 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Robust and Scalable Multilingual ASR for Indian Languages
Nov 19, 2025This paper describes the systems developed by SPRING Lab, Indian Institute of Technology Madras, for the ASRU MADASR 2.0 challenge. The systems developed focuses on adapting ASR systems to improve in predicting the language and dialect of the utterance among 8 languages across 33 dialects. We participated in Track 1 and Track 2, which restricts the use of additional data and develop from-the-scratch multilingual systems. We presented a novel training approach using Multi-Decoder architecture with phonemic Common Label Set (CLS) as intermediate representation. It improved the performance over the baseline (in the CLS space). We also discuss various methods used to retain the gain obtained in the phonemic space while converting them back to the corresponding grapheme representations. Our systems beat the baseline in 3 languages (Track 2) in terms of WER/CER and achieved the highest language ID and dialect ID accuracy among all participating teams (Track 2).
EZ-VC: Easy Zero-shot Any-to-Any Voice Conversion
May 22, 2025Voice Conversion research in recent times has increasingly focused on improving the zero-shot capabilities of existing methods. Despite remarkable advancements, current architectures still tend to struggle in zero-shot cross-lingual settings. They are also often unable to generalize for speakers of unseen languages and accents. In this paper, we adopt a simple yet effective approach that combines discrete speech representations from self-supervised models with a non-autoregressive Diffusion-Transformer based conditional flow matching speech decoder. We show that this architecture allows us to train a voice-conversion model in a purely textless, self-supervised fashion. Our technique works without requiring multiple encoders to disentangle speech features. Our model also manages to excel in zero-shot cross-lingual settings even for unseen languages.
FusDom: Combining In-Domain and Out-of-Domain Knowledge for Continuous Self-Supervised Learning
Dec 20, 2023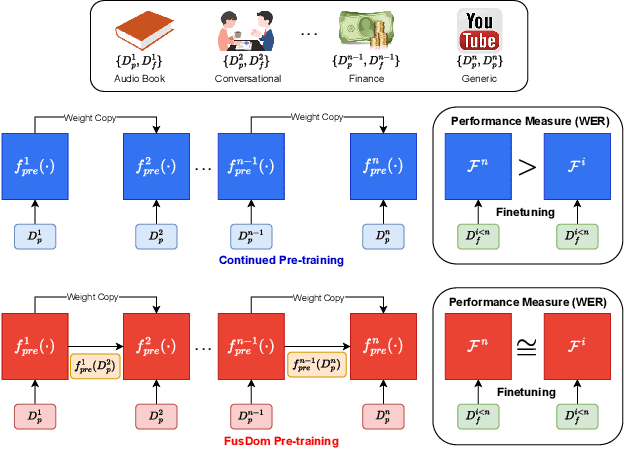


Continued pre-training (CP) offers multiple advantages, like target domain adaptation and the potential to exploit the continuous stream of unlabeled data available online. However, continued pre-training on out-of-domain distributions often leads to catastrophic forgetting of previously acquired knowledge, leading to sub-optimal ASR performance. This paper presents FusDom, a simple and novel methodology for SSL-based continued pre-training. FusDom learns speech representations that are robust and adaptive yet not forgetful of concepts seen in the past. Instead of solving the SSL pre-text task on the output representations of a single model, FusDom leverages two identical pre-trained SSL models, a teacher and a student, with a modified pre-training head to solve the CP SSL pre-text task. This head employs a cross-attention mechanism between the representations of both models while only the student receives gradient updates and the teacher does not. Finally, the student is fine-tuned for ASR. In practice, FusDom outperforms all our baselines across settings significantly, with WER improvements in the range of 0.2 WER - 7.3 WER in the target domain while retaining the performance in the earlier domain.
Stable Distillation: Regularizing Continued Pre-training for Low-Resource Automatic Speech Recognition
Dec 20, 2023



