 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPUR: A Plug-and-Play Framework for Integrating Spatial Audio Understanding and Reasoning into Large Audio-Language Models
Nov 13, 2025



Spatial perception is central to auditory intelligence, enabling accurate understanding of real-world acoustic scenes and advancing human-level perception of the world around us. While recent large audio-language models (LALMs) show strong reasoning over complex audios, most operate on monaural inputs and lack the ability to capture spatial cues such as direction, elevation, and distance. We introduce SPUR, a lightweight, plug-in approach that equips LALMs with spatial perception through minimal architectural changes. SPUR consists of: (i) a First-Order Ambisonics (FOA) encoder that maps (W, X, Y, Z) channels to rotation-aware, listener-centric spatial features, integrated into target LALMs via a multimodal adapter; and (ii) SPUR-Set, a spatial QA dataset combining open-source FOA recordings with controlled simulations, emphasizing relative direction, elevation, distance, and overlap for supervised spatial reasoning. Fine-tuning our model on the SPUR-Set consistently improves spatial QA and multi-speaker attribution while preserving general audio understanding. SPUR provides a simple recipe that transforms monaural LALMs into spatially aware models. Extensive ablations validate the effectiveness of our approach.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
Mar 06, 2025Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities. AF2 leverages (i) a custom CLAP model, (ii) synthetic Audio QA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across over 20 benchmarks. Next, for the first time, we extend audio understanding to long audio segments (30 secs to 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks. Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach. Project Website: https://research.nvidia.com/labs/adlr/AF2/.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
EH-MAM: Easy-to-Hard Masked Acoustic Modeling for Self-Supervised Speech Representation Learning
Oct 17, 2024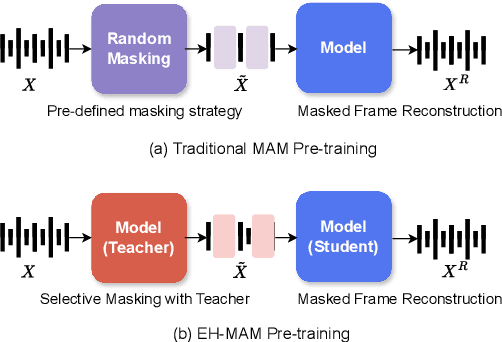
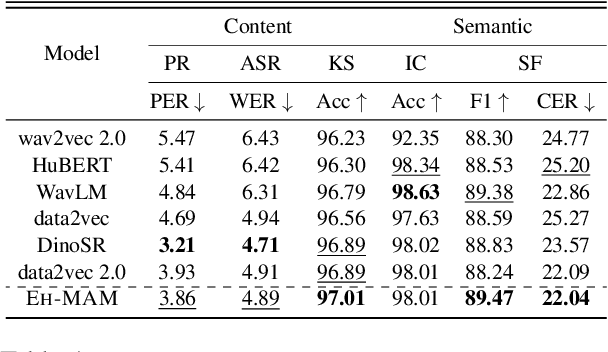
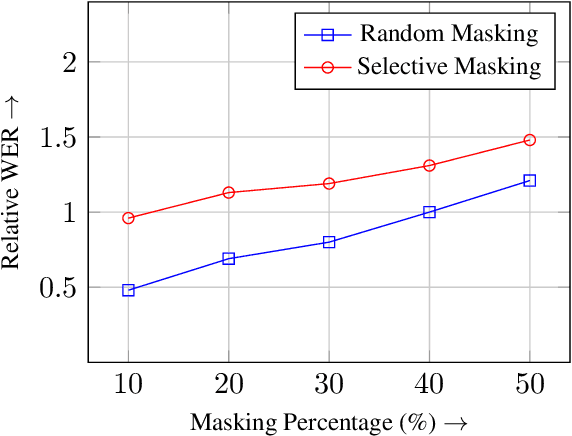

In this paper, we present EH-MAM (Easy-to-Hard adaptive Masked Acoustic Modeling), a novel self-supervised learning approach for speech representation learning. In contrast to the prior methods that use random masking schemes for Masked Acoustic Modeling (MAM), we introduce a novel selective and adaptive masking strategy. Specifically, during SSL training, we progressively introduce harder regions to the model for reconstruction. Our approach automatically selects hard regions and is built on the observation that the reconstruction loss of individual frames in MAM can provide natural signals to judge the difficulty of solving the MAM pre-text task for that frame. To identify these hard regions, we employ a teacher model that first predicts the frame-wise losses and then decides which frames to mask. By learning to create challenging problems, such as identifying harder frames and solving them simultaneously, the model is able to learn more effective representations and thereby acquire a more comprehensive understanding of the speech. Quantitatively, EH-MAM outperforms several state-of-the-art baselines across various low-resource speech recognition and SUPERB benchmarks by 5%-10%. Additionally, we conduct a thorough analysis to show that the regions masked by EH-MAM effectively capture useful context across speech frames.
GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
Jun 17, 2024



