 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-LEAD: Contrastive Learning for Enhanced Adversarial Defense
Oct 31, 2025



Deep neural networks (DNNs) have achieved remarkable success in computer vision tasks such as image classification, segmentation, and object detection. However, they are vulnerable to adversarial attacks, which can cause incorrect predictions with small perturbations in input images. Addressing this issue is crucial for deploying robust deep-learning systems. This paper presents a novel approach that utilizes contrastive learning for adversarial defense, a previously unexplored area. Our method leverages the contrastive loss function to enhance the robustness of classification models by training them with both clean and adversarially perturbed images. By optimizing the model's parameters alongside the perturbations, our approach enables the network to learn robust representations that are less susceptible to adversarial attacks. Experimental results show significant improvements in the model's robustness against various types of adversarial perturbations. This suggests that contrastive loss helps extract more informative and resilient features, contributing to the field of adversarial robustness in deep learning.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
ProSE: Diffusion Priors for Speech Enhancement
Mar 09, 2025
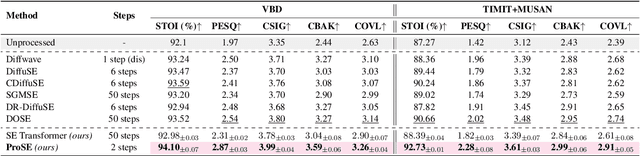
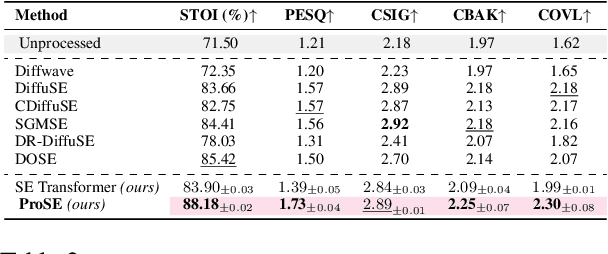
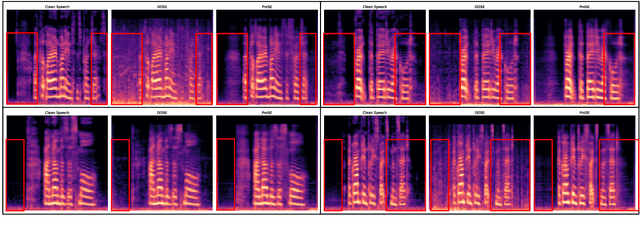
Speech enhancement (SE) is the foundational task of enhancing the clarity and quality of speech in the presence of non-stationary additive noise. While deterministic deep learning models have been commonly employed for SE, recent research indicates that generative models, such as denoising diffusion probabilistic models (DDPMs), have shown promise. However, unlike speech generation, SE has a strong constraint in generating results in accordance with the underlying ground-truth signal. Additionally, for a wide variety of applications, SE systems need to be employed in real-time, and traditional diffusion models (DMs) requiring many iterations of a large model during inference are inefficient. To address these issues, we propose ProSE (diffusion-based Priors for SE), a novel methodology based on an alternative framework for applying diffusion models to SE. Specifically, we first apply DDPMs to generate priors in a latent space due to their powerful distribution mapping capabilities. The priors are then integrated into a transformer-based regression model for SE. The priors guide the regression model in the enhancement process. Since the diffusion process is applied to a compact latent space, the diffusion model takes fewer iterations than the traditional DM to obtain accurate estimations. Additionally, using a regression model for SE avoids the distortion issue caused by misaligned details generated by DMs. Our experiments show that ProSE achieves state-of-the-art performance on benchmark datasets with fewer computational costs.
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
Mar 06, 2025Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities. AF2 leverages (i) a custom CLAP model, (ii) synthetic Audio QA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across over 20 benchmarks. Next, for the first time, we extend audio understanding to long audio segments (30 secs to 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks. Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach. Project Website: https://research.nvidia.com/labs/adlr/AF2/.
