 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGEN: Learning Compact Video Embedding with (Re-)Generative Decoder
Mar 11, 2025
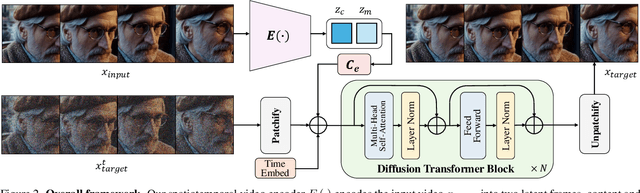

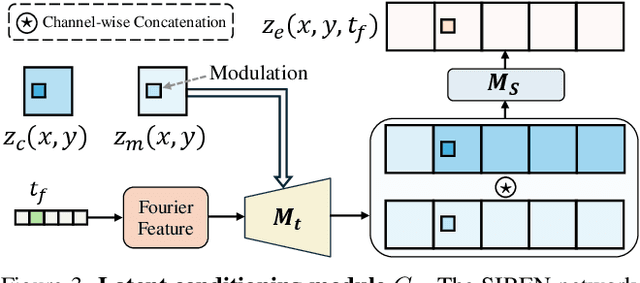
We present a novel perspective on learning video embedders for generative modeling: rather than requiring an exact reproduction of an input video, an effective embedder should focus on synthesizing visually plausible reconstructions. This relaxed criterion enables substantial improvements in compression ratios without compromising the quality of downstream generative models. Specifically, we propose replacing the conventional encoder-decoder video embedder with an encoder-generator framework that employs a diffusion transformer (DiT) to synthesize missing details from a compact latent space. Therein, we develop a dedicated latent conditioning module to condition the DiT decoder on the encoded video latent embedding. Our experiments demonstrate that our approach enables superior encoding-decoding performance compared to state-of-the-art methods, particularly as the compression ratio increases. To demonstrate the efficacy of our approach, we report results from our video embedders achieving a temporal compression ratio of up to 32x (8x higher than leading video embedders) and validate the robustness of this ultra-compact latent space for text-to-video generation, providing a significant efficiency boost in latent diffusion model training and inference.
Progressive Growing of Video Tokenizers for Highly Compressed Latent Spaces
Jan 09, 2025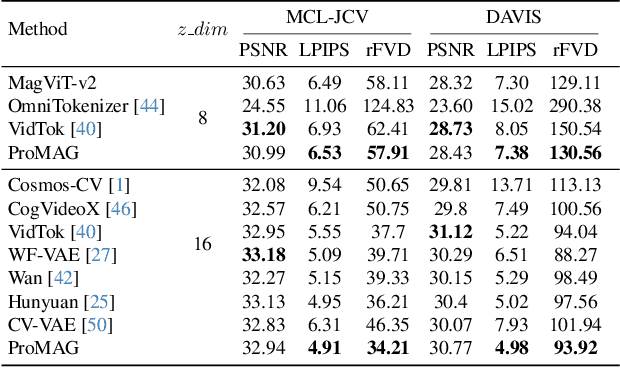