Perceiving and understanding non-speech sounds and non-verbal speech is essential to making decisions that help us interact with our surroundings. In this paper, we propose GAMA, a novel General-purpose Large Audio-Language Model (LALM) with Advanced Audio Understanding and Complex Reasoning Abilities. We build GAMA by integrating an LLM with multiple types of audio representations, including features from a custom Audio Q-Former, a multi-layer aggregator that aggregates features from multiple layers of an audio encoder. We fine-tune GAMA on a large-scale audio-language dataset, which augments it with audio understanding capabilities. Next, we propose CompA-R (Instruction-Tuning for Complex Audio Reasoning), a synthetically generated instruction-tuning (IT) dataset with instructions that require the model to perform complex reasoning on the input audio. We instruction-tune GAMA with CompA-R to endow it with complex reasoning abilities, where we further add a soft prompt as input with high-level semantic evidence by leveraging event tags of the input audio. Finally, we also propose CompA-R-test, a human-labeled evaluation dataset for evaluating the capabilities of LALMs on open-ended audio question-answering that requires complex reasoning. Through automated and expert human evaluations, we show that GAMA outperforms all other LALMs in literature on diverse audio understanding tasks by margins of 1%-84%. Further, GAMA IT-ed on CompA-R proves to be superior in its complex reasoning and instruction following capabilities.
ABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions
Jun 06, 2024



We present ABEX, a novel and effective generative data augmentation methodology for low-resource Natural Language Understanding (NLU) tasks. ABEX is based on ABstract-and-EXpand, a novel paradigm for generating diverse forms of an input document -- we first convert a document into its concise, abstract description and then generate new documents based on expanding the resultant abstraction. To learn the task of expanding abstract descriptions, we first train BART on a large-scale synthetic dataset with abstract-document pairs. Next, to generate abstract descriptions for a document, we propose a simple, controllable, and training-free method based on editing AMR graphs. ABEX brings the best of both worlds: by expanding from abstract representations, it preserves the original semantic properties of the documents, like style and meaning, thereby maintaining alignment with the original label and data distribution. At the same time, the fundamental process of elaborating on abstract descriptions facilitates diverse generations. We demonstrate the effectiveness of ABEX on 4 NLU tasks spanning 12 datasets and 4 low-resource settings. ABEX outperforms all our baselines qualitatively with improvements of 0.04% - 38.8%. Qualitatively, ABEX outperforms all prior methods from literature in terms of context and length diversity.
Do Vision-Language Models Understand Compound Nouns?
Mar 30, 2024



Open-vocabulary vision-language models (VLMs) like CLIP, trained using contrastive loss, have emerged as a promising new paradigm for text-to-image retrieval. However, do VLMs understand compound nouns (CNs) (e.g., lab coat) as well as they understand nouns (e.g., lab)? We curate Compun, a novel benchmark with 400 unique and commonly used CNs, to evaluate the effectiveness of VLMs in interpreting CNs. The Compun benchmark challenges a VLM for text-to-image retrieval where, given a text prompt with a CN, the task is to select the correct image that shows the CN among a pair of distractor images that show the constituent nouns that make up the CN. Next, we perform an in-depth analysis to highlight CLIPs' limited understanding of certain types of CNs. Finally, we present an alternative framework that moves beyond hand-written templates for text prompts widely used by CLIP-like models. We employ a Large Language Model to generate multiple diverse captions that include the CN as an object in the scene described by the caption. Our proposed method improves CN understanding of CLIP by 8.25% on Compun. Code and benchmark are available at: https://github.com/sonalkum/Compun
DALE: Generative Data Augmentation for Low-Resource Legal NLP
Oct 24, 2023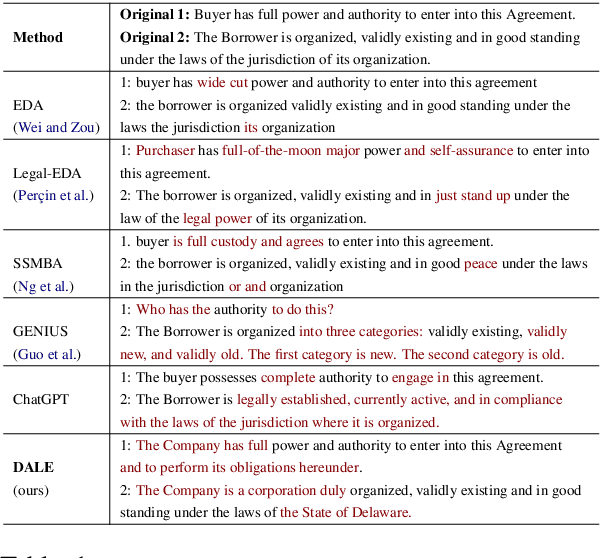