Continued self-supervised (SSL) pre-training for adapting existing SSL models to the target domain has shown to be extremely effective for low-resource Automatic Speech Recognition (ASR). This paper proposes Stable Distillation, a simple and novel approach for SSL-based continued pre-training that boosts ASR performance in the target domain where both labeled and unlabeled data are limited. Stable Distillation employs self-distillation as regularization for continued pre-training, alleviating the over-fitting issue, a common problem continued pre-training faces when the source and target domains differ. Specifically, first, we perform vanilla continued pre-training on an initial SSL pre-trained model on the target domain ASR dataset and call it the teacher. Next, we take the same initial pre-trained model as a student to perform continued pre-training while enforcing its hidden representations to be close to that of the teacher (via MSE loss). This student is then used for downstream ASR fine-tuning on the target dataset. In practice, Stable Distillation outperforms all our baselines by 0.8 - 7 WER when evaluated in various experimental settings.
The Tag-Team Approach: Leveraging CLS and Language Tagging for Enhancing Multilingual ASR
May 31, 2023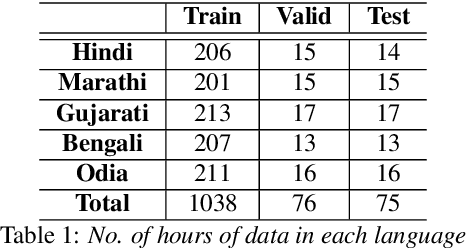

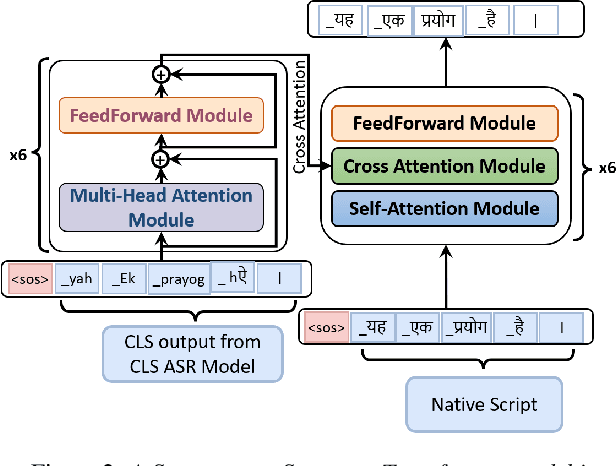

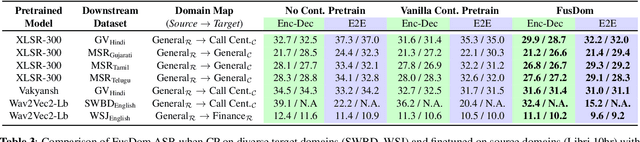
Building a multilingual Automated Speech Recognition (ASR) system in a linguistically diverse country like India can be a challenging task due to the differences in scripts and the limited availability of speech data. This problem can be solved by exploiting the fact that many of these languages are phonetically similar. These languages can be converted into a Common Label Set (CLS) by mapping similar sounds to common labels. In this paper, new approaches are explored and compared to improve the performance of CLS based multilingual ASR model. Specific language information is infused in the ASR model by giving Language ID or using CLS to Native script converter on top of the CLS Multilingual model. These methods give a significant improvement in Word Error Rate (WER) compared to the CLS baseline. These methods are further tried on out-of-distribution data to check their robustness.
UNFUSED: UNsupervised Finetuning Using SElf supervised Distillation
Mar 10, 2023In this paper, we introduce UnFuSeD, a novel approach to leverage self-supervised learning and reduce the need for large amounts of labeled data for audio classification. Unlike prior works, which directly fine-tune a self-supervised pre-trained encoder on a target dataset, we use the encoder to generate pseudo-labels for unsupervised fine-tuning before the actual fine-tuning step. We first train an encoder using a novel self-supervised learning algorithm (SSL) on an unlabeled audio dataset. Then, we use that encoder to generate pseudo-labels on our target task dataset via clustering the extracted representations. These pseudo-labels are then used to guide self-distillation on a randomly initialized model, which we call unsupervised fine-tuning. Finally, the resultant encoder is then fine-tuned on our target task dataset. Through UnFuSeD, we propose the first system that moves away from generic SSL paradigms in literature, which pre-train and fine-tune the same encoder, and present a novel self-distillation-based system to leverage SSL pre-training for low-resource audio classification. In practice, UnFuSeD achieves state-of-the-art results on the LAPE Benchmark, significantly outperforming all our baselines. Additionally, UnFuSeD allows us to achieve this at a 40% reduction in the number of parameters over the previous state-of-the-art system. We make all our codes publicly available.
Channel-Aware Pretraining of Joint Encoder-Decoder Self-Supervised Model for Telephonic-Speech ASR
Nov 03, 2022



