 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALTTS: Leveraging Self-Supervised Speech Representations for improved Text-to-Speech Synthesis
Aug 02, 2023

While FastSpeech2 aims to integrate aspects of speech such as pitch, energy, and duration as conditional inputs, it still leaves scope for richer representations. As a part of this work, we leverage representations from various Self-Supervised Learning (SSL) models to enhance the quality of the synthesized speech. In particular, we pass the FastSpeech2 encoder's length-regulated outputs through a series of encoder layers with the objective of reconstructing the SSL representations. In the SALTTS-parallel implementation, the representations from this second encoder are used for an auxiliary reconstruction loss with the SSL features. The SALTTS-cascade implementation, however, passes these representations through the decoder in addition to having the reconstruction loss. The richness of speech characteristics from the SSL features reflects in the output speech quality, with the objective and subjective evaluation measures of the proposed approach outperforming the baseline FastSpeech2.
data2vec-aqc: Search for the right Teaching Assistant in the Teacher-Student training setup
Nov 02, 2022


In this paper, we propose a new Self-Supervised Learning (SSL) algorithm called data2vec-aqc, for speech representation learning from unlabeled speech data. Our goal is to improve SSL for speech in domains where both unlabeled and labeled data are limited. Building on the recently introduced data2vec, we introduce additional modules to the data2vec framework that leverage the benefit of data augmentations, quantized representations, and clustering. The interaction between these modules helps solve the cross-contrastive loss as an additional self-supervised objective. data2vec-aqc achieves up to 14.1% and 20.9% relative WER improvement over the existing state-of-the-art data2vec system on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. Our proposed model also achieves up to 17.8% relative WER improvement over the baseline data2vec when fine-tuned on Switchboard data.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
CCC-wav2vec 2.0: Clustering aided Cross Contrastive Self-supervised learning of speech representations
Oct 05, 2022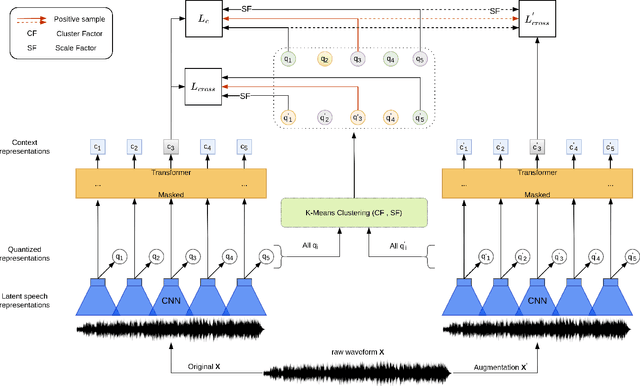
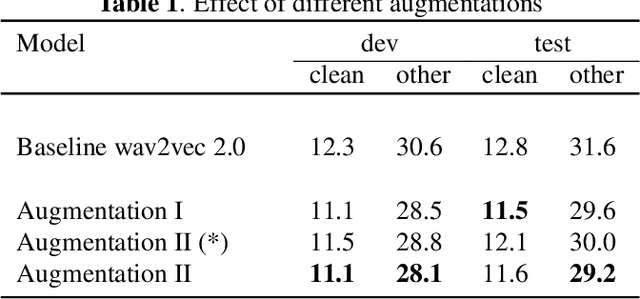
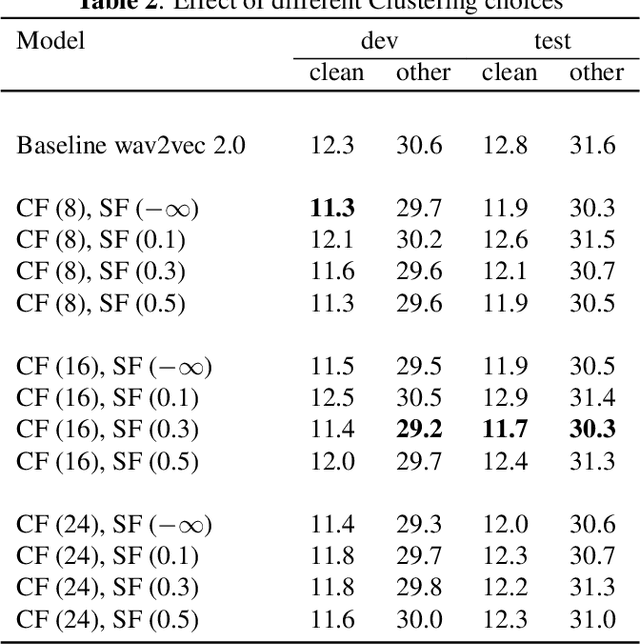
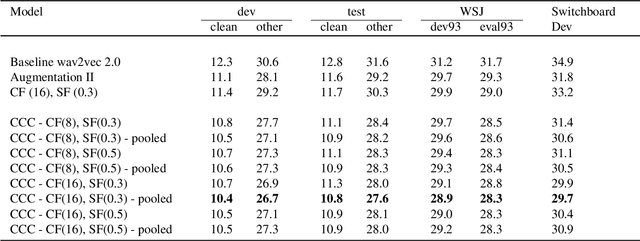
While Self-Supervised Learning has helped reap the benefit of the scale from the available unlabeled data, the learning paradigms are continuously being bettered. We present a new pre-training strategy named ccc-wav2vec 2.0, which uses clustering and an augmentation-based cross-contrastive loss as its self-supervised objective. Through the clustering module, we scale down the influence of those negative examples that are highly similar to the positive. The Cross-Contrastive loss is computed between the encoder output of the original sample and the quantizer output of its augmentation and vice-versa, bringing robustness to the pre-training strategy. ccc-wav2vec 2.0 achieves up to 15.6% and 12.7% relative WER improvement over the baseline wav2vec 2.0 on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. The proposed method also achieves up to 14.9% relative WER improvement over the baseline wav2vec 2.0 when fine-tuned on Switchboard data. We make all our codes publicly available on GitHub.