 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoAVU: Egocentric Audio-Visual Understanding
Feb 05, 2026Understanding egocentric videos plays a vital role for embodied intelligence. Recent multi-modal large language models (MLLMs) can accept both visual and audio inputs. However, due to the challenge of obtaining text labels with coherent joint-modality information, whether MLLMs can jointly understand both modalities in egocentric videos remains under-explored. To address this problem, we introduce EgoAVU, a scalable data engine to automatically generate egocentric audio-visual narrations, questions, and answers. EgoAVU enriches human narrations with multimodal context and generates audio-visual narrations through cross-modal correlation modeling. Token-based video filtering and modular, graph-based curation ensure both data diversity and quality. Leveraging EgoAVU, we construct EgoAVU-Instruct, a large-scale training dataset of 3M samples, and EgoAVU-Bench, a manually verified evaluation split covering diverse tasks. EgoAVU-Bench clearly reveals the limitations of existing MLLMs: they bias heavily toward visual signals, often neglecting audio cues or failing to correspond audio with the visual source. Finetuning MLLMs on EgoAVU-Instruct effectively addresses this issue, enabling up to 113% performance improvement on EgoAVU-Bench. Such benefits also transfer to other benchmarks such as EgoTempo and EgoIllusion, achieving up to 28% relative performance gain. Code will be released to the community.
TSPE: Task-Specific Prompt Ensemble for Improved Zero-Shot Audio Classification
Dec 31, 2024Audio-language models (ALMs) excel in zero-shot audio classification, a task where models classify previously unseen audio clips at test time by leveraging descriptive natural language prompts. We introduce TSPE (Task-Specific Prompt Ensemble), a simple, training-free hard prompting method that boosts ALEs' zero-shot performance by customizing prompts for diverse audio classification tasks. Rather than using generic template-based prompts like "Sound of a car" we generate context-rich prompts, such as "Sound of a car coming from a tunnel". Specifically, we leverage label information to identify suitable sound attributes, such as "loud" and "feeble", and appropriate sound sources, such as "tunnel" and "street" and incorporate this information into the prompts used by Audio-Language Models (ALMs) for audio classification. Further, to enhance audio-text alignment, we perform prompt ensemble across TSPE-generated task-specific prompts. When evaluated on 12 diverse audio classification datasets, TSPE improves performance across ALMs by showing an absolute improvement of 1.23-16.36% over vanilla zero-shot evaluation.
HALLUCINOGEN: A Benchmark for Evaluating Object Hallucination in Large Visual-Language Models
Dec 29, 2024


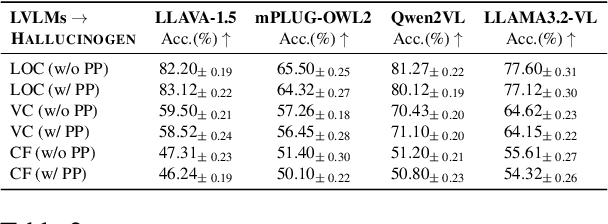
Large Vision-Language Models (LVLMs) have demonstrated remarkable performance in performing complex multimodal tasks. However, they are still plagued by object hallucination: the misidentification or misclassification of objects present in images. To this end, we propose HALLUCINOGEN, a novel visual question answering (VQA) object hallucination attack benchmark that utilizes diverse contextual reasoning prompts to evaluate object hallucination in state-of-the-art LVLMs. We design a series of contextual reasoning hallucination prompts to evaluate LVLMs' ability to accurately identify objects in a target image while asking them to perform diverse visual-language tasks such as identifying, locating or performing visual reasoning around specific objects. Further, we extend our benchmark to high-stakes medical applications and introduce MED-HALLUCINOGEN, hallucination attacks tailored to the biomedical domain, and evaluate the hallucination performance of LVLMs on medical images, a critical area where precision is crucial. Finally, we conduct extensive evaluations of eight LVLMs and two hallucination mitigation strategies across multiple datasets to show that current generic and medical LVLMs remain susceptible to hallucination attacks.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Oct 24, 2024



