 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Audio-Visual Large Language Models Really See and Hear?
Apr 03, 2026Audio-Visual Large Language Models (AVLLMs) are emerging as unified interfaces to multimodal perception. We present the first mechanistic interpretability study of AVLLMs, analyzing how audio and visual features evolve and fuse through different layers of an AVLLM to produce the final text outputs. We find that although AVLLMs encode rich audio semantics at intermediate layers, these capabilities largely fail to surface in the final text generation when audio conflicts with vision. Probing analyses show that useful latent audio information is present, but deeper fusion layers disproportionately privilege visual representations that tend to suppress audio cues. We further trace this imbalance to training: the AVLLM's audio behavior strongly matches its vision-language base model, indicating limited additional alignment to audio supervision. Our findings reveal a fundamental modality bias in AVLLMs and provide new mechanistic insights into how multimodal LLMs integrate audio and vision.
Peeking Into The Future For Contextual Biasing
Dec 19, 2025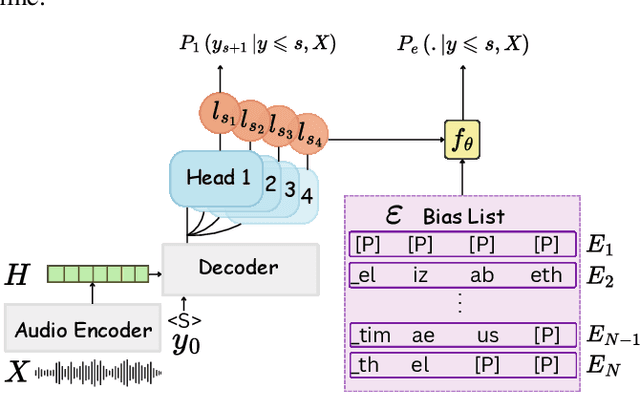
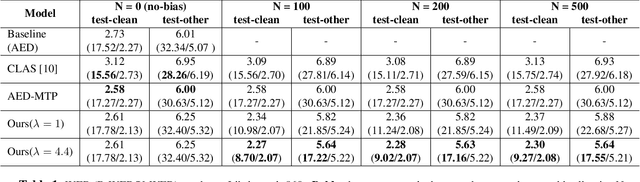
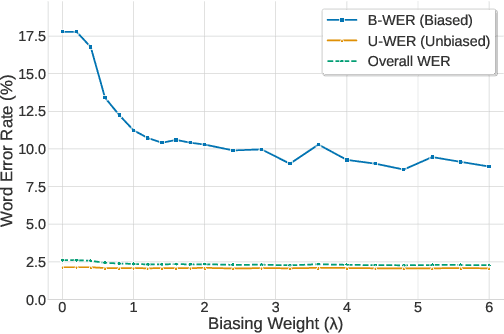
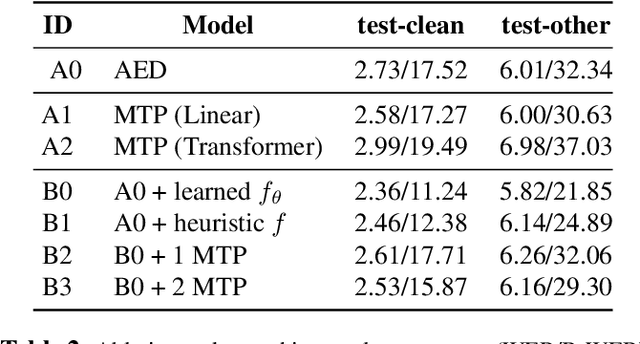
While end-to-end (E2E) automatic speech recognition (ASR) models excel at general transcription, they struggle to recognize rare or unseen named entities (e.g., contact names, locations), which are critical for downstream applications like virtual assistants. In this paper, we propose a contextual biasing method for attention based encoder decoder (AED) models using a list of candidate named entities. Instead of predicting only the next token, we simultaneously predict multiple future tokens, enabling the model to "peek into the future" and score potential candidate entities in the entity list. Moreover, our approach leverages the multi-token prediction logits directly without requiring additional entity encoders or cross-attention layers, significantly reducing architectural complexity. Experiments on Librispeech demonstrate that our approach achieves up to 50.34% relative improvement in named entity word error rate compared to the baseline AED model.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Do Audio-Language Models Understand Linguistic Variations?
