed than prior work, enhanced by efficient token merging and Gaussian pruning steps that balance between quality and efficiency. Unlike previous feed-forward models that are limited to processing 1~4 input images and can only reconstruct a small portion of a large scene, Long-LRM reconstructs the entire scene in a single feed-forward step. On large-scale scene datasets such as DL3DV-140 and Tanks and Temples, our method achieves performance comparable to optimization-based approaches while being two orders of magnitude more efficient. Project page: https://arthurhero.github.io/projects/llrm