The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Do Audio-Language Models Understand Linguistic Variations?
Oct 21, 2024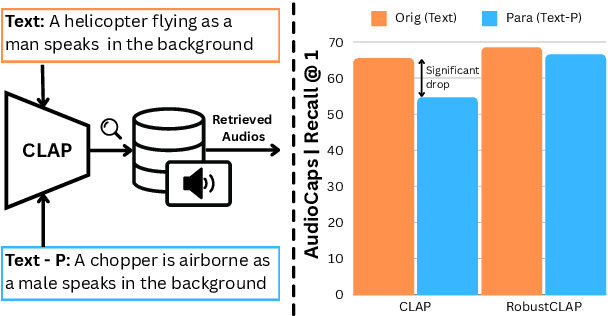
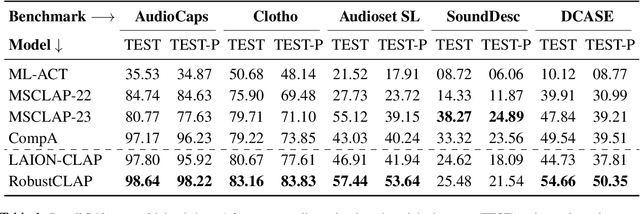
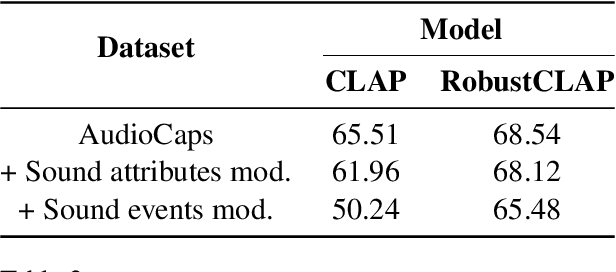
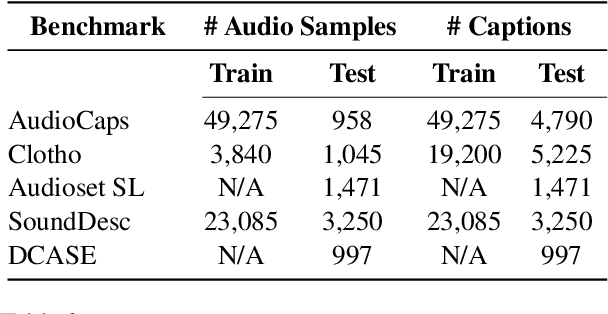
Open-vocabulary audio language models (ALMs), like Contrastive Language Audio Pretraining (CLAP), represent a promising new paradigm for audio-text retrieval using natural language queries. In this paper, for the first time, we perform controlled experiments on various benchmarks to show that existing ALMs struggle to generalize to linguistic variations in textual queries. To address this issue, we propose RobustCLAP, a novel and compute-efficient technique to learn audio-language representations agnostic to linguistic variations. Specifically, we reformulate the contrastive loss used in CLAP architectures by introducing a multi-view contrastive learning objective, where paraphrases are treated as different views of the same audio scene and use this for training. Our proposed approach improves the text-to-audio retrieval performance of CLAP by 0.8%-13% across benchmarks and enhances robustness to linguistic variation.
PAT: Parameter-Free Audio-Text Aligner to Boost Zero-Shot Audio Classification
Oct 19, 2024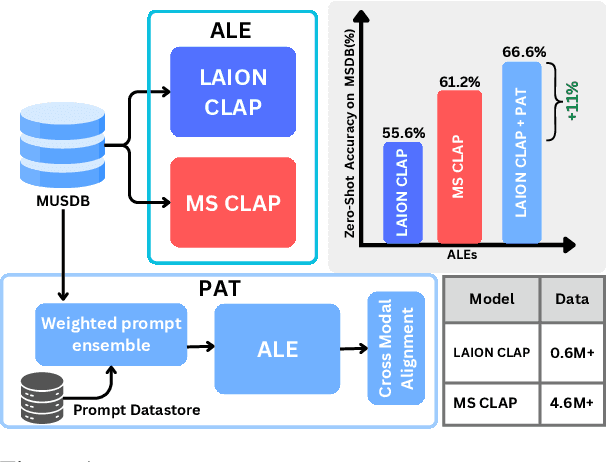
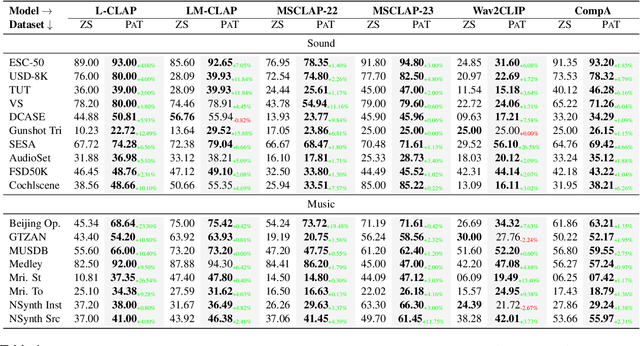
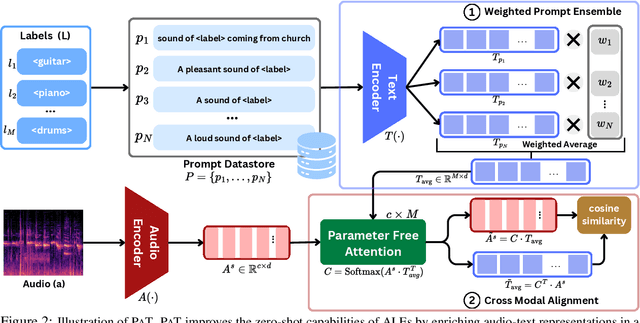

