 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio MultiChallenge: A Multi-Turn Evaluation of Spoken Dialogue Systems on Natural Human Interaction
Dec 16, 2025



End-to-end (E2E) spoken dialogue systems are increasingly replacing cascaded pipelines for voice-based human-AI interaction, processing raw audio directly without intermediate transcription. Existing benchmarks primarily evaluate these models on synthetic speech and single-turn tasks, leaving realistic multi-turn conversational ability underexplored. We introduce Audio MultiChallenge, an open-source benchmark to evaluate E2E spoken dialogue systems under natural multi-turn interaction patterns. Building on the text-based MultiChallenge framework, which evaluates Inference Memory, Instruction Retention, and Self Coherence, we introduce a new axis Voice Editing that tests robustness to mid-utterance speech repairs and backtracking. We further augment each axis to the audio modality, such as introducing Audio-Cue challenges for Inference Memory that require recalling ambient sounds and paralinguistic signals beyond semantic content. We curate 452 conversations from 47 speakers with 1,712 instance-specific rubrics through a hybrid audio-native agentic and human-in-the-loop pipeline that exposes model failures at scale while preserving natural disfluencies found in unscripted human speech. Our evaluation of proprietary and open-source models reveals that even frontier models struggle on our benchmark, with Gemini 3 Pro Preview (Thinking), our highest-performing model achieving a 54.65% pass rate. Error analysis shows that models fail most often on our new axes and that Self Coherence degrades with longer audio context. These failures reflect difficulty of tracking edits, audio cues, and long-range context in natural spoken dialogue. Audio MultiChallenge provides a reproducible testbed to quantify them and drive improvements in audio-native multi-turn interaction capability.
Beyond Seeing: Evaluating Multimodal LLMs on Tool-Enabled Image Perception, Transformation, and Reasoning
Oct 14, 2025Multimodal Large Language Models (MLLMs) are increasingly applied in real-world scenarios where user-provided images are often imperfect, requiring active image manipulations such as cropping, editing, or enhancement to uncover salient visual cues. Beyond static visual perception, MLLMs must also think with images: dynamically transforming visual content and integrating it with other tools to solve complex tasks. However, this shift from treating vision as passive context to a manipulable cognitive workspace remains underexplored. Most existing benchmarks still follow a think about images paradigm, where images are regarded as static inputs. To address this gap, we introduce IRIS, an Interactive Reasoning with Images and Systems that evaluates MLLMs' ability to perceive, transform, and reason across complex visual-textual tasks under the think with images paradigm. IRIS comprises 1,204 challenging, open-ended vision tasks (603 single-turn, 601 multi-turn) spanning across five diverse domains, each paired with detailed rubrics to enable systematic evaluation. Our evaluation shows that current MLLMs struggle with tasks requiring effective integration of vision and general-purpose tools. Even the strongest model (GPT-5-think) reaches only 18.68% pass rate. We further observe divergent tool-use behaviors, with OpenAI models benefiting from diverse image manipulations while Gemini-2.5-pro shows no improvement. By introducing the first benchmark centered on think with images, IRIS offers critical insights for advancing visual intelligence in MLLMs.
ProSE: Diffusion Priors for Speech Enhancement
Mar 09, 2025
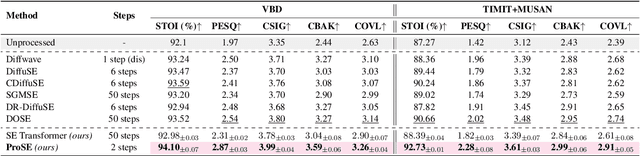
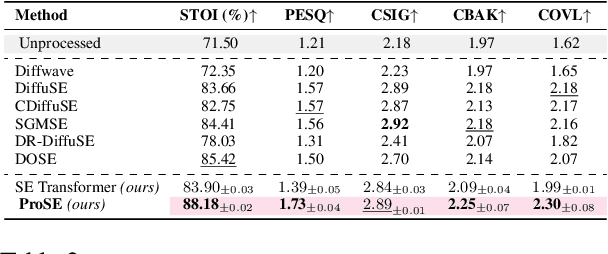
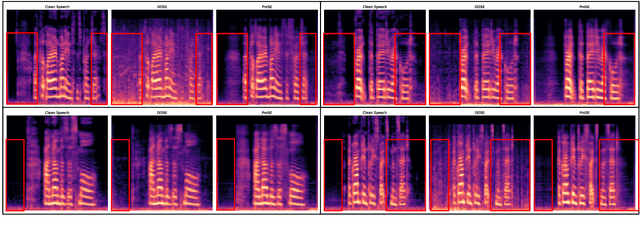
Speech enhancement (SE) is the foundational task of enhancing the clarity and quality of speech in the presence of non-stationary additive noise. While deterministic deep learning models have been commonly employed for SE, recent research indicates that generative models, such as denoising diffusion probabilistic models (DDPMs), have shown promise. However, unlike speech generation, SE has a strong constraint in generating results in accordance with the underlying ground-truth signal. Additionally, for a wide variety of applications, SE systems need to be employed in real-time, and traditional diffusion models (DMs) requiring many iterations of a large model during inference are inefficient. To address these issues, we propose ProSE (diffusion-based Priors for SE), a novel methodology based on an alternative framework for applying diffusion models to SE. Specifically, we first apply DDPMs to generate priors in a latent space due to their powerful distribution mapping capabilities. The priors are then integrated into a transformer-based regression model for SE. The priors guide the regression model in the enhancement process. Since the diffusion process is applied to a compact latent space, the diffusion model takes fewer iterations than the traditional DM to obtain accurate estimations. Additionally, using a regression model for SE avoids the distortion issue caused by misaligned details generated by DMs. Our experiments show that ProSE achieves state-of-the-art performance on benchmark datasets with fewer computational costs.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
Jun 17, 2024



