 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
FLAM: Frame-Wise Language-Audio Modeling
May 08, 2025Recent multi-modal audio-language models (ALMs) excel at text-audio retrieval but struggle with frame-wise audio understanding. Prior works use temporal-aware labels or unsupervised training to improve frame-wise capabilities, but they still lack fine-grained labeling capability to pinpoint when an event occurs. While traditional sound event detection models can precisely localize events, they are limited to pre-defined categories, making them ineffective for real-world scenarios with out-of-distribution events. In this work, we introduce FLAM, an open-vocabulary contrastive audio-language model capable of localizing specific sound events. FLAM employs a memory-efficient and calibrated frame-wise objective with logit adjustment to address spurious correlations, such as event dependencies and label imbalances during training. To enable frame-wise supervision, we leverage a large-scale dataset with diverse audio events, LLM-generated captions and simulation. Experimental results and case studies demonstrate that FLAM significantly improves the open-vocabulary localization capability while maintaining strong performance in global retrieval and downstream tasks.
SILA: Signal-to-Language Augmentation for Enhanced Control in Text-to-Audio Generation
Dec 13, 2024The field of text-to-audio generation has seen significant advancements, and yet the ability to finely control the acoustic characteristics of generated audio remains under-explored. In this paper, we introduce a novel yet simple approach to generate sound effects with control over key acoustic parameters such as loudness, pitch, reverb, fade, brightness, noise and duration, enabling creative applications in sound design and content creation. These parameters extend beyond traditional Digital Signal Processing (DSP) techniques, incorporating learned representations that capture the subtleties of how sound characteristics can be shaped in context, enabling a richer and more nuanced control over the generated audio. Our approach is model-agnostic and is based on learning the disentanglement between audio semantics and its acoustic features. Our approach not only enhances the versatility and expressiveness of text-to-audio generation but also opens new avenues for creative audio production and sound design. Our objective and subjective evaluation results demonstrate the effectiveness of our approach in producing high-quality, customizable audio outputs that align closely with user specifications.
Sketch2Sound: Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Dec 11, 2024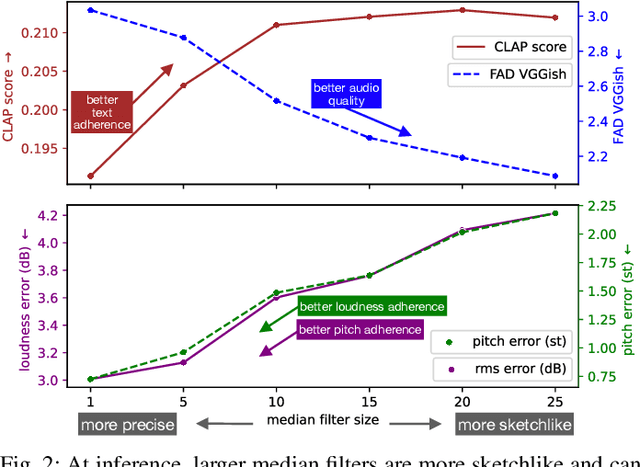
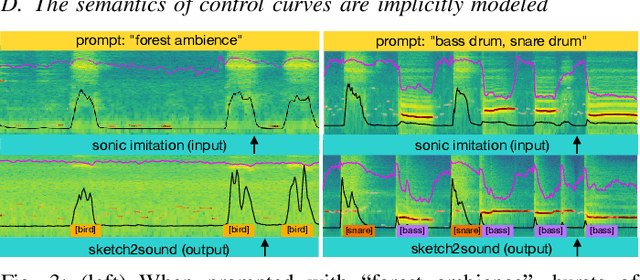
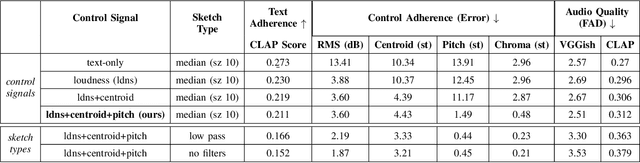
We present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e.,~a vocal imitation or a reference sound-shape). Sketch2Sound can be implemented on top of any text-to-audio latent diffusion transformer (DiT), and requires only 40k steps of fine-tuning and a single linear layer per control, making it more lightweight than existing methods like ControlNet. To synthesize from sketchlike sonic imitations, we propose applying random median filters to the control signals during training, allowing Sketch2Sound to be prompted using controls with flexible levels of temporal specificity. We show that Sketch2Sound can synthesize sounds that follow the gist of input controls from a vocal imitation while retaining the adherence to an input text prompt and audio quality compared to a text-only baseline. Sketch2Sound allows sound artists to create sounds with the semantic flexibility of text prompts and the expressivity and precision of a sonic gesture or vocal imitation. Sound examples are available at https://hugofloresgarcia.art/sketch2sound/.