SILA: Signal-to-Language Augmentation for Enhanced Control in Text-to-Audio Generation
Dec 13, 2024The field of text-to-audio generation has seen significant advancements, and yet the ability to finely control the acoustic characteristics of generated audio remains under-explored. In this paper, we introduce a novel yet simple approach to generate sound effects with control over key acoustic parameters such as loudness, pitch, reverb, fade, brightness, noise and duration, enabling creative applications in sound design and content creation. These parameters extend beyond traditional Digital Signal Processing (DSP) techniques, incorporating learned representations that capture the subtleties of how sound characteristics can be shaped in context, enabling a richer and more nuanced control over the generated audio. Our approach is model-agnostic and is based on learning the disentanglement between audio semantics and its acoustic features. Our approach not only enhances the versatility and expressiveness of text-to-audio generation but also opens new avenues for creative audio production and sound design. Our objective and subjective evaluation results demonstrate the effectiveness of our approach in producing high-quality, customizable audio outputs that align closely with user specifications.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Do Audio-Language Models Understand Linguistic Variations?
Oct 21, 2024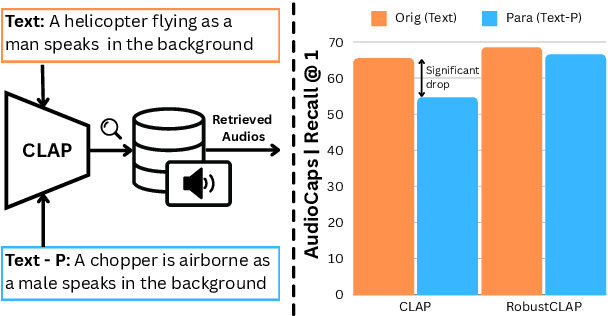
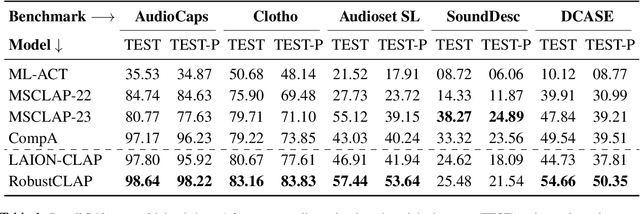
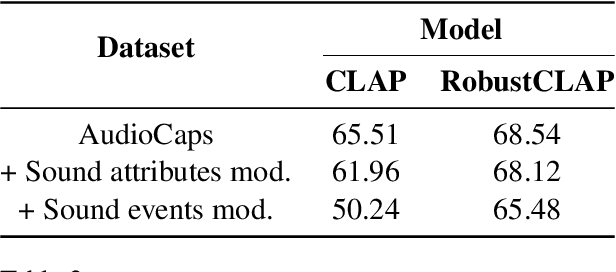
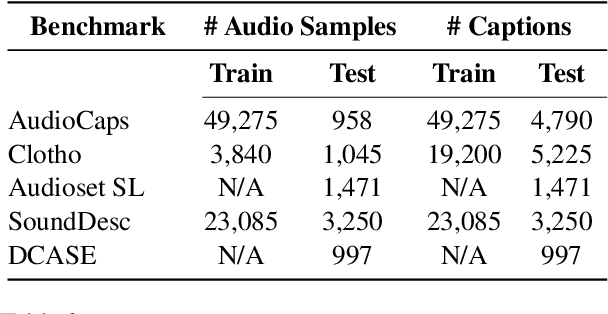
Open-vocabulary audio language models (ALMs), like Contrastive Language Audio Pretraining (CLAP), represent a promising new paradigm for audio-text retrieval using natural language queries. In this paper, for the first time, we perform controlled experiments on various benchmarks to show that existing ALMs struggle to generalize to linguistic variations in textual queries. To address this issue, we propose RobustCLAP, a novel and compute-efficient technique to learn audio-language representations agnostic to linguistic variations. Specifically, we reformulate the contrastive loss used in CLAP architectures by introducing a multi-view contrastive learning objective, where paraphrases are treated as different views of the same audio scene and use this for training. Our proposed approach improves the text-to-audio retrieval performance of CLAP by 0.8%-13% across benchmarks and enhances robustness to linguistic variation.