Audio-Language Models (ALMs) have demonstrated remarkable performance in zero-shot audio classification. In this paper, we introduce PAT (Parameter-free Audio-Text aligner), a simple and training-free method aimed at boosting the zero-shot audio classification performance of CLAP-like ALMs. To achieve this, we propose to improve the cross-modal interaction between audio and language modalities by enhancing the representations for both modalities using mutual feedback. Precisely, to enhance textual representations, we propose a prompt ensemble algorithm that automatically selects and combines the most relevant prompts from a datastore with a large pool of handcrafted prompts and weighs them according to their relevance to the audio. On the other hand, to enhance audio representations, we reweigh the frame-level audio features based on the enhanced textual information. Our proposed method does not require any additional modules or parameters and can be used with any existing CLAP-like ALM to improve zero-shot audio classification performance. We experiment across 18 diverse benchmark datasets and 6 ALMs and show that the PAT outperforms vanilla zero-shot evaluation with significant margins of 0.42%-27.0%. Additionally, we demonstrate that PAT maintains robust performance even when input audio is degraded by varying levels of noise. Our code will be open-sourced upon acceptance.
EH-MAM: Easy-to-Hard Masked Acoustic Modeling for Self-Supervised Speech Representation Learning
Oct 17, 2024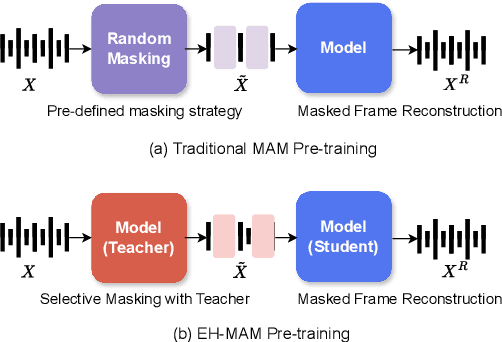
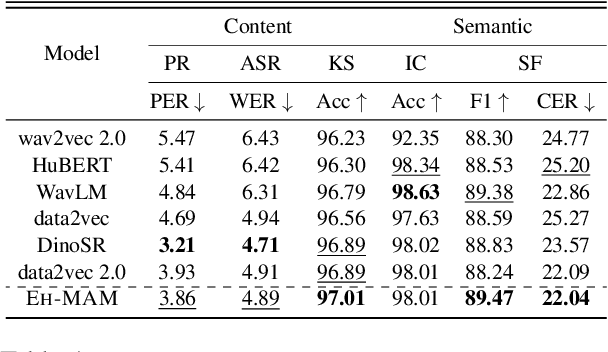
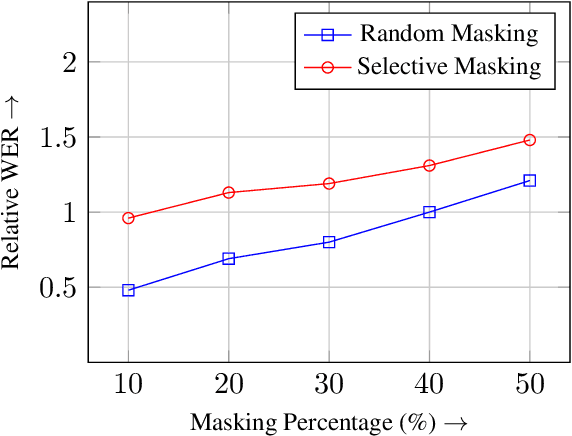