Video-Guided Foley Sound Generation with Multimodal Controls
Nov 26, 2024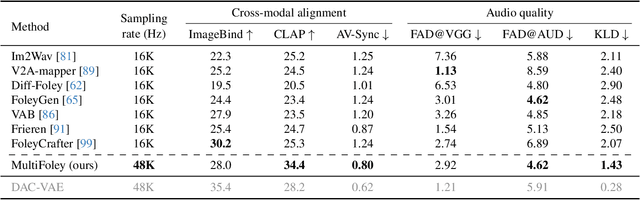
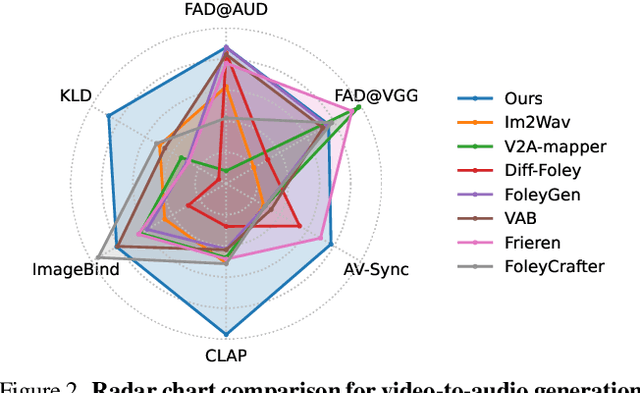
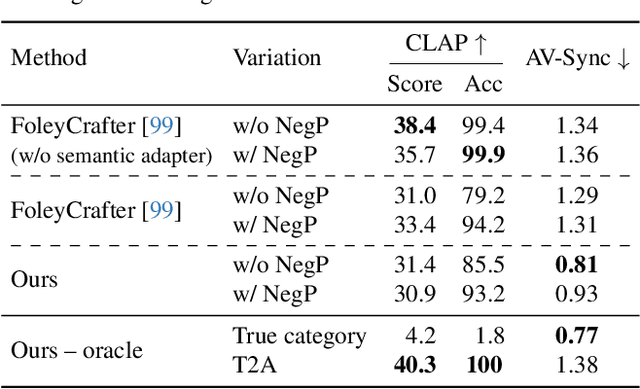
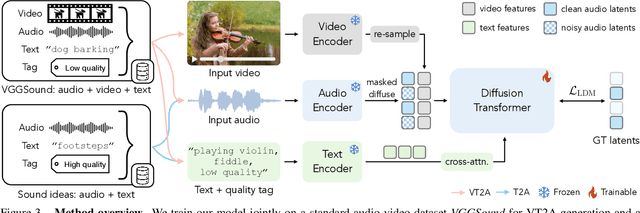
Generating sound effects for videos often requires creating artistic sound effects that diverge significantly from real-life sources and flexible control in the sound design. To address this problem, we introduce MultiFoley, a model designed for video-guided sound generation that supports multimodal conditioning through text, audio, and video. Given a silent video and a text prompt, MultiFoley allows users to create clean sounds (e.g., skateboard wheels spinning without wind noise) or more whimsical sounds (e.g., making a lion's roar sound like a cat's meow). MultiFoley also allows users to choose reference audio from sound effects (SFX) libraries or partial videos for conditioning. A key novelty of our model lies in its joint training on both internet video datasets with low-quality audio and professional SFX recordings, enabling high-quality, full-bandwidth (48kHz) audio generation. Through automated evaluations and human studies, we demonstrate that MultiFoley successfully generates synchronized high-quality sounds across varied conditional inputs and outperforms existing methods. Please see our project page for video results: https://ificl.github.io/MultiFoley/