PAT: Parameter-Free Audio-Text Aligner to Boost Zero-Shot Audio Classification
Oct 19, 2024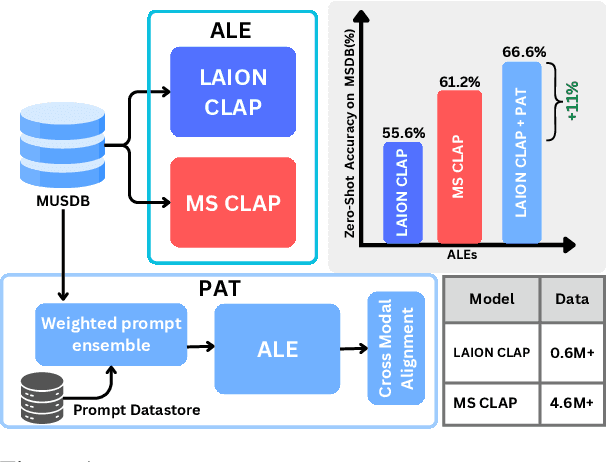
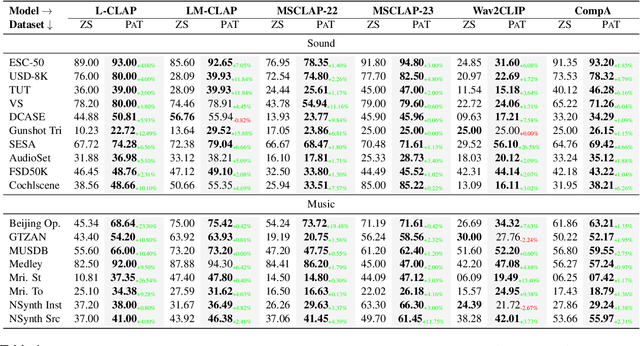
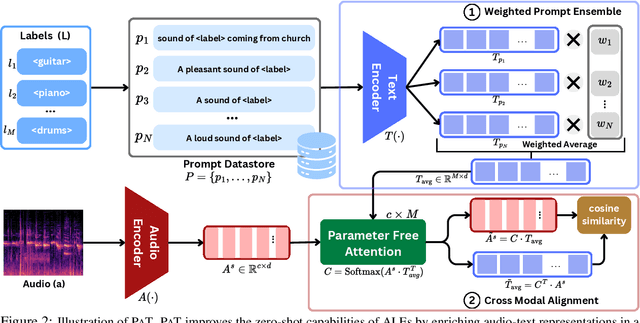

Audio-Language Models (ALMs) have demonstrated remarkable performance in zero-shot audio classification. In this paper, we introduce PAT (Parameter-free Audio-Text aligner), a simple and training-free method aimed at boosting the zero-shot audio classification performance of CLAP-like ALMs. To achieve this, we propose to improve the cross-modal interaction between audio and language modalities by enhancing the representations for both modalities using mutual feedback. Precisely, to enhance textual representations, we propose a prompt ensemble algorithm that automatically selects and combines the most relevant prompts from a datastore with a large pool of handcrafted prompts and weighs them according to their relevance to the audio. On the other hand, to enhance audio representations, we reweigh the frame-level audio features based on the enhanced textual information. Our proposed method does not require any additional modules or parameters and can be used with any existing CLAP-like ALM to improve zero-shot audio classification performance. We experiment across 18 diverse benchmark datasets and 6 ALMs and show that the PAT outperforms vanilla zero-shot evaluation with significant margins of 0.42%-27.0%. Additionally, we demonstrate that PAT maintains robust performance even when input audio is degraded by varying levels of noise. Our code will be open-sourced upon acceptance.
