 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITK at the FinSim Task: Hypernym Detection in Financial Domain via Context-Free and Contextualized Word Embeddings
Jul 22, 2020

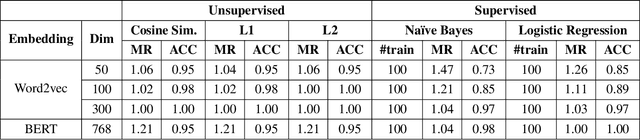
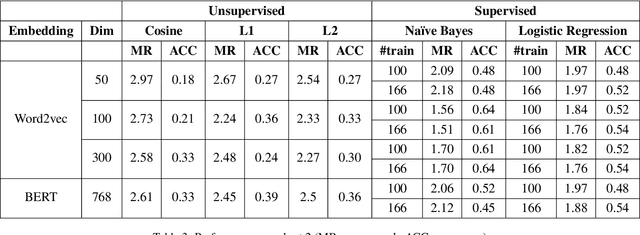
In this paper, we present our approaches for the FinSim 2020 shared task on "Learning Semantic Representations for the Financial Domain". The goal of this task is to classify financial terms into the most relevant hypernym (or top-level) concept in an external ontology. We leverage both context-dependent and context-independent word embeddings in our analysis. Our systems deploy Word2vec embeddings trained from scratch on the corpus (Financial Prospectus in English) along with pre-trained BERT embeddings. We divide the test dataset into two subsets based on a domain rule. For one subset, we use unsupervised distance measures to classify the term. For the second subset, we use simple supervised classifiers like Naive Bayes, on top of the embeddings, to arrive at a final prediction. Finally, we combine both the results. Our system ranks 1st based on both the metrics, i.e., mean rank and accuracy.
IITK at SemEval-2020 Task 8: Unimodal and Bimodal Sentiment Analysis of Internet Memes
Jul 21, 2020
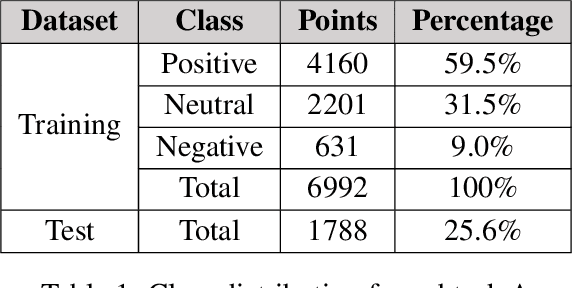
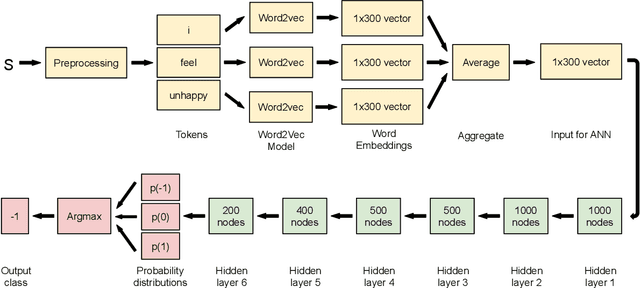
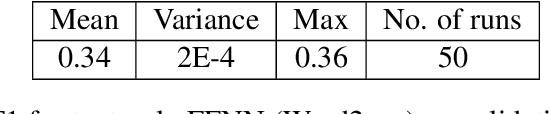
Social media is abundant in visual and textual information presented together or in isolation. Memes are the most popular form, belonging to the former class. In this paper, we present our approaches for the Memotion Analysis problem as posed in SemEval-2020 Task 8. The goal of this task is to classify memes based on their emotional content and sentiment. We leverage techniques from Natural Language Processing (NLP) and Computer Vision (CV) towards the sentiment classification of internet memes (Subtask A). We consider Bimodal (text and image) as well as Unimodal (text-only) techniques in our study ranging from the Na\"ive Bayes classifier to Transformer-based approaches. Our results show that a text-only approach, a simple Feed Forward Neural Network (FFNN) with Word2vec embeddings as input, performs superior to all the others. We stand first in the Sentiment analysis task with a relative improvement of 63% over the baseline macro-F1 score. Our work is relevant to any task concerned with the combination of different modalities.