 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusDom: Combining In-Domain and Out-of-Domain Knowledge for Continuous Self-Supervised Learning
Paper and Code
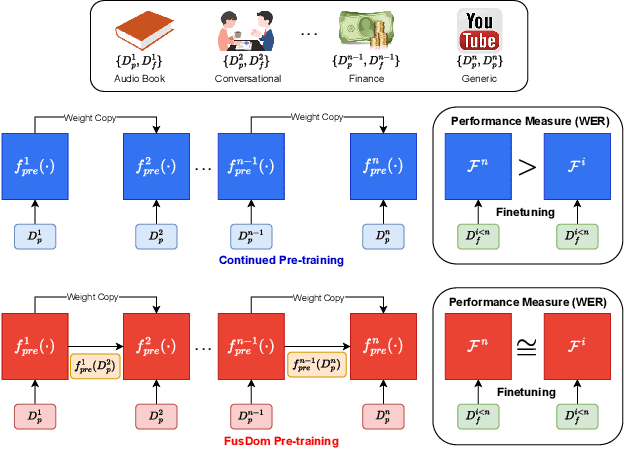


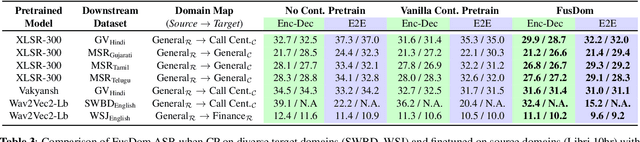
Continued pre-training (CP) offers multiple advantages, like target domain adaptation and the potential to exploit the continuous stream of unlabeled data available online. However, continued pre-training on out-of-domain distributions often leads to catastrophic forgetting of previously acquired knowledge, leading to sub-optimal ASR performance. This paper presents FusDom, a simple and novel methodology for SSL-based continued pre-training. FusDom learns speech representations that are robust and adaptive yet not forgetful of concepts seen in the past. Instead of solving the SSL pre-text task on the output representations of a single model, FusDom leverages two identical pre-trained SSL models, a teacher and a student, with a modified pre-training head to solve the CP SSL pre-text task. This head employs a cross-attention mechanism between the representations of both models while only the student receives gradient updates and the teacher does not. Finally, the student is fine-tuned for ASR. In practice, FusDom outperforms all our baselines across settings significantly, with WER improvements in the range of 0.2 WER - 7.3 WER in the target domain while retaining the performance in the earlier domain.