EH-MAM: Easy-to-Hard Masked Acoustic Modeling for Self-Supervised Speech Representation Learning
Oct 17, 2024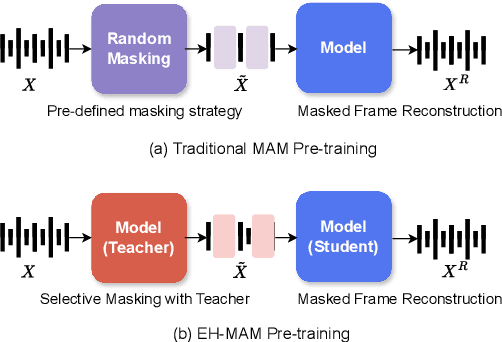
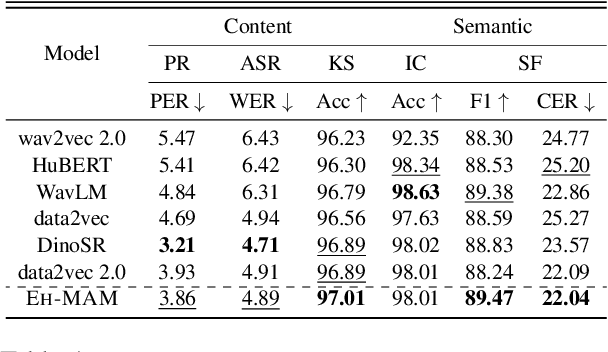
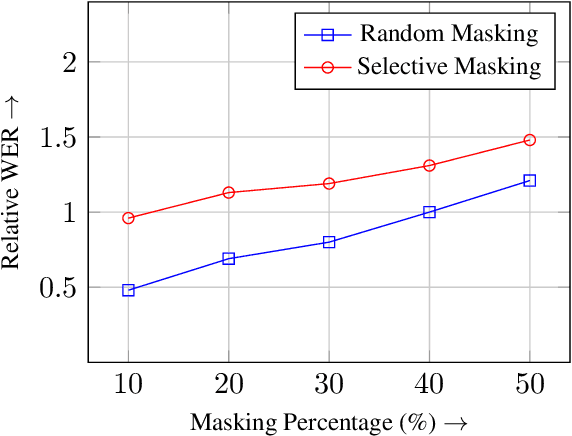

In this paper, we present EH-MAM (Easy-to-Hard adaptive Masked Acoustic Modeling), a novel self-supervised learning approach for speech representation learning. In contrast to the prior methods that use random masking schemes for Masked Acoustic Modeling (MAM), we introduce a novel selective and adaptive masking strategy. Specifically, during SSL training, we progressively introduce harder regions to the model for reconstruction. Our approach automatically selects hard regions and is built on the observation that the reconstruction loss of individual frames in MAM can provide natural signals to judge the difficulty of solving the MAM pre-text task for that frame. To identify these hard regions, we employ a teacher model that first predicts the frame-wise losses and then decides which frames to mask. By learning to create challenging problems, such as identifying harder frames and solving them simultaneously, the model is able to learn more effective representations and thereby acquire a more comprehensive understanding of the speech. Quantitatively, EH-MAM outperforms several state-of-the-art baselines across various low-resource speech recognition and SUPERB benchmarks by 5%-10%. Additionally, we conduct a thorough analysis to show that the regions masked by EH-MAM effectively capture useful context across speech frames.
Synthio: Augmenting Small-Scale Audio Classification Datasets with Synthetic Data
Oct 02, 2024



We present Synthio, a novel approach for augmenting small-scale audio classification datasets with synthetic data. Our goal is to improve audio classification accuracy with limited labeled data. Traditional data augmentation techniques, which apply artificial transformations (e.g., adding random noise or masking segments), struggle to create data that captures the true diversity present in real-world audios. To address this shortcoming, we propose to augment the dataset with synthetic audio generated from text-to-audio (T2A) diffusion models. However, synthesizing effective augmentations is challenging because not only should the generated data be acoustically consistent with the underlying small-scale dataset, but they should also have sufficient compositional diversity. To overcome the first challenge, we align the generations of the T2A model with the small-scale dataset using preference optimization. This ensures that the acoustic characteristics of the generated data remain consistent with the small-scale dataset. To address the second challenge, we propose a novel caption generation technique that leverages the reasoning capabilities of Large Language Models to (1) generate diverse and meaningful audio captions and (2) iteratively refine their quality. The generated captions are then used to prompt the aligned T2A model. We extensively evaluate Synthio on ten datasets and four simulated limited-data settings. Results indicate our method consistently outperforms all baselines by 0.1%-39% using a T2A model trained only on weakly-captioned AudioSet.