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Augment, Drop & Swap: Improving Diversity in LLM Captions for Efficient Music-Text Representation Learning
Sep 17, 2024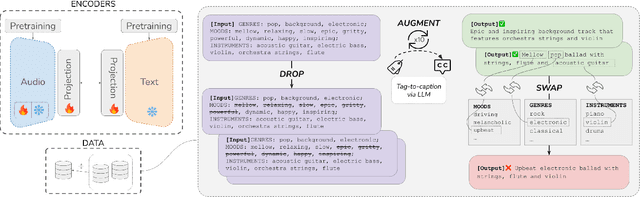
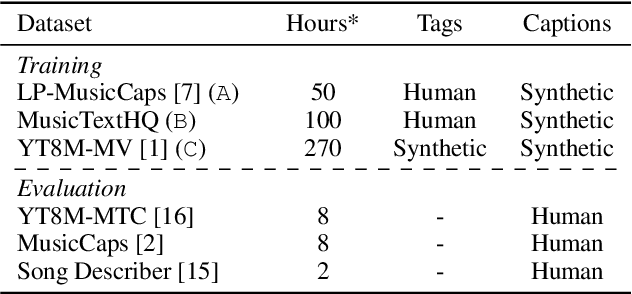
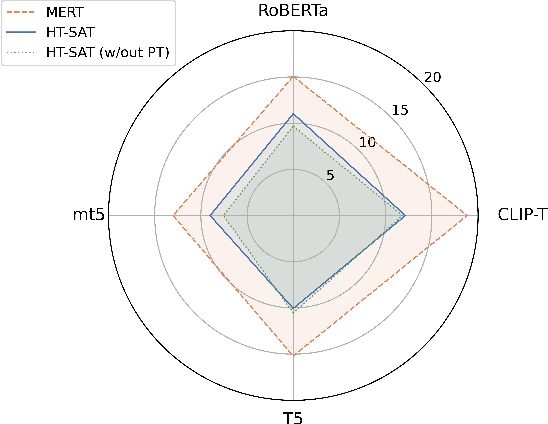

Audio-text contrastive models have become a powerful approach in music representation learning. Despite their empirical success, however, little is known about the influence of key design choices on the quality of music-text representations learnt through this framework. In this work, we expose these design choices within the constraints of limited data and computation budgets, and establish a more solid understanding of their impact grounded in empirical observations along three axes: the choice of base encoders, the level of curation in training data, and the use of text augmentation. We find that data curation is the single most important factor for music-text contrastive training in resource-constrained scenarios. Motivated by this insight, we introduce two novel techniques, Augmented View Dropout and TextSwap, which increase the diversity and descriptiveness of text inputs seen in training. Through our experiments we demonstrate that these are effective at boosting performance across different pre-training regimes, model architectures, and downstream data distributions, without incurring higher computational costs or requiring additional training data.