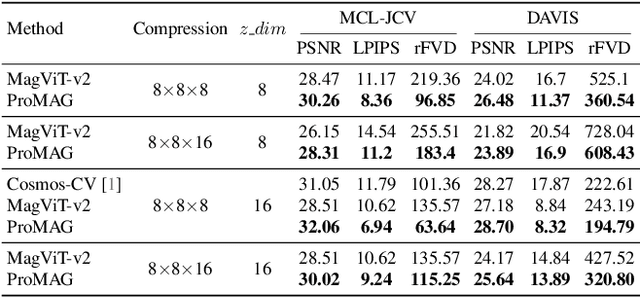

Video tokenizers are essential for latent video diffusion models, converting raw video data into spatiotemporally compressed latent spaces for efficient training. However, extending state-of-the-art video tokenizers to achieve a temporal compression ratio beyond 4x without increasing channel capacity poses significant challenges. In this work, we propose an alternative approach to enhance temporal compression. We find that the reconstruction quality of temporally subsampled videos from a low-compression encoder surpasses that of high-compression encoders applied to original videos. This indicates that high-compression models can leverage representations from lower-compression models. Building on this insight, we develop a bootstrapped high-temporal-compression model that progressively trains high-compression blocks atop well-trained lower-compression models. Our method includes a cross-level feature-mixing module to retain information from the pretrained low-compression model and guide higher-compression blocks to capture the remaining details from the full video sequence. Evaluation of video benchmarks shows that our method significantly improves reconstruction quality while increasing temporal compression compared to direct extensions of existing video tokenizers. Furthermore, the resulting compact latent space effectively trains a video diffusion model for high-quality video generation with a reduced token budget.
Video-Guided Foley Sound Generation with Multimodal Controls
Nov 26, 2024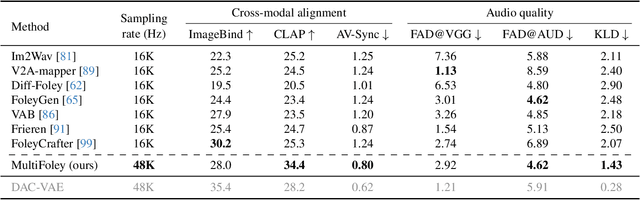
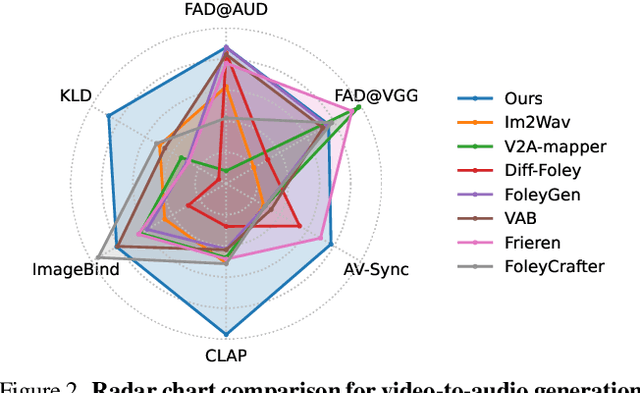
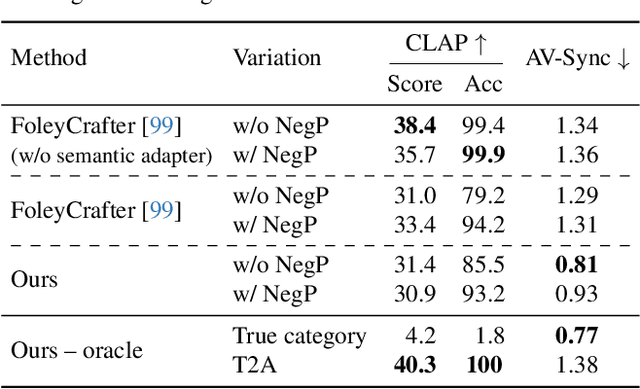
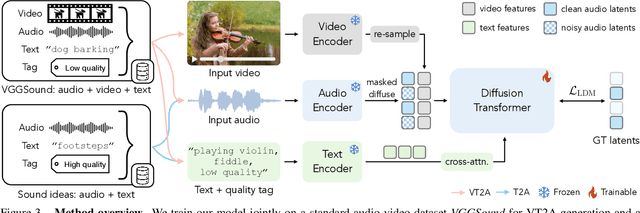
Generating sound effects for videos often requires creating artistic sound effects that diverge significantly from real-life sources and flexible control in the sound design. To address this problem, we introduce MultiFoley, a model designed for video-guided sound generation that supports multimodal conditioning through text, audio, and video. Given a silent video and a text prompt, MultiFoley allows users to create clean sounds (e.g., skateboard wheels spinning without wind noise) or more whimsical sounds (e.g., making a lion's roar sound like a cat's meow). MultiFoley also allows users to choose reference audio from sound effects (SFX) libraries or partial videos for conditioning. A key novelty of our model lies in its joint training on both internet video datasets with low-quality audio and professional SFX recordings, enabling high-quality, full-bandwidth (48kHz) audio generation. Through automated evaluations and human studies, we demonstrate that MultiFoley successfully generates synchronized high-quality sounds across varied conditional inputs and outperforms existing methods. Please see our project page for video results: https://ificl.github.io/MultiFoley/
Predicting human decisions with behavioral theories and machine learning
Apr 15, 2019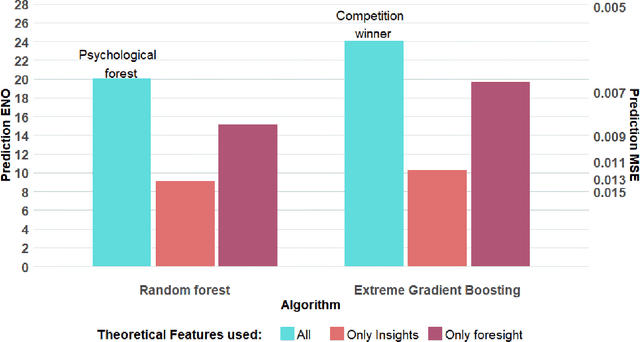
Behavioral decision theories aim to explain human behavior. Can they help predict it? An open tournament for prediction of human choices in fundamental economic decision tasks is presented. The results suggest that integration of certain behavioral theories as features in machine learning systems provides the best predictions. Surprisingly, the most useful theories for prediction build on basic properties of human and animal learning and are very different from mainstream decision theories that focus on deviations from rational choice. Moreover, we find that theoretical features should be based not only on qualitative behavioral insights (e.g. loss aversion), but also on quantitative behavioral foresights generated by functional descriptive models (e.g. Prospect Theory). Our analysis prescribes a recipe for derivation of explainable, useful predictions of human decisions.