 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMD-FCG: An Enhanced Function Call Graph Dataset with Integrated Topological Features for Malware Detection and Classification
Jun 05, 2026As malware illustrates a complex structure and behavior, detection of these has been a significant challenge in the domain of cybersecurity along with related services in daily life. So, it becomes crucial to have a reliable and adaptive solution to address the issue. Among the several detection methods developed over the years, one of the most reliable ones is studying and analyzing the structural and behavioral patterns of malware. These patterns of sophisticated malware can be obtained with the help of Function Call Graphs (FCGs). However, to effectively cover numerous groups of families of malware, it is required to have a sufficiently large dataset for the system to operate on. In order to ensure accuracy and robustness of the system, the dataset should comprise samples of different malwares and a benign application for secure execution of the detection process. This paper introduces AMD-FCG, an enhanced Function Call Graph dataset integrated with topological features of malwares. The framework enhances the detection procedure, streamlining the workflow for cybersecurity professionals and also eliminating the need for dynamic analysis and extensive processing. Therefore, it can be used to develop and deploy more efficient and innovative malware detection systems.
Sample-Efficient Language Model for Hinglish Conversational AI
Apr 27, 2025This paper presents our process for developing a sample-efficient language model for a conversational Hinglish chatbot. Hinglish, a code-mixed language that combines Hindi and English, presents a unique computational challenge due to inconsistent spelling, lack of standardization, and limited quality of conversational data. This work evaluates multiple pre-trained cross-lingual language models, including Gemma3-4B and Qwen2.5-7B, and employs fine-tuning techniques to improve performance on Hinglish conversational tasks. The proposed approach integrates synthetically generated dialogues with insights from existing Hinglish datasets to address data scarcity. Experimental results demonstrate that models with fewer parameters, when appropriately fine-tuned on high-quality code-mixed data, can achieve competitive performance for Hinglish conversation generation while maintaining computational efficiency.
Design and Development of the MeCO Open-Source Autonomous Underwater Vehicle
Mar 13, 2025We present MeCO, the Medium Cost Open-source autonomous underwater vehicle (AUV), a versatile autonomous vehicle designed to support research and development in underwater human-robot interaction (UHRI) and marine robotics in general. An inexpensive platform to build compared to similarly-capable AUVs, the MeCO design and software are released under open-source licenses, making it a cost effective, extensible, and open platform. It is equipped with UHRI-focused systems, such as front and side facing displays, light-based communication devices, a transducer for acoustic interaction, and stereo vision, in addition to typical AUV sensing and actuation components. Additionally, MeCO is capable of real-time deep learning inference using the latest edge computing devices, while maintaining low-latency, closed-loop control through high-performance microcontrollers. MeCO is designed from the ground up for modularity in internal electronics, external payloads, and software architecture, exploiting open-source robotics and containerarization tools. We demonstrate the diverse capabilities of MeCO through simulated, closed-water, and open-water experiments. All resources necessary to build and run MeCO, including software and hardware design, have been made publicly available.
The Common Objects Underwater (COU) Dataset for Robust Underwater Object Detection
Feb 28, 2025We introduce COU: Common Objects Underwater, an instance-segmented image dataset of commonly found man-made objects in multiple aquatic and marine environments. COU contains approximately 10K segmented images, annotated from images collected during a number of underwater robot field trials in diverse locations. COU has been created to address the lack of datasets with robust class coverage curated for underwater instance segmentation, which is particularly useful for training light-weight, real-time capable detectors for Autonomous Underwater Vehicles (AUVs). In addition, COU addresses the lack of diversity in object classes since the commonly available underwater image datasets focus only on marine life. Currently, COU contains images from both closed-water (pool) and open-water (lakes and oceans) environments, of 24 different classes of objects including marine debris, dive tools, and AUVs. To assess the efficacy of COU in training underwater object detectors, we use three state-of-the-art models to evaluate its performance and accuracy, using a combination of standard accuracy and efficiency metrics. The improved performance of COU-trained detectors over those solely trained on terrestrial data demonstrates the clear advantage of training with annotated underwater images. We make COU available for broad use under open-source licenses.
IBURD: Image Blending for Underwater Robotic Detection
Feb 24, 2025We present an image blending pipeline, \textit{IBURD}, that creates realistic synthetic images to assist in the training of deep detectors for use on underwater autonomous vehicles (AUVs) for marine debris detection tasks. Specifically, IBURD generates both images of underwater debris and their pixel-level annotations, using source images of debris objects, their annotations, and target background images of marine environments. With Poisson editing and style transfer techniques, IBURD is even able to robustly blend transparent objects into arbitrary backgrounds and automatically adjust the style of blended images using the blurriness metric of target background images. These generated images of marine debris in actual underwater backgrounds address the data scarcity and data variety problems faced by deep-learned vision algorithms in challenging underwater conditions, and can enable the use of AUVs for environmental cleanup missions. Both quantitative and robotic evaluations of IBURD demonstrate the efficacy of the proposed approach for robotic detection of marine debris.