Oct 21, 2024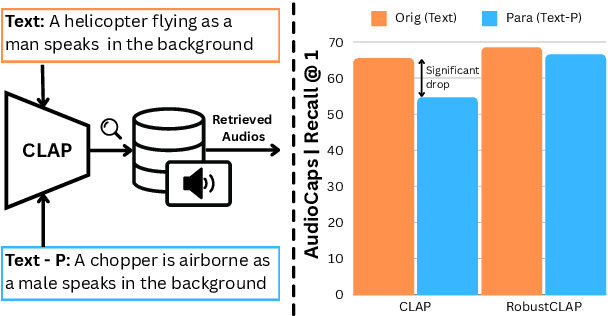
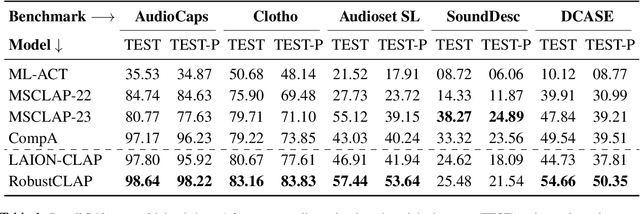
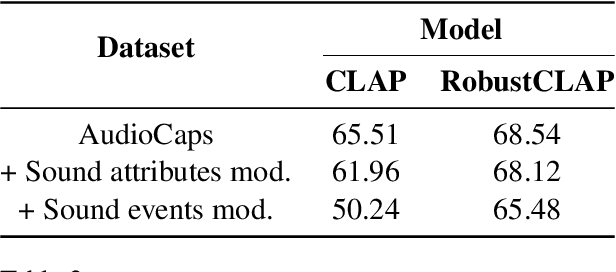
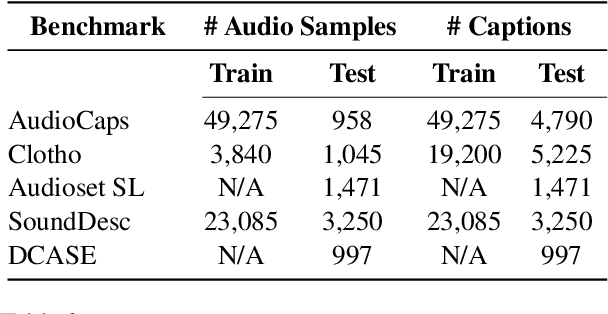
Open-vocabulary audio language models (ALMs), like Contrastive Language Audio Pretraining (CLAP), represent a promising new paradigm for audio-text retrieval using natural language queries. In this paper, for the first time, we perform controlled experiments on various benchmarks to show that existing ALMs struggle to generalize to linguistic variations in textual queries. To address this issue, we propose RobustCLAP, a novel and compute-efficient technique to learn audio-language representations agnostic to linguistic variations. Specifically, we reformulate the contrastive loss used in CLAP architectures by introducing a multi-view contrastive learning objective, where paraphrases are treated as different views of the same audio scene and use this for training. Our proposed approach improves the text-to-audio retrieval performance of CLAP by 0.8%-13% across benchmarks and enhances robustness to linguistic variation.
PAT: Parameter-Free Audio-Text Aligner to Boost Zero-Shot Audio Classification
Oct 19, 2024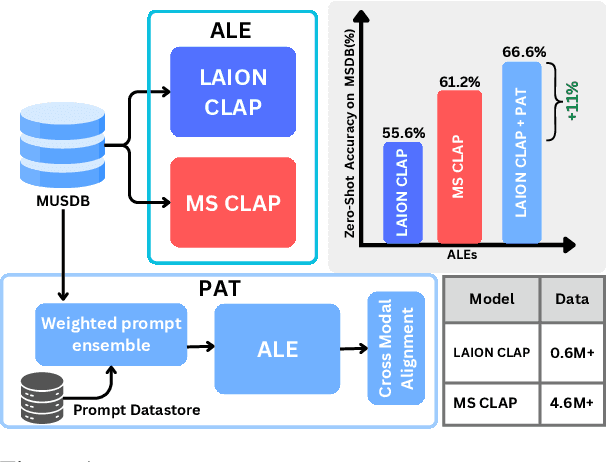
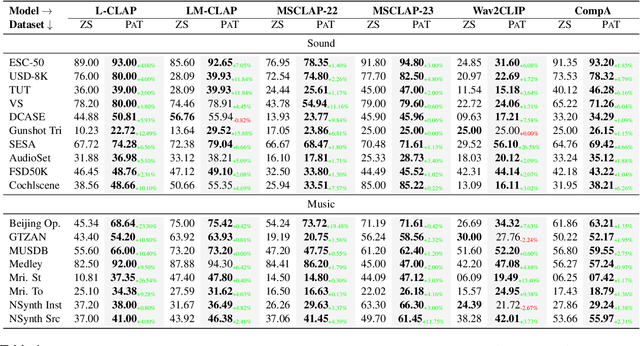
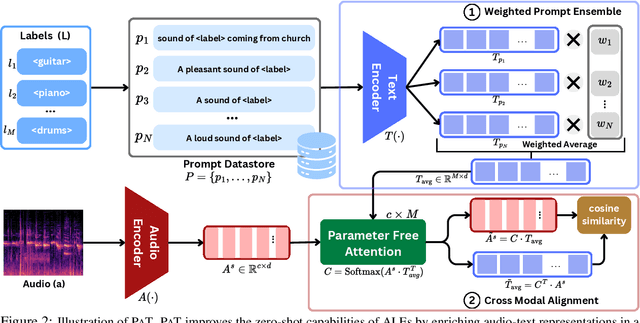

Audio-Language Models (ALMs) have demonstrated remarkable performance in zero-shot audio classification. In this paper, we introduce PAT (Parameter-free Audio-Text aligner), a simple and training-free method aimed at boosting the zero-shot audio classification performance of CLAP-like ALMs. To achieve this, we propose to improve the cross-modal interaction between audio and language modalities by enhancing the representations for both modalities using mutual feedback. Precisely, to enhance textual representations, we propose a prompt ensemble algorithm that automatically selects and combines the most relevant prompts from a datastore with a large pool of handcrafted prompts and weighs them according to their relevance to the audio. On the other hand, to enhance audio representations, we reweigh the frame-level audio