 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSE: Diffusion Priors for Speech Enhancement
Mar 09, 2025
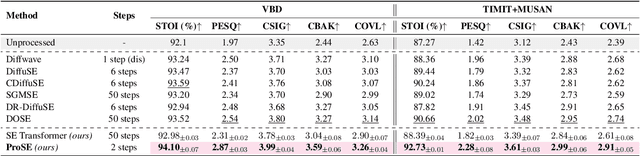
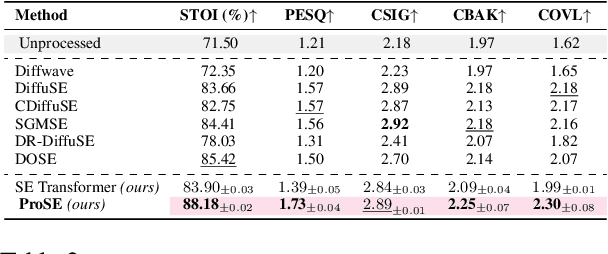
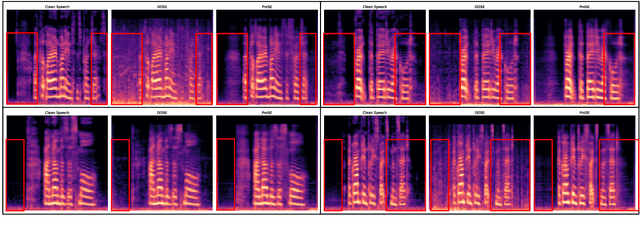
Speech enhancement (SE) is the foundational task of enhancing the clarity and quality of speech in the presence of non-stationary additive noise. While deterministic deep learning models have been commonly employed for SE, recent research indicates that generative models, such as denoising diffusion probabilistic models (DDPMs), have shown promise. However, unlike speech generation, SE has a strong constraint in generating results in accordance with the underlying ground-truth signal. Additionally, for a wide variety of applications, SE systems need to be employed in real-time, and traditional diffusion models (DMs) requiring many iterations of a large model during inference are inefficient. To address these issues, we propose ProSE (diffusion-based Priors for SE), a novel methodology based on an alternative framework for applying diffusion models to SE. Specifically, we first apply DDPMs to generate priors in a latent space due to their powerful distribution mapping capabilities. The priors are then integrated into a transformer-based regression model for SE. The priors guide the regression model in the enhancement process. Since the diffusion process is applied to a compact latent space, the diffusion model takes fewer iterations than the traditional DM to obtain accurate estimations. Additionally, using a regression model for SE avoids the distortion issue caused by misaligned details generated by DMs. Our experiments show that ProSE achieves state-of-the-art performance on benchmark datasets with fewer computational costs.
ReCLAP: Improving Zero Shot Audio Classification by Describing Sounds
Sep 13, 2024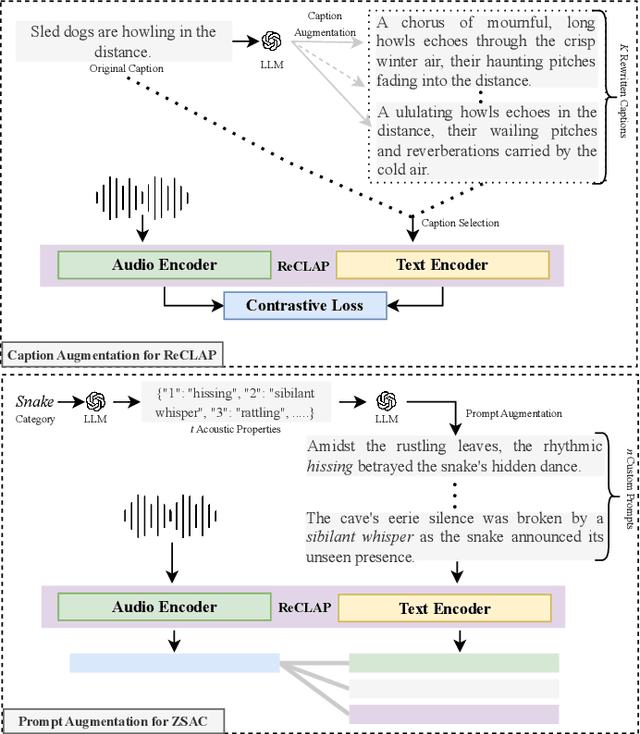

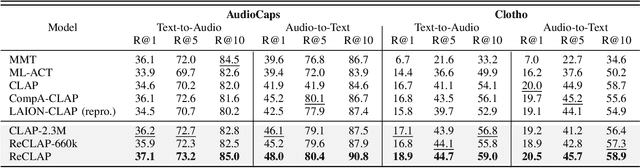
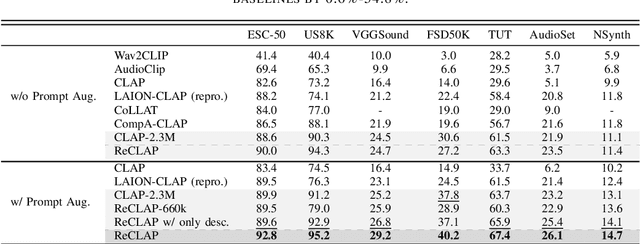
Open-vocabulary audio-language models, like CLAP, offer a promising approach for zero-shot audio classification (ZSAC) by enabling classification with any arbitrary set of categories specified with natural language prompts. In this paper, we propose a simple but effective method to improve ZSAC with CLAP. Specifically, we shift from the conventional method of using prompts with abstract category labels (e.g., Sound of an organ) to prompts that describe sounds using their inherent descriptive features in a diverse context (e.g.,The organ's deep and resonant tones filled the cathedral.). To achieve this, we first propose ReCLAP, a CLAP model trained with rewritten audio captions for improved understanding of sounds in the wild. These rewritten captions describe each sound event in the original caption using their unique discriminative characteristics. ReCLAP outperforms all baselines on both multi-modal audio-text retrieval and ZSAC. Next, to improve zero-shot audio classification with ReCLAP, we propose prompt augmentation. In contrast to the traditional method of employing hand-written template prompts, we generate custom prompts for each unique label in the dataset. These custom prompts first describe the sound event in the label and then employ them in diverse scenes. Our proposed method improves ReCLAP's performance on ZSAC by 1%-18% and outperforms all baselines by 1% - 55%.
GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