ASPIRE: Language-Guided Augmentation for Robust Image Classification
Aug 19, 2023Neural image classifiers can often learn to make predictions by overly relying on non-predictive features that are spuriously correlated with the class labels in the training data. This leads to poor performance in real-world atypical scenarios where such features are absent. Supplementing the training dataset with images without such spurious features can aid robust learning against spurious correlations via better generalization. This paper presents ASPIRE (Language-guided data Augmentation for SPurIous correlation REmoval), a simple yet effective solution for expanding the training dataset with synthetic images without spurious features. ASPIRE, guided by language, generates these images without requiring any form of additional supervision or existing examples. Precisely, we employ LLMs to first extract foreground and background features from textual descriptions of an image, followed by advanced language-guided image editing to discover the features that are spuriously correlated with the class label. Finally, we personalize a text-to-image generation model to generate diverse in-domain images without spurious features. We demonstrate the effectiveness of ASPIRE on 4 datasets, including the very challenging Hard ImageNet dataset, and 9 baselines and show that ASPIRE improves the classification accuracy of prior methods by 1% - 38%. Code soon at: https://github.com/Sreyan88/ASPIRE.
Multiview Scattering Scanning Imaging Confocal Microscopy through a Multimode Fiber
Feb 22, 2022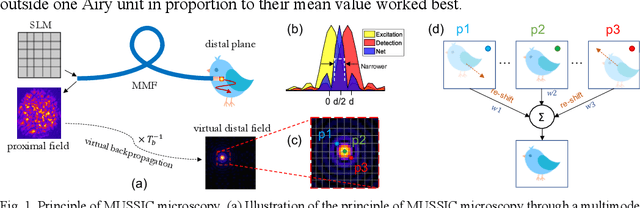
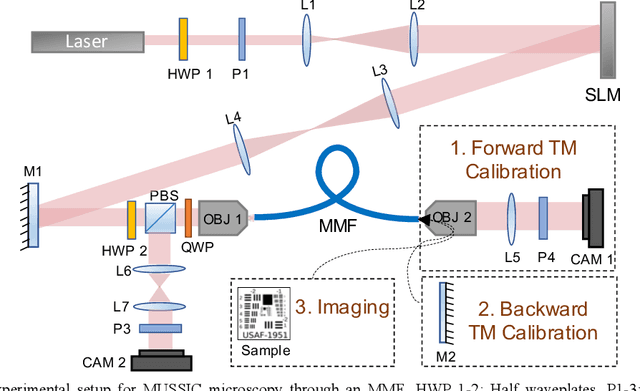
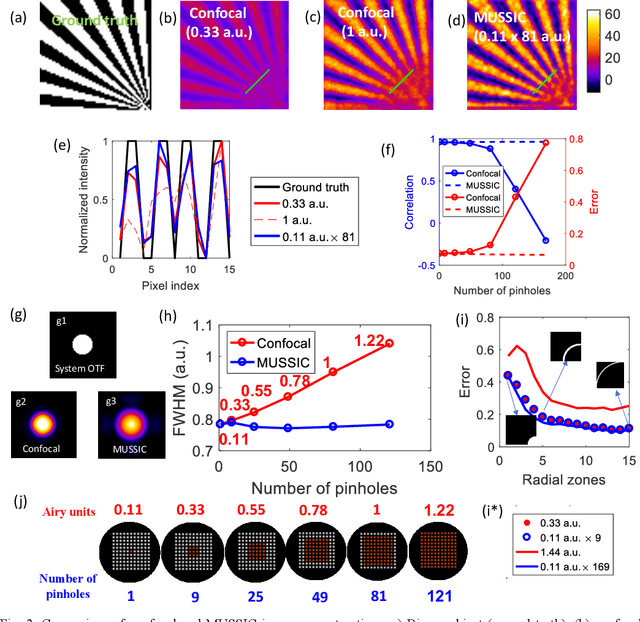
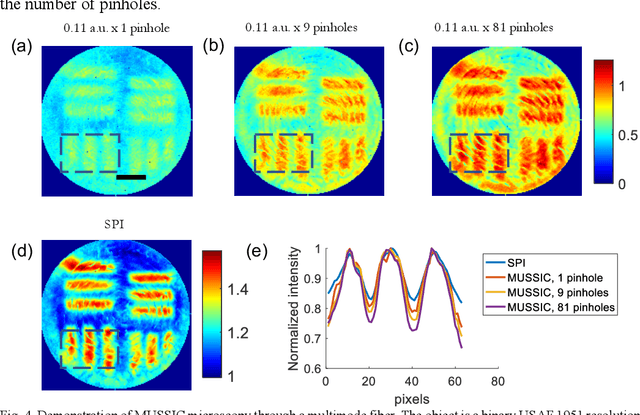
Confocal and multiphoton microscopy are effective techniques to obtain high-contrast images of 2-D sections within bulk tissue. However, scattering limits their application to depths only up to ~1 millimeter. Multimode fibers make excellent ultrathin endoscopes that can penetrate deep inside the tissue with minimal damage. Here, we present Multiview Scattering Scanning Imaging Confocal (MUSSIC) Microscopy that enables high signal-to-noise ratio (SNR) imaging through a multimode fiber, hence combining the optical sectioning and resolution gain of confocal microscopy with the minimally invasive penetration capability of multimode fibers. The key advance presented here is the high SNR image reconstruction enabled by employing multiple coplanar virtual pinholes to capture multiple perspectives of the object, re-shifting them appropriately and combining them to obtain a high-contrast and high-resolution confocal image. We present the theory for the gain in contrast and resolution in MUSSIC microscopy and validate the concept through experimental results.