features based on the enhanced textual information. Our proposed method does not require any additional modules or parameters and can be used with any existing CLAP-like ALM to improve zero-shot audio classification performance. We experiment across 18 diverse benchmark datasets and 6 ALMs and show that the PAT outperforms vanilla zero-shot evaluation with significant margins of 0.42%-27.0%. Additionally, we demonstrate that PAT maintains robust performance even when input audio is degraded by varying levels of noise. Our code will be open-sourced upon acceptance.
EH-MAM: Easy-to-Hard Masked Acoustic Modeling for Self-Supervised Speech Representation Learning
Oct 17, 2024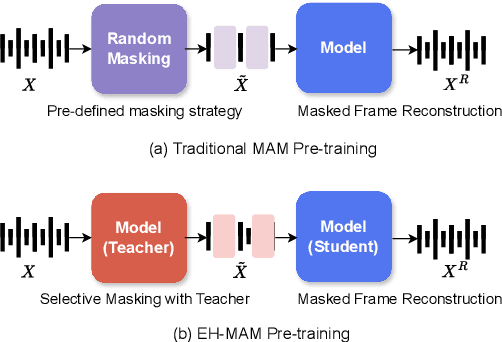
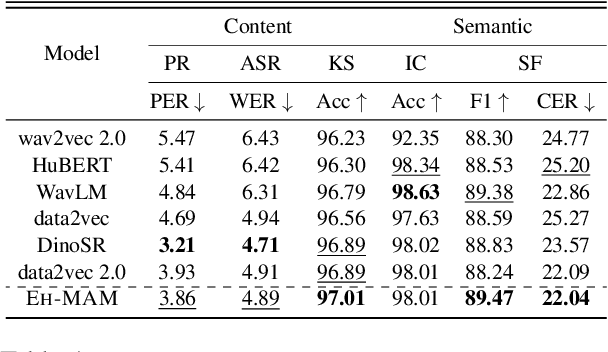
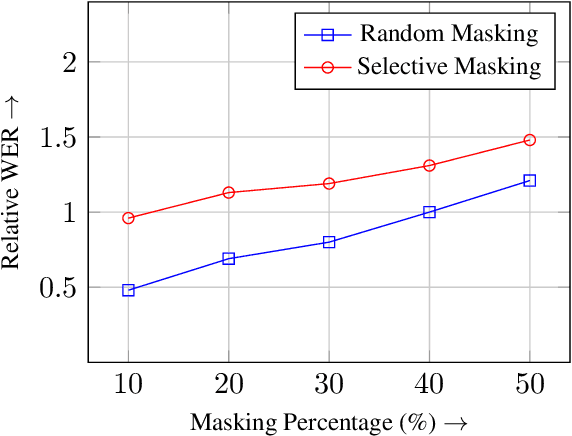

In this paper, we present EH-MAM (Easy-to-Hard adaptive Masked Acoustic Modeling), a novel self-supervised learning approach for speech representation learning. In contrast to the prior methods that use random masking schemes for Masked Acoustic Modeling (MAM), we introduce a novel selective and adaptive masking strategy. Specifically, during SSL training, we progressively introduce harder regions to the model for reconstruction. Our approach automatically selects hard regions and is built on the observation that the reconstruction loss of individual frames in MAM can provide natural signals to judge the difficulty of solving the MAM pre-text task for that frame. To identify these hard regions, we employ a teacher model that first predicts the frame-wise losses and then decides which frames to mask. By learning to create challenging problems, such as identifying harder frames and solving them simultaneously, the model is able to learn more effective representations and thereby acquire a more comprehensive understanding of the speech. Quantitatively, EH-MAM outperforms several state-of-the-art baselines across various low-resource speech recognition and SUPERB benchmarks by 5%-10%. Additionally, we conduct a thorough analysis to show that the regions masked by EH-MAM effectively capture useful context across speech frames.