Perceiving and understanding non-speech sounds and non-verbal speech is essential to making decisions that help us interact with our surroundings. In this paper, we propose GAMA, a novel General-purpose Large Audio-Language Model (LALM) with Advanced Audio Understanding and Complex Reasoning Abilities. We build GAMA by integrating an LLM with multiple types of audio representations, including features from a custom Audio Q-Former, a multi-layer aggregator that aggregates features from multiple layers of an audio encoder. We fine-tune GAMA on a large-scale audio-language dataset, which augments it with audio understanding capabilities. Next, we propose CompA-R (Instruction-Tuning for Complex Audio Reasoning), a synthetically generated instruction-tuning (IT) dataset with instructions that require the model to perform complex reasoning on the input audio. We instruction-tune GAMA with CompA-R to endow it with complex reasoning abilities, where we further add a soft prompt as input with high-level semantic evidence by leveraging event tags of the input audio. Finally, we also propose CompA-R-test, a human-labeled evaluation dataset for evaluating the capabilities of LALMs on open-ended audio question-answering that requires complex reasoning. Through automated and expert human evaluations, we show that GAMA outperforms all other LALMs in literature on diverse audio understanding tasks by margins of 1%-84%. Further, GAMA IT-ed on CompA-R proves to be superior in its complex reasoning and instruction following capabilities.
LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition
Jun 06, 2024



Visual cues, like lip motion, have been shown to improve the performance of Automatic Speech Recognition (ASR) systems in noisy environments. We propose LipGER (Lip Motion aided Generative Error Correction), a novel framework for leveraging visual cues for noise-robust ASR. Instead of learning the cross-modal correlation between the audio and visual modalities, we make an LLM learn the task of visually-conditioned (generative) ASR error correction. Specifically, we instruct an LLM to predict the transcription from the N-best hypotheses generated using ASR beam-search. This is further conditioned on lip motions. This approach addresses key challenges in traditional AVSR learning, such as the lack of large-scale paired datasets and difficulties in adapting to new domains. We experiment on 4 datasets in various settings and show that LipGER improves the Word Error Rate in the range of 1.1%-49.2%. We also release LipHyp, a large-scale dataset with hypothesis-transcription pairs that is additionally equipped with lip motion cues to promote further research in this space
ABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions
Jun 06, 2024