This paper proposes a novel technique to obtain better downstream ASR performance from a joint encoder-decoder self-supervised model when trained with speech pooled from two different channels (narrow and wide band). The joint encoder-decoder self-supervised model extends the HuBERT model with a Transformer decoder. HuBERT performs clustering of features and predicts the class of every input frame. In simple pooling, which is our baseline, there is no way to identify the channel information. To incorporate channel information, we have proposed non-overlapping cluster IDs for speech from different channels. Our method gives a relative improvement of ~ 5% over the joint encoder-decoder self-supervised model built with simple pooling of data, which serves as our baseline.
MAST: Multiscale Audio Spectrogram Transformers
Nov 02, 2022We present Multiscale Audio Spectrogram Transformer (MAST) for audio classification, which brings the concept of multiscale feature hierarchies to the Audio Spectrogram Transformer (AST). Given an input audio spectrogram we first patchify and project it into an initial temporal resolution and embedding dimension, post which the multiple stages in MAST progressively expand the embedding dimension while reducing the temporal resolution of the input. We use a pyramid structure that allows early layers of MAST operating at a high temporal resolution but low embedding space to model simple low-level acoustic information and deeper temporally coarse layers to model high-level acoustic information with high-dimensional embeddings. We also extend our approach to present a new Self-Supervised Learning (SSL) method called SS-MAST, which calculates a symmetric contrastive loss between latent representations from a student and a teacher encoder. In practice, MAST significantly outperforms AST by an average accuracy of 3.4% across 8 speech and non-speech tasks from the LAPE Benchmark. Moreover, SS-MAST achieves an absolute average improvement of 2.6% over SSAST for both AST and MAST encoders. We make all our codes available on GitHub at the time of publication.
data2vec-aqc: Search for the right Teaching Assistant in the Teacher-Student training setup
Nov 02, 2022


In this paper, we propose a new Self-Supervised Learning (SSL) algorithm called data2vec-aqc, for speech representation learning from unlabeled speech data. Our goal is to improve SSL for speech in domains where both unlabeled and labeled data are limited. Building on the recently introduced data2vec, we introduce additional modules to the data2vec framework that leverage the benefit of data augmentations, quantized representations, and clustering. The interaction between these modules helps solve the cross-contrastive loss as an additional self-supervised objective. data2vec-aqc achieves up to 14.1% and 20.9% relative WER improvement over the existing state-of-the-art data2vec system on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. Our proposed model also achieves up to 17.8% relative WER improvement over the baseline data2vec when fine-tuned on Switchboard data.
SLICER: Learning universal audio representations using low-resource self-supervised pre-training
Nov 02, 2022We present a new Self-Supervised Learning (SSL) approach to pre-train encoders on unlabeled audio data that reduces the need for large amounts of labeled data for audio and speech classification. Our primary aim is to learn audio representations that can generalize across a large variety of speech and non-speech tasks in a low-resource un-labeled audio pre-training setting. Inspired by the recent success of clustering and contrasting learning paradigms for SSL-based speech representation learning, we propose SLICER (Symmetrical Learning of Instance and Cluster-level Efficient Representations), which brings together the best of both clustering and contrasting learning paradigms. We use a symmetric loss between latent representations from student and teacher encoders and simultaneously solve instance and cluster-level contrastive learning tasks. We obtain cluster representations online by just projecting the input spectrogram into an output subspace with dimensions equal to the number of clusters. In addition, we propose a novel mel-spectrogram augmentation procedure, k-mix, based on mixup, which does not require labels and aids unsupervised representation learning for audio. Overall, SLICER achieves state-of-the-art results on the LAPE Benchmark \cite{9868132}, significantly outperforming DeLoRes-M and other prior approaches, which are pre-trained on $10\times$ larger of unsupervised data. We will make all our codes available on GitHub.