Jun 17, 2024



Perceiving and understanding non-speech sounds and non-verbal speech is essential to making decisions that help us interact with our surroundings. In this paper, we propose GAMA, a novel General-purpose Large Audio-Language Model (LALM) with Advanced Audio Understanding and Complex Reasoning Abilities. We build GAMA by integrating an LLM with multiple types of audio representations, including features from a custom Audio Q-Former, a multi-layer aggregator that aggregates features from multiple layers of an audio encoder. We fine-tune GAMA on a large-scale audio-language dataset, which augments it with audio understanding capabilities. Next, we propose CompA-R (Instruction-Tuning for Complex Audio Reasoning), a synthetically generated instruction-tuning (IT) dataset with instructions that require the model to perform complex reasoning on the input audio. We instruction-tune GAMA with CompA-R to endow it with complex reasoning abilities, where we further add a soft prompt as input with high-level semantic evidence by leveraging event tags of the input audio. Finally, we also propose CompA-R-test, a human-labeled evaluation dataset for evaluating the capabilities of LALMs on open-ended audio question-answering that requires complex reasoning. Through automated and expert human evaluations, we show that GAMA outperforms all other LALMs in literature on diverse audio understanding tasks by margins of 1%-84%. Further, GAMA IT-ed on CompA-R proves to be superior in its complex reasoning and instruction following capabilities.
VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap
May 24, 2024Recent interest in Large Vision-Language Models (LVLMs) for practical applications is moderated by the significant challenge of hallucination or the inconsistency between the factual information and the generated text. In this paper, we first perform an in-depth analysis of hallucinations and discover several novel insights about how and when LVLMs hallucinate. From our analysis, we show that: (1) The community's efforts have been primarily targeted towards reducing hallucinations related to visual recognition (VR) prompts (e.g., prompts that only require describing the image), thereby ignoring hallucinations for cognitive prompts (e.g., prompts that require additional skills like reasoning on contents of the image). (2) LVLMs lack visual perception, i.e., they can see but not necessarily understand or perceive the input image. We analyze responses to cognitive prompts and show that LVLMs hallucinate due to a perception gap: although LVLMs accurately recognize visual elements in the input image and possess sufficient cognitive skills, they struggle to respond accurately and hallucinate. To overcome this shortcoming, we propose Visual Description Grounded Decoding (VDGD), a simple, robust, and training-free method for alleviating hallucinations. Specifically, we first describe the image and add it as a prefix to the instruction. Next, during auto-regressive decoding, we sample from the plausible candidates according to their KL-Divergence (KLD) to the description, where lower KLD is given higher preference. Experimental results on several benchmarks and LVLMs show that VDGD improves significantly over other baselines in reducing hallucinations. We also propose VaLLu, a benchmark for the comprehensive evaluation of the cognitive capabilities of LVLMs.
CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP
Mar 30, 2024We present CoDa (Constrained Generation based Data Augmentation), a controllable, effective, and training-free data augmentation technique for low-resource (data-scarce) NLP. Our approach is based on prompting off-the-shelf instruction-following Large Language Models (LLMs) for generating text that satisfies a set of constraints. Precisely, we extract a set of simple constraints from every instance in the low-resource dataset and verbalize them to prompt an LLM to generate novel and diverse training instances. Our findings reveal that synthetic data that follows simple constraints in the downstream dataset act as highly effective augmentations, and CoDa can achieve this without intricate decoding-time constrained generation techniques or fine-tuning with complex algorithms that eventually make the model biased toward the small number of training instances. Additionally, CoDa is the first framework that provides users explicit control over the augmentation generation process, thereby also allowing easy adaptation to several domains. We demonstrate the effectiveness of CoDa across 11 datasets spanning 3 tasks and 3 low-resource settings. CoDa outperforms all our baselines, qualitatively and quantitatively, with improvements of 0.12%-7.19%. Code is available here: https://github.com/Sreyan88/CoDa
A Closer Look at the Limitations of Instruction Tuning
Feb 03, 2024Instruction Tuning (IT), the process of training large language models (LLMs) using instruction-response pairs, has emerged as the predominant method for transforming base pre-trained LLMs into open-domain conversational agents. While IT has achieved notable success and widespread adoption, its limitations and shortcomings remain underexplored. In this paper, through rigorous experiments and an in-depth analysis of the changes LLMs undergo through IT, we reveal various limitations of IT. In particular, we show that (1) IT fails to enhance knowledge or skills in LLMs. LoRA fine-tuning is limited to learning response initiation and style tokens, and full-parameter fine-tuning leads to knowledge degradation. (2) Copying response patterns from IT datasets derived from knowledgeable sources leads to a decline in response quality. (3) Full-parameter fine-tuning increases hallucination by inaccurately borrowing tokens from conceptually similar instances in the IT dataset for generating responses. (4) Popular methods to improve IT do not lead to performance improvements over a simple LoRA fine-tuned model. Our findings reveal that responses generated solely from pre-trained knowledge consistently outperform responses by models that learn any form of new knowledge from IT on open-source datasets. We hope the insights and challenges revealed inspire future work.
RECAP: Retrieval-Augmented Audio Captioning
Sep 18, 2023We present RECAP (REtrieval-Augmented Audio CAPtioning), a novel and effective audio captioning system that generates captions conditioned on an input audio and other captions similar to the audio retrieved from a datastore. Additionally, our proposed method can transfer to any domain without the need for any additional fine-tuning. To generate a caption for an audio sample, we leverage an audio-text model CLAP to retrieve captions similar to it from a replaceable datastore, which are then used to construct a prompt. Next, we feed this prompt to a GPT-2 decoder and introduce cross-attention layers between the CLAP encoder and GPT-2 to condition the audio for caption generation. Experiments on two benchmark datasets, Clotho and AudioCaps, show that RECAP achieves competitive performance in in-domain settings and significant improvements in out-of-domain settings. Additionally, due to its capability to exploit a large text-captions-only datastore in a \textit{training-free} fashion, RECAP shows unique capabilities of captioning novel audio events never seen during training and compositional audios with multiple events. To promote research in this space, we also release 150,000+ new weakly labeled captions for AudioSet, AudioCaps, and Clotho.
ASPIRE: Language-Guided Augmentation for Robust Image Classification
Aug 19, 2023Neural image classifiers can often learn to make predictions by overly relying on non-predictive features that are spuriously correlated with the class labels in the training data. This leads to poor performance in real-world atypical scenarios where such features are absent. Supplementing the training dataset with images without such spurious features can aid robust learning against spurious correlations via better generalization. This paper presents ASPIRE (Language-guided data Augmentation for SPurIous correlation REmoval), a simple yet effective solution for expanding the training dataset with synthetic images without spurious features. ASPIRE, guided by language, generates these images without requiring any form of additional supervision or existing examples. Precisely, we employ LLMs to first extract foreground and background features from textual descriptions of an image, followed by advanced language-guided image editing to discover the features that are spuriously correlated with the class label. Finally, we personalize a text-to-image generation model to generate diverse in-domain images without spurious features. We demonstrate the effectiveness of ASPIRE on 4 datasets, including the very challenging Hard ImageNet dataset, and 9 baselines and show that ASPIRE improves the classification accuracy of prior methods by 1% - 38%. Code soon at: https://github.com/Sreyan88/ASPIRE.