We present ABEX, a novel and effective generative data augmentation methodology for low-resource Natural Language Understanding (NLU) tasks. ABEX is based on ABstract-and-EXpand, a novel paradigm for generating diverse forms of an input document -- we first convert a document into its concise, abstract description and then generate new documents based on expanding the resultant abstraction. To learn the task of expanding abstract descriptions, we first train BART on a large-scale synthetic dataset with abstract-document pairs. Next, to generate abstract descriptions for a document, we propose a simple, controllable, and training-free method based on editing AMR graphs. ABEX brings the best of both worlds: by expanding from abstract representations, it preserves the original semantic properties of the documents, like style and meaning, thereby maintaining alignment with the original label and data distribution. At the same time, the fundamental process of elaborating on abstract descriptions facilitates diverse generations. We demonstrate the effectiveness of ABEX on 4 NLU tasks spanning 12 datasets and 4 low-resource settings. ABEX outperforms all our baselines qualitatively with improvements of 0.04% - 38.8%. Qualitatively, ABEX outperforms all prior methods from literature in terms of context and length diversity.
VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap
May 24, 2024Recent interest in Large Vision-Language Models (LVLMs) for practical applications is moderated by the significant challenge of hallucination or the inconsistency between the factual information and the generated text. In this paper, we first perform an in-depth analysis of hallucinations and discover several novel insights about how and when LVLMs hallucinate. From our analysis, we show that: (1) The community's efforts have been primarily targeted towards reducing hallucinations related to visual recognition (VR) prompts (e.g., prompts that only require describing the image), thereby ignoring hallucinations for cognitive prompts (e.g., prompts that require additional skills like reasoning on contents of the image). (2) LVLMs lack visual perception, i.e., they can see but not necessarily understand or perceive the input image. We analyze responses to cognitive prompts and show that LVLMs hallucinate due to a perception gap: although LVLMs accurately recognize visual elements in the input image and possess sufficient cognitive skills, they struggle to respond accurately and hallucinate. To overcome this shortcoming, we propose Visual Description Grounded Decoding (VDGD), a simple, robust, and training-free method for alleviating hallucinations. Specifically, we first describe the image and add it as a prefix to the instruction. Next, during auto-regressive decoding, we sample from the plausible candidates according to their KL-Divergence (KLD) to the description, where lower KLD is given higher preference. Experimental results on several benchmarks and LVLMs show that VDGD improves significantly over other baselines in reducing hallucinations. We also propose VaLLu, a benchmark for the comprehensive evaluation of the cognitive capabilities of LVLMs.
CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP
Mar 30, 2024We present CoDa (Constrained Generation based Data Augmentation), a controllable, effective, and training-free data augmentation technique for low-resource (data-scarce) NLP. Our approach is based on prompting off-the-shelf instruction-following Large Language Models (LLMs) for generating text that satisfies a set of constraints. Precisely, we extract a set of simple constraints from every instance in the low-resource dataset and verbalize them to prompt an LLM to generate novel and diverse training instances. Our findings reveal that synthetic data that follows simple constraints in the downstream dataset act as highly effective augmentations, and CoDa can achieve this without intricate decoding-time constrained generation techniques or fine-tuning with complex algorithms that eventually make the model biased toward the small number of training instances. Additionally, CoDa is the first framework that provides users explicit control over the augmentation generation process, thereby also allowing easy adaptation to several domains. We demonstrate the effectiveness of CoDa across 11 datasets spanning 3 tasks and 3 low-resource settings. CoDa outperforms all our baselines, qualitatively and quantitatively, with improvements of 0.12%-7.19%. Code is available here: https://github.com/Sreyan88/CoDa
Do Vision-Language Models Understand Compound Nouns?
Mar 30, 2024



Open-vocabulary vision-language models (VLMs) like CLIP, trained using contrastive loss, have emerged as a promising new paradigm for text-to-image retrieval. However, do VLMs understand compound nouns (CNs) (e.g., lab coat) as well as they understand nouns (e.g., lab)? We curate Compun, a novel benchmark with 400 unique and commonly used CNs, to evaluate the effectiveness of VLMs in interpreting CNs. The Compun benchmark challenges a VLM for text-to-image retrieval where, given a text prompt with a CN, the task is to select the correct image that shows the CN among a pair of distractor images that show the constituent nouns that make up the CN. Next, we perform an in-depth analysis to highlight CLIPs' limited understanding of certain types of CNs. Finally, we present an alternative framework that moves beyond hand-written templates for text prompts widely used by CLIP-like models. We employ a Large Language Model to generate multiple diverse captions that include the CN as an object in the scene described by the caption. Our proposed method improves CN understanding of CLIP by 8.25% on Compun. Code and benchmark are available at: https://github.com/sonalkum/Compun