ReCLAP: Improving Zero Shot Audio Classification by Describing Sounds
Sep 13, 2024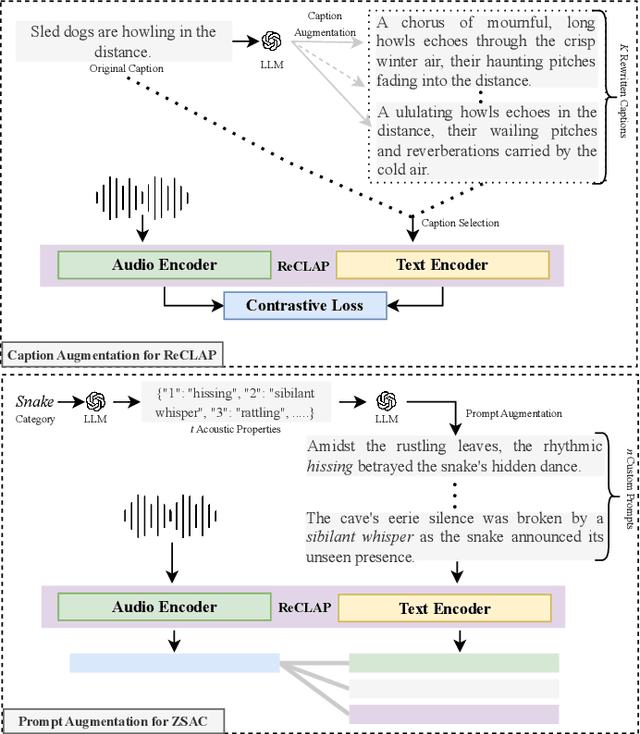

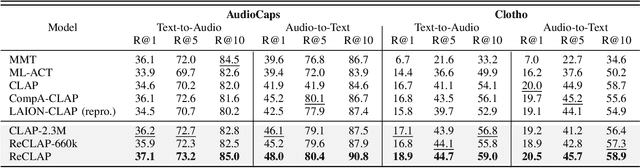
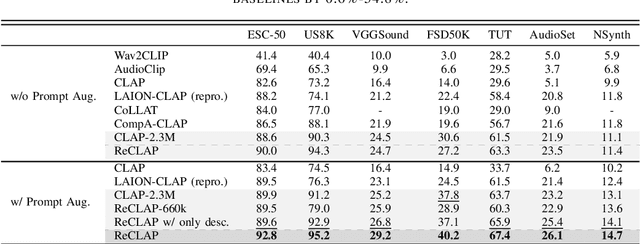
Open-vocabulary audio-language models, like CLAP, offer a promising approach for zero-shot audio classification (ZSAC) by enabling classification with any arbitrary set of categories specified with natural language prompts. In this paper, we propose a simple but effective method to improve ZSAC with CLAP. Specifically, we shift from the conventional method of using prompts with abstract category labels (e.g., Sound of an organ) to prompts that describe sounds using their inherent descriptive features in a diverse context (e.g.,The organ's deep and resonant tones filled the cathedral.). To achieve this, we first propose ReCLAP, a CLAP model trained with rewritten audio captions for improved understanding of sounds in the wild. These rewritten captions describe each sound event in the original caption using their unique discriminative characteristics. ReCLAP outperforms all baselines on both multi-modal audio-text retrieval and ZSAC. Next, to improve zero-shot audio classification with ReCLAP, we propose prompt augmentation. In contrast to the traditional method of employing hand-written template prompts, we generate custom prompts for each unique label in the dataset. These custom prompts first describe the sound event in the label and then employ them in diverse scenes. Our proposed method improves ReCLAP's performance on ZSAC by 1%-18% and outperforms all baselines by 1% - 55%.
GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
Jun 17, 2024



Perceiving and understanding non-speech sounds and non-verbal speech is essential to making decisions that help us interact with our surroundings. In this paper, we propose GAMA, a novel General-purpose Large Audio-Language Model (LALM) with Advanced Audio Understanding and Complex Reasoning Abilities. We build GAMA by integrating an LLM with multiple types of audio representations, including features from a custom Audio Q-Former, a multi-layer aggregator that aggregates features from multiple layers of an audio encoder. We fine-tune GAMA on a large-scale audio-language dataset, which augments it with audio understanding capabilities. Next, we propose CompA-R (Instruction-Tuning for Complex Audio Reasoning), a synthetically generated instruction-tuning (IT) dataset with instructions that require the model to perform complex reasoning on the input audio. We instruction-tune GAMA with CompA-R to endow it with complex reasoning abilities, where we further add a soft prompt as input with high-level semantic evidence by leveraging event tags of the input audio. Finally, we also propose CompA-R-test, a human-labeled evaluation dataset for evaluating the capabilities of LALMs on open-ended audio question-answering that requires complex reasoning. Through automated and expert human evaluations, we show that GAMA outperforms all other LALMs in literature on diverse audio understanding tasks by margins of 1%-84%. Further, GAMA IT-ed on CompA-R proves to be superior in its complex reasoning and instruction following capabilities.