 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAT: Parameter-Free Audio-Text Aligner to Boost Zero-Shot Audio Classification
Paper and Code
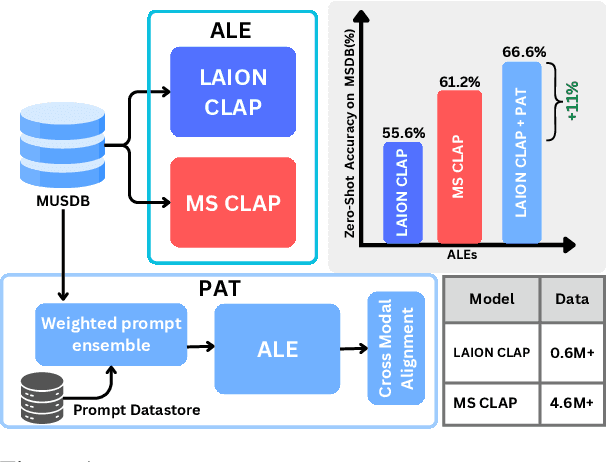
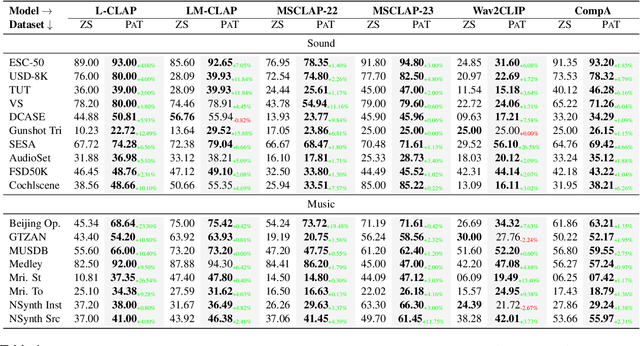
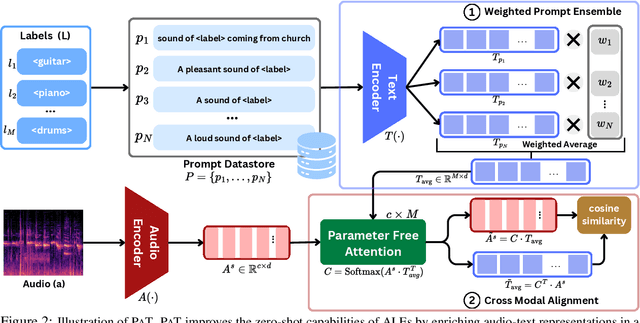

Audio-Language Models (ALMs) have demonstrated remarkable performance in zero-shot audio classification. In this paper, we introduce PAT (Parameter-free Audio-Text aligner), a simple and training-free method aimed at boosting the zero-shot audio classification performance of CLAP-like ALMs. To achieve this, we propose to improve the cross-modal interaction between audio and language modalities by enhancing the representations for both modalities using mutual feedback. Precisely, to enhance textual representations, we propose a prompt ensemble algorithm that automatically selects and combines the most relevant prompts from a datastore with a large pool of handcrafted prompts and weighs them according to their relevance to the audio. On the other hand, to enhance audio representations, we reweigh the frame-level audio features based on the enhanced textual information. Our proposed method does not require any additional modules or parameters and can be used with any existing CLAP-like ALM to improve zero-shot audio classification performance. We experiment across 18 diverse benchmark datasets and 6 ALMs and show that the PAT outperforms vanilla zero-shot evaluation with significant margins of 0.42%-27.0%. Additionally, we demonstrate that PAT maintains robust performance even when input audio is degraded by varying levels of noise. Our code will be open-sourced upon acceptance.