IITK at the FinSim Task: Hypernym Detection in Financial Domain via Context-Free and Contextualized Word Embeddings
Jul 22, 2020

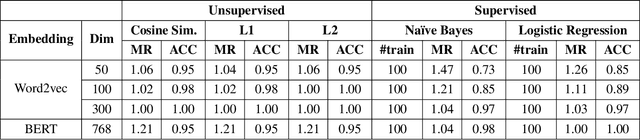
In this paper, we present our approaches for the FinSim 2020 shared task on "Learning Semantic Representations for the Financial Domain". The goal of this task is to classify financial terms into the most relevant hypernym (or top-level) concept in an external ontology. We leverage both context-dependent and context-independent word embeddings in our analysis. Our systems deploy Word2vec embeddings trained from scratch on the corpus (Financial Prospectus in English) along with pre-trained BERT embeddings. We divide the test dataset into two subsets based on a domain rule. For one subset, we use unsupervised distance measures to classify the term. For the second subset, we use simple supervised classifiers like Naive Bayes, on top of the embeddings, to arrive at a final prediction. Finally, we combine both the results. Our system ranks 1st based on both the metrics, i.e., mean rank and accuracy.
IITK at SemEval-2020 Task 8: Unimodal and Bimodal Sentiment Analysis of Internet Memes
Jul 21, 2020
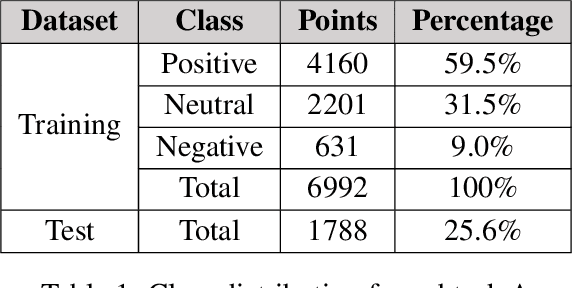
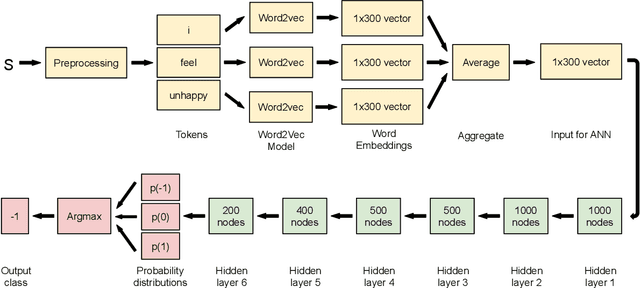
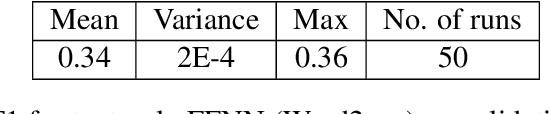
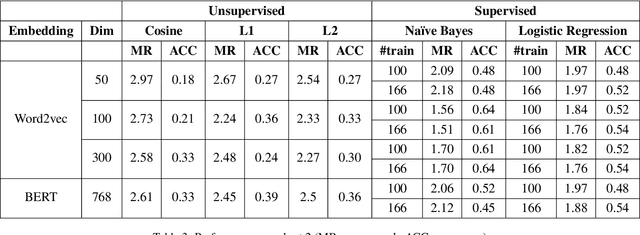
Social media is abundant in visual and textual information presented together or in isolation. Memes are the most popular form, belonging to the former class. In this paper, we present our approaches for the Memotion Analysis problem as posed in SemEval-2020 Task 8. The goal of this task is to classify memes based on their emotional content and sentiment. We leverage techniques from Natural Language Processing (NLP) and Computer Vision (CV) towards the sentiment classification of internet memes (Subtask A). We consider Bimodal (text and image) as well as Unimodal (text-only) techniques in our study ranging from the Na\"ive Bayes classifier to Transformer-based approaches. Our results show that a text-only approach, a simple Feed Forward Neural Network (FFNN) with Word2vec embeddings as input, performs superior to all the others. We stand first in the Sentiment analysis task with a relative improvement of 63% over the baseline macro-F1 score. Our work is relevant to any task concerned with the combination of different modalities.