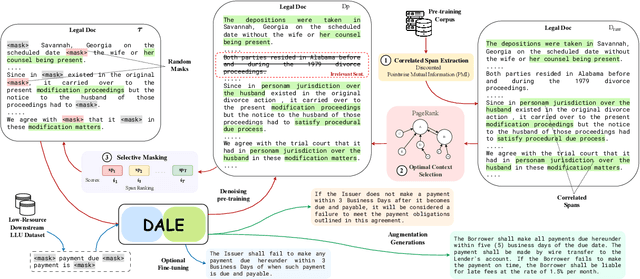

We present DALE, a novel and effective generative Data Augmentation framework for low-resource LEgal NLP. DALE addresses the challenges existing frameworks pose in generating effective data augmentations of legal documents - legal language, with its specialized vocabulary and complex semantics, morphology, and syntax, does not benefit from data augmentations that merely rephrase the source sentence. To address this, DALE, built on an Encoder-Decoder Language Model, is pre-trained on a novel unsupervised text denoising objective based on selective masking - our masking strategy exploits the domain-specific language characteristics of templatized legal documents to mask collocated spans of text. Denoising these spans helps DALE acquire knowledge about legal concepts, principles, and language usage. Consequently, it develops the ability to generate coherent and diverse augmentations with novel contexts. Finally, DALE performs conditional generation to generate synthetic augmentations for low-resource Legal NLP tasks. We demonstrate the effectiveness of DALE on 13 datasets spanning 6 tasks and 4 low-resource settings. DALE outperforms all our baselines, including LLMs, qualitatively and quantitatively, with improvements of 1%-50%.
Speech Toxicity Analysis: A New Spoken Language Processing Task
Nov 06, 2021
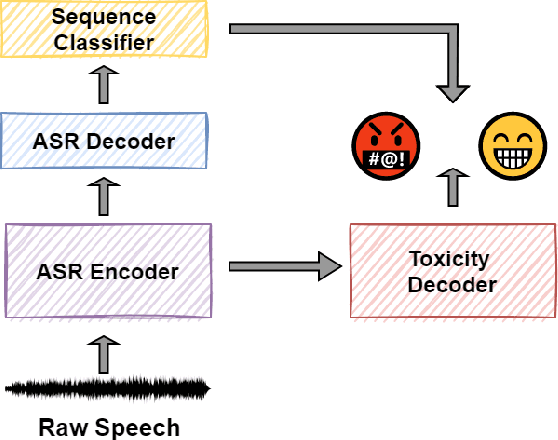

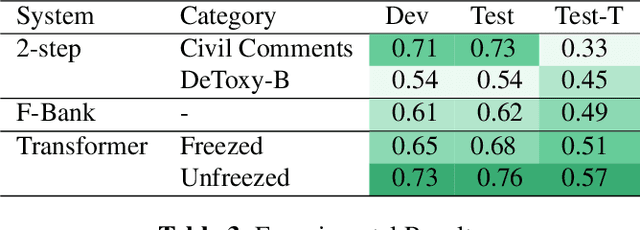
Toxic speech, also known as hate speech, is regarded as one of the crucial issues plaguing online social media today. Most recent work on toxic speech detection is constrained to the modality of text with no existing work on toxicity detection from spoken utterances. In this paper, we propose a new Spoken Language Processing task of detecting toxicity from spoken speech. We introduce DeToxy, the first publicly available toxicity annotated dataset for English speech, sourced from various openly available speech databases, consisting of over 2 million utterances. Finally, we also provide analysis on how a spoken speech corpus annotated for toxicity can help facilitate the development of E2E models which better capture various prosodic cues in speech, thereby boosting toxicity classification on spoken utterances.