In this paper, we present EH-MAM (Easy-to-Hard adaptive Masked Acoustic Modeling), a novel self-supervised learning approach for speech representation learning. In contrast to the prior methods that use random masking schemes for Masked Acoustic Modeling (MAM), we introduce a novel selective and adaptive masking strategy. Specifically, during SSL training, we progressively introduce harder regions to the model for reconstruction. Our approach automatically selects hard regions and is built on the observation that the reconstruction loss of individual frames in MAM can provide natural signals to judge the difficulty of solving the MAM pre-text task for that frame. To identify these hard regions, we employ a teacher model that first predicts the frame-wise losses and then decides which frames to mask. By learning to create challenging problems, such as identifying harder frames and solving them simultaneously, the model is able to learn more effective representations and thereby acquire a more comprehensive understanding of the speech. Quantitatively, EH-MAM outperforms several state-of-the-art baselines across various low-resource speech recognition and SUPERB benchmarks by 5%-10%. Additionally, we conduct a thorough analysis to show that the regions masked by EH-MAM effectively capture useful context across speech frames.
GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities
Jun 17, 2024



Perceiving and understanding non-speech sounds and non-verbal speech is essential to making decisions that help us interact with our surroundings. In this paper, we propose GAMA, a novel General-purpose Large Audio-Language Model (LALM) with Advanced Audio Understanding and Complex Reasoning Abilities. We build GAMA by integrating an LLM with multiple types of audio representations, including features from a custom Audio Q-Former, a multi-layer aggregator that aggregates features from multiple layers of an audio encoder. We fine-tune GAMA on a large-scale audio-language dataset, which augments it with audio understanding capabilities. Next, we propose CompA-R (Instruction-Tuning for Complex Audio Reasoning), a synthetically generated instruction-tuning (IT) dataset with instructions that require the model to perform complex reasoning on the input audio. We instruction-tune GAMA with CompA-R to endow it with complex reasoning abilities, where we further add a soft prompt as input with high-level semantic evidence by leveraging event tags of the input audio. Finally, we also propose CompA-R-test, a human-labeled evaluation dataset for evaluating the capabilities of LALMs on open-ended audio question-answering that requires complex reasoning. Through automated and expert human evaluations, we show that GAMA outperforms all other LALMs in literature on diverse audio understanding tasks by margins of 1%-84%. Further, GAMA IT-ed on CompA-R proves to be superior in its complex reasoning and instruction following capabilities.
LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition
Jun 06, 2024



Visual cues, like lip motion, have been shown to improve the performance of Automatic Speech Recognition (ASR) systems in noisy environments. We propose LipGER (Lip Motion aided Generative Error Correction), a novel framework for leveraging visual cues for noise-robust ASR. Instead of learning the cross-modal correlation between the audio and visual modalities, we make an LLM learn the task of visually-conditioned (generative) ASR error correction. Specifically, we instruct an LLM to predict the transcription from the N-best hypotheses generated using ASR beam-search. This is further conditioned on lip motions. This approach addresses key challenges in traditional AVSR learning, such as the lack of large-scale paired datasets and difficulties in adapting to new domains. We experiment on 4 datasets in various settings and show that LipGER improves the Word Error Rate in the range of 1.1%-49.2%. We also release LipHyp, a large-scale dataset with hypothesis-transcription pairs that is additionally equipped with lip motion cues to promote further research in this space
Stable Distillation: Regularizing Continued Pre-training for Low-Resource Automatic Speech Recognition
Dec 20, 2023



Continued self-supervised (SSL) pre-training for adapting existing SSL models to the target domain has shown to be extremely effective for low-resource Automatic Speech Recognition (ASR). This paper proposes Stable Distillation, a simple and novel approach for SSL-based continued pre-training that boosts ASR performance in the target domain where both labeled and unlabeled data are limited. Stable Distillation employs self-distillation as regularization for continued pre-training, alleviating the over-fitting issue, a common problem continued pre-training faces when the source and target domains differ. Specifically, first, we perform vanilla continued pre-training on an initial SSL pre-trained model on the target domain ASR dataset and call it the teacher. Next, we take the same initial pre-trained model as a student to perform continued pre-training while enforcing its hidden representations to be close to that of the teacher (via MSE loss). This student is then used for downstream ASR fine-tuning on the target dataset. In practice, Stable Distillation outperforms all our baselines by 0.8 - 7 WER when evaluated in various experimental settings.